The Habit Lab, Department of Clinical Psychology, University of Amsterdam, Amsterdam, Netherlands.
Amsterdam Brain and Cognition, University of Amsterdam, Nieuwe Achtergracht 129B, 1018, Amsterdam, WS, Netherlands.
Behav Res Methods. 2023 Aug;55(5):2687-2705. doi: 10.3758/s13428-022-01922-4. Epub 2022 Jul 22.
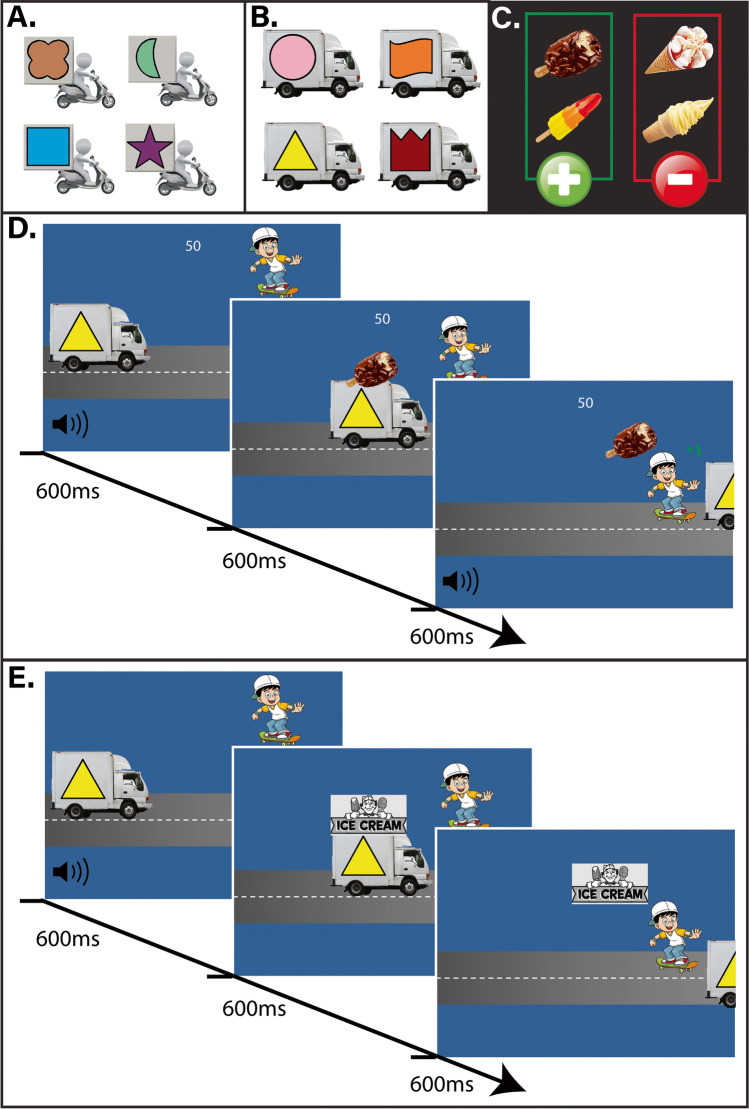
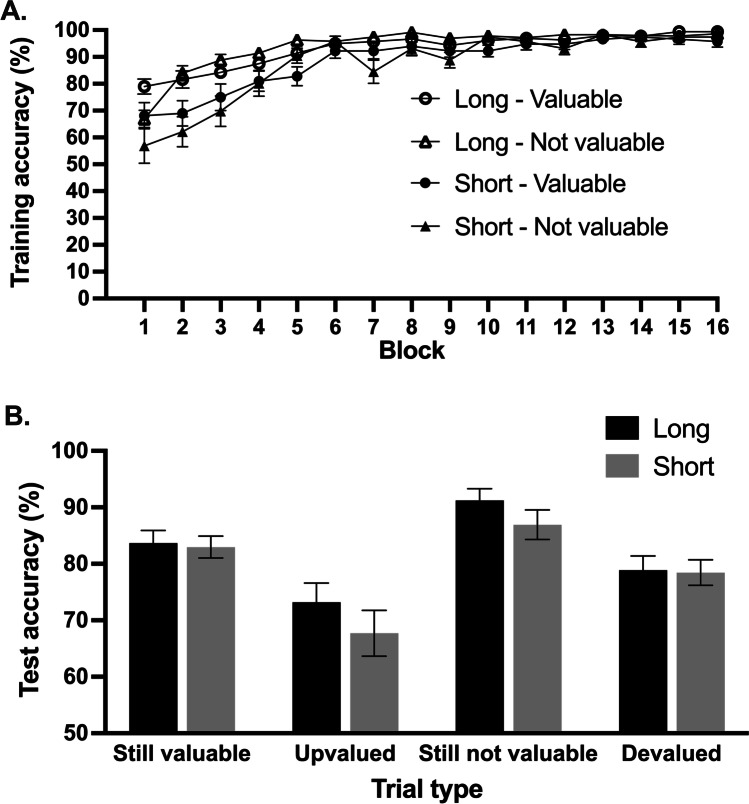
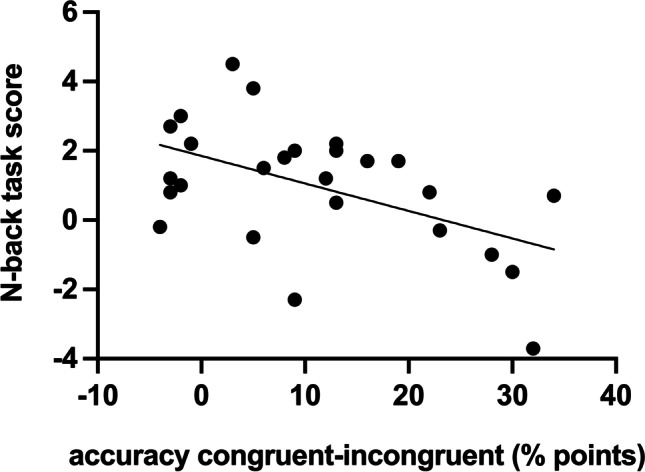
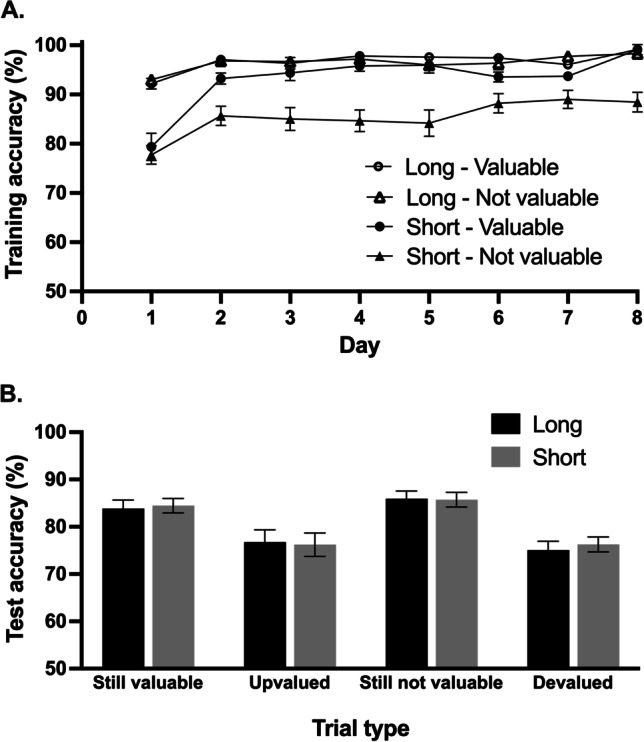
The translation of the outcome-devaluation paradigm to study habit in humans has yielded interesting insights but proven to be challenging. We present a novel, outcome-revaluation task with a symmetrical design, in the sense that half of the available outcomes are always valuable and the other half not-valuable. In the present studies, during the instrumental learning phase, participants learned to respond (Go) to certain stimuli to collect valuable outcomes (and points) while refraining to respond (NoGo) to stimuli signaling not-valuable outcomes. Half of the stimuli were short-trained, while the other half were long-trained. Subsequently, in the test phase, the signaled outcomes were either value-congruent with training (still-valuable and still-not-valuable), or value-incongruent (devalued and upvalued). The change in outcome value on value-incongruent trials meant that participants had to flexibly adjust their behavior. At the end of the training phase, participants completed the self-report behavioral automaticity index - providing an automaticity score for each stimulus-response association. We conducted two experiments using this task, that both provided evidence for stimulus-driven habits as reflected in poorer performance on devalued and upvalued trials relative to still-not-valuable trials and still-valuable trials, respectively. While self-reported automaticity increased with longer training, behavioral flexibility was not affected. After extended training (Experiment 2), higher levels of self-reported automaticity when responding to stimuli signaling valuable outcomes were related to more 'slips of action' when the associated outcome was subsequently devalued. We conclude that the symmetrical outcome-revaluation task provides a promising paradigm for the experimental investigation of habits in humans.
将成果评价范式转化为人类习惯研究取得了有趣的见解,但证明具有挑战性。我们提出了一种新颖的、具有对称设计的成果再评价任务,从某种意义上说,一半的可用成果总是有价值的,另一半则没有价值。在本研究中,在工具学习阶段,参与者学会对某些刺激做出反应(Go)以收集有价值的结果(和分数),同时避免对表示无价值结果的刺激做出反应(NoGo)。一半的刺激是短期训练的,而另一半是长期训练的。随后,在测试阶段,信号的结果要么与训练一致(仍然有价值和仍然没有价值),要么不一致(贬值和增值)。在不一致的价值试验中,结果价值的变化意味着参与者必须灵活地调整他们的行为。在训练阶段结束时,参与者完成了自我报告的行为自动性指数-为每个刺激-反应关联提供一个自动性分数。我们使用这个任务进行了两项实验,这两项实验都提供了刺激驱动习惯的证据,表现为在贬值和增值试验中表现不如仍然没有价值试验和仍然有价值试验。虽然自我报告的自动性随着更长时间的训练而增加,但行为灵活性不受影响。经过扩展的训练(实验 2),当对有价值的结果发出信号的刺激做出反应时,自我报告的自动性越高,当相关的结果随后贬值时,“行动失误”就越多。我们的结论是,对称的成果再评价任务为人类习惯的实验研究提供了一个很有前途的范例。