Bhuvaneswari Kumar, Varalakshmi Murugesan
School of Computer Science Engineering and Information Systems, Vellore Institute of Technology, Vellore, Tamil Nadu, India.
School of Computer Science and Engineering, Vellore Institute of Technology, Vellore, Tamil Nadu, India.
Front Artif Intell. 2024 Sep 25;7:1381290. doi: 10.3389/frai.2024.1381290. eCollection 2024.
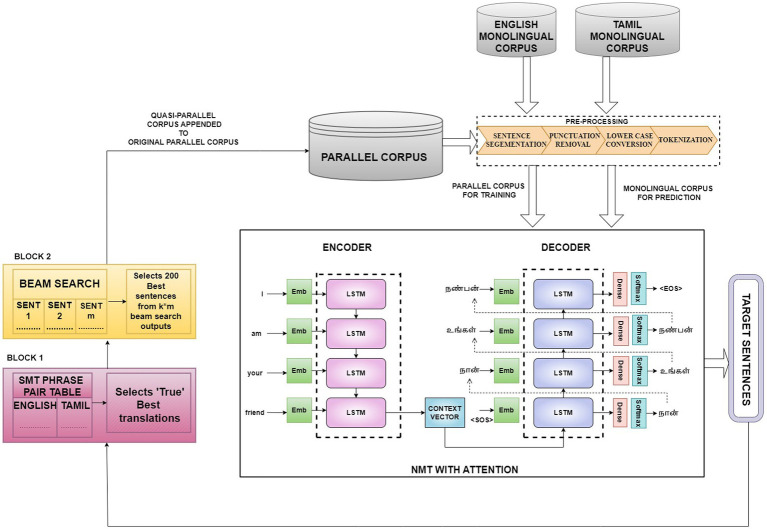
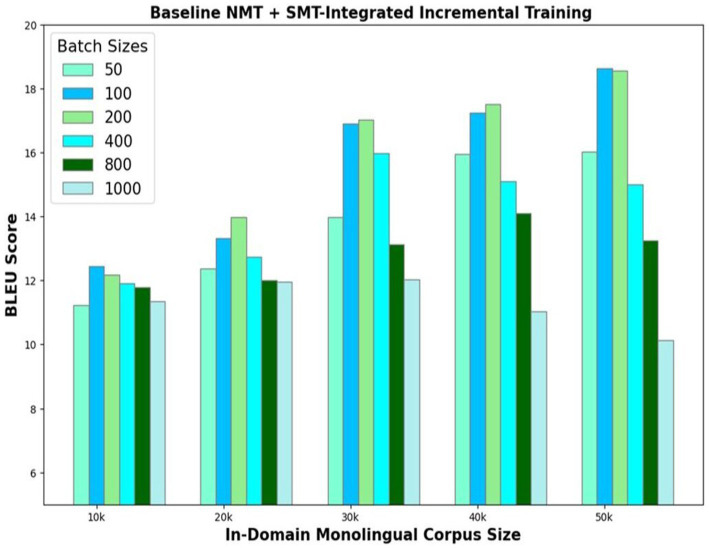
The data-hungry statistical machine translation (SMT) and neural machine translation (NMT) models offer state-of-the-art results for languages with abundant data resources. However, extensive research is imperative to make these models perform equally well for low-resource languages. This paper proposes a novel approach to integrate the best features of the NMT and SMT systems for improved translation performance of low-resource English-Tamil language pair. The suboptimal NMT model trained with the small parallel corpus translates the monolingual corpus and selects only the best translations, to retrain itself in the next iteration. The proposed method employs the SMT phrase-pair table to determine the best translations, based on the maximum match between the words of the phrase-pair dictionary and each of the individual translations. This repeating cycle of translation and retraining generates a large quasi-parallel corpus, thus making the NMT model more powerful. SMT-integrated incremental training demonstrates a substantial difference in translation performance as compared to the existing approaches for incremental training. The model is strengthened further by adopting a beam search decoding strategy to produce best possible translations for each input sentence. Empirical findings prove that the proposed model with BLEU scores of 19.56 and 23.49 outperforms the baseline NMT with scores 11.06 and 17.06 for Eng-to-Tam and Tam-to-Eng translations, respectively. METEOR score evaluation further corroborates these results, proving the supremacy of the proposed model.
对数据需求极大的统计机器翻译(SMT)和神经机器翻译(NMT)模型在拥有丰富数据资源的语言上能提供最先进的结果。然而,开展广泛研究以使这些模型在低资源语言上同样表现出色势在必行。本文提出了一种新颖的方法,将NMT和SMT系统的最佳特性整合起来,以提高低资源英语 - 泰米尔语对的翻译性能。用小并行语料库训练的次优NMT模型对单语语料库进行翻译,只选择最佳译文,以便在下一次迭代中重新训练自身。所提出的方法利用SMT短语对表,基于短语对字典中的单词与各个单独译文之间的最大匹配来确定最佳译文。这种翻译和重新训练的重复循环生成了一个大型准并行语料库,从而使NMT模型更强大。与现有的增量训练方法相比,集成SMT的增量训练在翻译性能上显示出显著差异。通过采用束搜索解码策略为每个输入句子生成尽可能好的译文,该模型得到了进一步强化。实证结果证明,所提出的模型在英语到泰米尔语和泰米尔语到英语翻译中,BLEU分数分别为19.56和23.49,优于基线NMT的分数11.06和17.06。METEOR分数评估进一步证实了这些结果,证明了所提出模型的优越性。