Rizvi Shahriyar Masud, Rahman Ab Al-Hadi Ab, Sheikh Usman Ullah, Fuad Kazi Ahmed Asif, Shehzad Hafiz Muhammad Faisal
VeCAD Research Laboratory, School of Electrical Engineering, Universiti Teknologi Malaysia, Johor Bahru, 81310 Johor Malaysia.
School of Electrical Engineering and Computer Science, Oregon State University, Corvallis, OR 97331 USA.
Appl Intell (Dordr). 2023;53(4):4499-4523. doi: 10.1007/s10489-022-03756-1. Epub 2022 Jun 11.
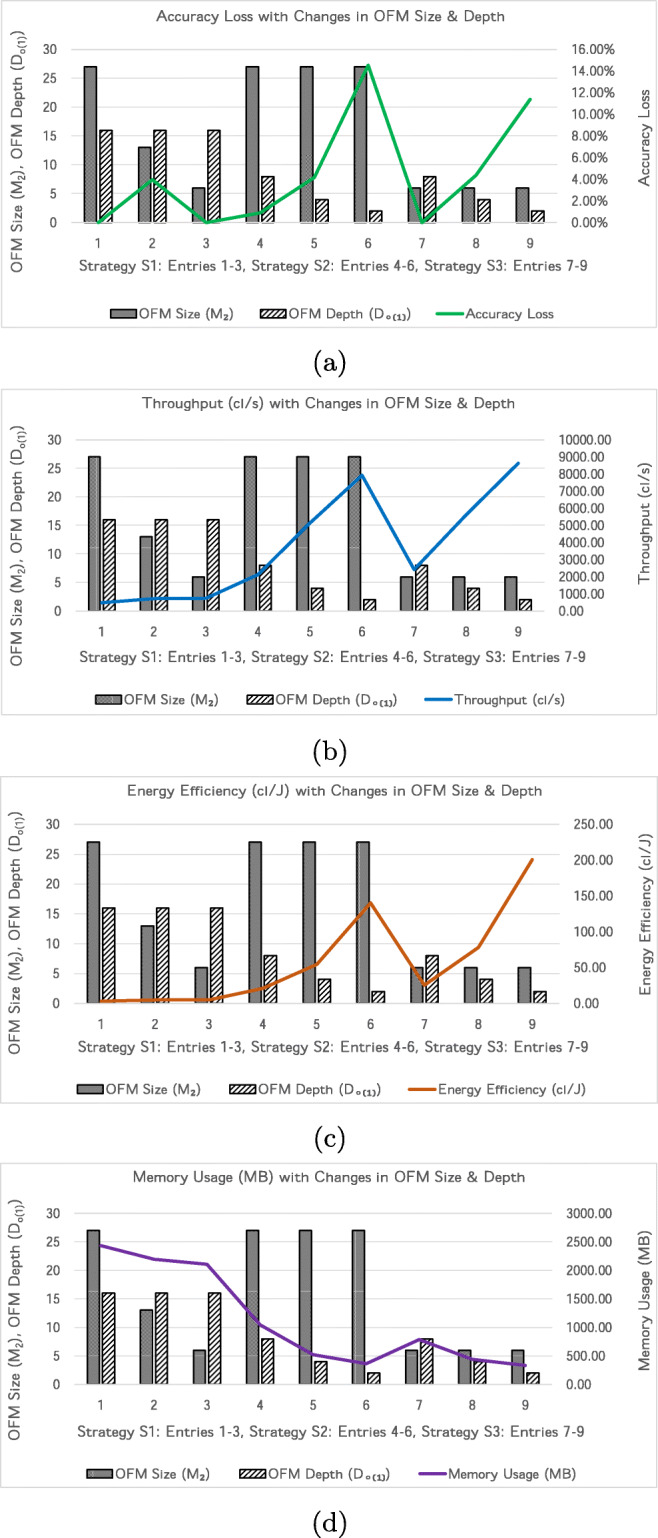
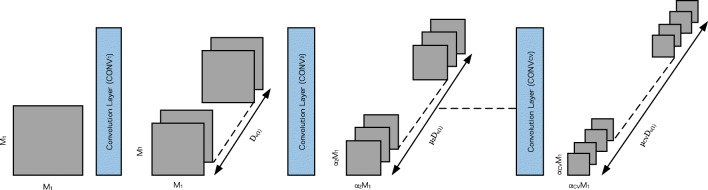
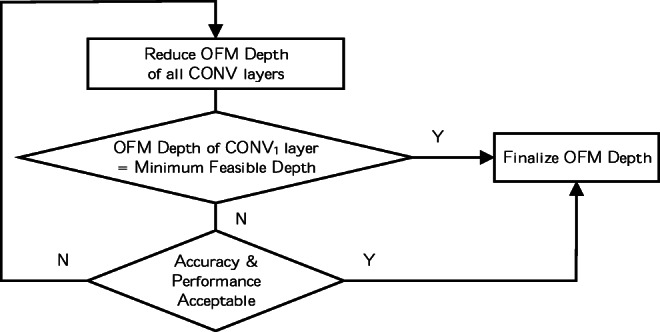
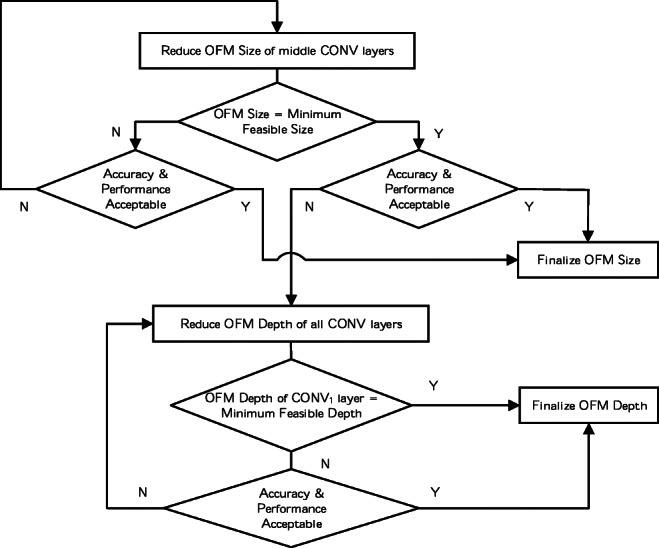
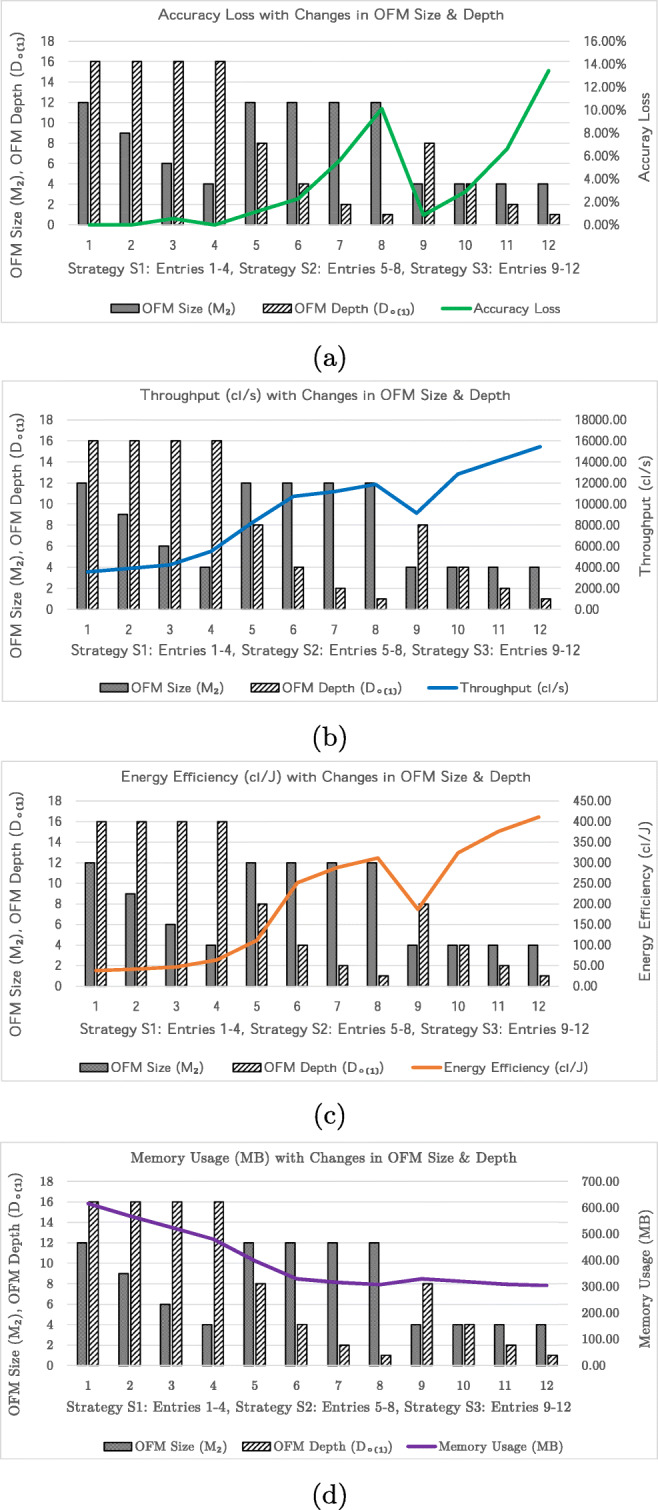
Conventional convolutional neural networks (CNNs) present a high computational workload and memory access cost (CMC). Spectral domain CNNs (SpCNNs) offer a computationally efficient approach to compute CNN training and inference. This paper investigates CMC of SpCNNs and its contributing components analytically and then proposes a methodology to optimize CMC, under three strategies, to enhance inference performance. In this methodology, output feature map (OFM) size, OFM depth or both are progressively reduced under an accuracy constraint to compute performance-optimized CNN inference. Before conducting training or testing, it can provide designers guidelines and preliminary insights regarding techniques for optimum performance, least degradation in accuracy and a balanced performance-accuracy trade-off. This methodology was evaluated on MNIST and Fashion MNIST datasets using LeNet-5 and AlexNet architectures. When compared to state-of-the-art SpCNN models, LeNet-5 achieves up to 4.2× (batch inference) and 4.1× (single-image inference) higher throughputs and 10.5× (batch inference) and 4.2× (single-image inference) greater energy efficiency at a maximum loss of 3% in test accuracy. When compared to the baseline model used in this study, AlexNet delivers 11.6× (batch inference) and 5× (single-image inference) increased throughput and 25× (batch inference) and 8.8× (single-image inference) more energy-efficient inference with just 4.4% reduction in accuracy.
传统卷积神经网络(CNN)存在高计算工作量和内存访问成本(CMC)的问题。谱域CNN(SpCNN)提供了一种计算效率高的方法来进行CNN训练和推理。本文对SpCNN的CMC及其组成部分进行了分析研究,然后提出了一种在三种策略下优化CMC以提高推理性能的方法。在该方法中,在精度约束下逐步减小输出特征图(OFM)大小、OFM深度或两者,以计算性能优化的CNN推理。在进行训练或测试之前,它可以为设计者提供有关实现最佳性能、最小精度下降和平衡性能与精度权衡的技术的指导方针和初步见解。该方法在MNIST和Fashion MNIST数据集上使用LeNet-5和AlexNet架构进行了评估。与最先进的SpCNN模型相比,LeNet-5在测试精度最大损失3%的情况下,批量推理吞吐量提高了4.2倍,单图像推理吞吐量提高了4.1倍,能量效率提高了10.5倍(批量推理)和4.2倍(单图像推理)。与本研究中使用的基线模型相比,AlexNet的吞吐量提高了11.6倍(批量推理)和5倍(单图像推理),推理能量效率提高了25倍(批量推理)和8.8倍(单图像推理),而精度仅降低了4.4%。