School of Artificial Intelligence, Beijing Normal University, Beijing 100875, China.
Comput Intell Neurosci. 2022 Jun 21;2022:2998242. doi: 10.1155/2022/2998242. eCollection 2022.
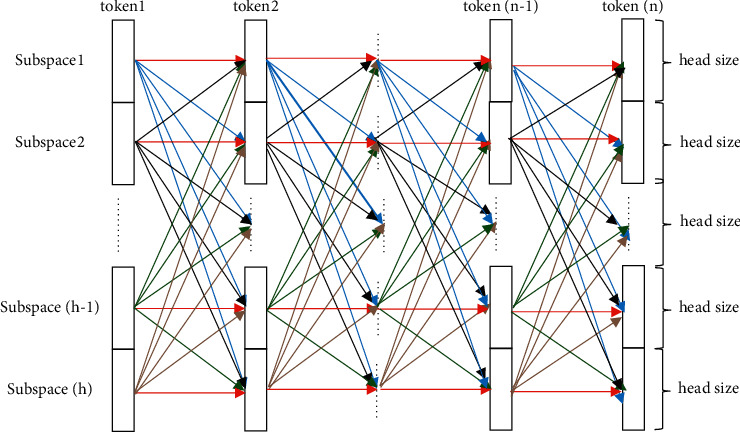
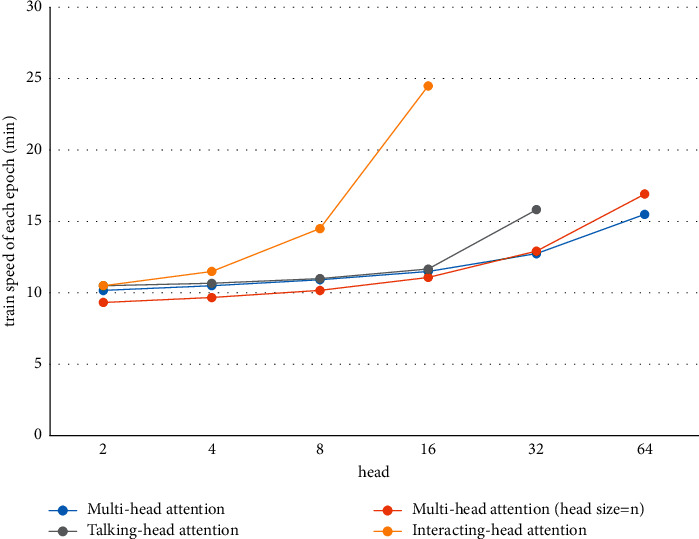
Transformer-based models have gained significant advances in neural machine translation (NMT). The main component of the transformer is the multihead attention layer. In theory, more heads enhance the expressive power of the NMT model. But this is not always the case in practice. On the one hand, the computations of each head attention are conducted in the same subspace, without considering the different subspaces of all the tokens. On the other hand, the low-rank bottleneck may occur, when the number of heads surpasses a threshold. To address the low-rank bottleneck, the two mainstream methods make the head size equal to the sequence length and complicate the distribution of self-attention heads. However, these methods are challenged by the variable sequence length in the corpus and the sheer number of parameters to be learned. Therefore, this paper proposes the interacting-head attention mechanism, which induces deeper and wider interactions across the attention heads by low-dimension computations in different subspaces of all the tokens, and chooses the appropriate number of heads to avoid low-rank bottleneck. The proposed model was tested on machine translation tasks of IWSLT2016 DE-EN, WMT17 EN-DE, and WMT17 EN-CS. Compared to the original multihead attention, our model improved the performance by 2.78 BLEU/0.85 WER/2.90 METEOR/2.65 ROUGE_L/0.29 CIDEr/2.97 YiSi and 2.43 BLEU/1.38 WER/3.05 METEOR/2.70 ROUGE_L/0.30 CIDEr/3.59 YiSi on the evaluation set and the test set, respectively, for IWSLT2016 DE-EN, 2.31 BLEU/5.94 WER/1.46 METEOR/1.35 ROUGE_L/0.07 CIDEr/0.33 YiSi and 1.62 BLEU/6.04 WER/1.39 METEOR/0.11 CIDEr/0.87 YiSi on the evaluation set and newstest2014, respectively, for WMT17 EN-DE, and 3.87 BLEU/3.05 WER/9.22 METEOR/3.81 ROUGE_L/0.36 CIDEr/4.14 YiSi and 4.62 BLEU/2.41 WER/9.82 METEOR/4.82 ROUGE_L/0.44 CIDEr/5.25 YiSi on the evaluation set and newstest2014, respectively, for WMT17 EN-CS.
基于转换器的模型在神经机器翻译(NMT)方面取得了重大进展。转换器的主要组成部分是多头注意力层。理论上,更多的头可以增强 NMT 模型的表达能力。但在实践中并非总是如此。一方面,每个头注意力的计算都是在相同的子空间中进行的,而没有考虑所有令牌的不同子空间。另一方面,当头的数量超过某个阈值时,可能会出现低秩瓶颈。为了解决低秩瓶颈问题,两种主流方法都使头的大小等于序列长度,并使自注意力头的分布复杂化。然而,这些方法受到语料库中可变序列长度和要学习的大量参数的挑战。因此,本文提出了交互头注意力机制,该机制通过所有令牌的不同子空间中的低维计算来诱导注意力头之间更深和更广泛的交互,并选择适当数量的头来避免低秩瓶颈。所提出的模型在 IWSLT2016 DE-EN、WMT17 EN-DE 和 WMT17 EN-CS 的机器翻译任务上进行了测试。与原始多头注意力相比,我们的模型在 IWSLT2016 DE-EN 的评估集和测试集上分别提高了 2.78 BLEU/0.85 WER/2.90 METEOR/2.65 ROUGE_L/0.29 CIDEr/2.97 YiSi 和 2.43 BLEU/1.38 WER/3.05 METEOR/2.70 ROUGE_L/0.30 CIDEr/3.59 YiSi 的性能,在 WMT17 EN-DE 的评估集和 newstest2014 上分别提高了 2.31 BLEU/5.94 WER/1.46 METEOR/1.35 ROUGE_L/0.07 CIDEr/0.33 YiSi 和 1.62 BLEU/6.04 WER/1.39 METEOR/0.11 CIDEr/0.87 YiSi 的性能,在 WMT17 EN-CS 的评估集和 newstest2014 上分别提高了 3.87 BLEU/3.05 WER/9.22 METEOR/3.81 ROUGE_L/0.36 CIDEr/4.14 YiSi 和 4.62 BLEU/2.41 WER/9.82 METEOR/4.82 ROUGE_L/0.44 CIDEr/5.25 YiSi 的性能。