Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville, TN 37996, USA.
Cyber Resilience and Intelligence Division, Oak Ridge National Laboratory, Oak Ridge, TN 37830, USA.
Bioinformatics. 2022 Sep 15;38(18):4369-4379. doi: 10.1093/bioinformatics/btac508.
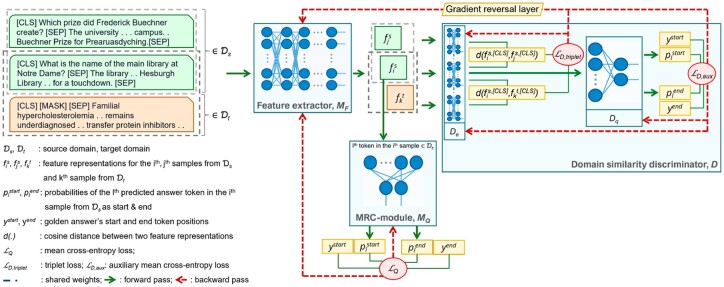
Biomedical machine reading comprehension (biomedical-MRC) aims to comprehend complex biomedical narratives and assist healthcare professionals in retrieving information from them. The high performance of modern neural network-based MRC systems depends on high-quality, large-scale, human-annotated training datasets. In the biomedical domain, a crucial challenge in creating such datasets is the requirement for domain knowledge, inducing the scarcity of labeled data and the need for transfer learning from the labeled general-purpose (source) domain to the biomedical (target) domain. However, there is a discrepancy in marginal distributions between the general-purpose and biomedical domains due to the variances in topics. Therefore, direct-transferring of learned representations from a model trained on a general-purpose domain to the biomedical domain can hurt the model's performance.
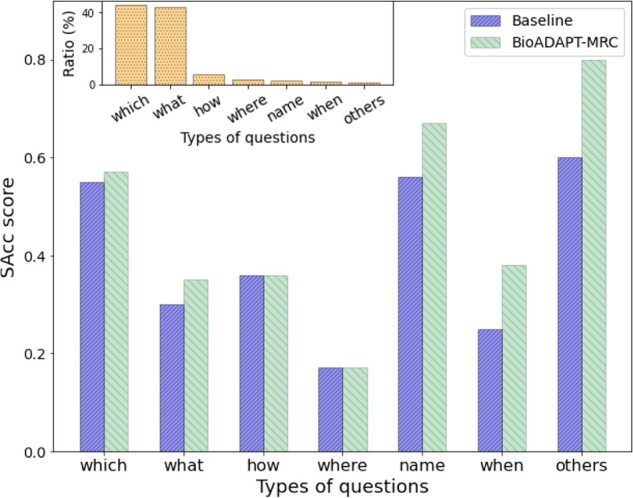
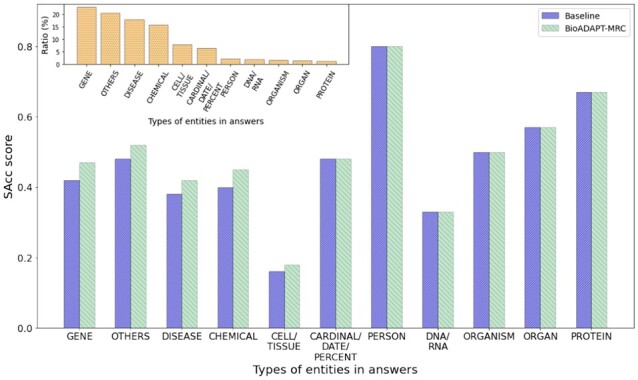
We present an adversarial learning-based domain adaptation framework for the biomedical machine reading comprehension task (BioADAPT-MRC), a neural network-based method to address the discrepancies in the marginal distributions between the general and biomedical domain datasets. BioADAPT-MRC relaxes the need for generating pseudo labels for training a well-performing biomedical-MRC model. We extensively evaluate the performance of BioADAPT-MRC by comparing it with the best existing methods on three widely used benchmark biomedical-MRC datasets-BioASQ-7b, BioASQ-8b and BioASQ-9b. Our results suggest that without using any synthetic or human-annotated data from the biomedical domain, BioADAPT-MRC can achieve state-of-the-art performance on these datasets.
BioADAPT-MRC is freely available as an open-source project at https://github.com/mmahbub/BioADAPT-MRC.
Supplementary data are available at Bioinformatics online.
生物医学机器阅读理解(biomedical-MRC)旨在理解复杂的生物医学叙述,并帮助医疗保健专业人员从中检索信息。现代基于神经网络的 MRC 系统的高性能依赖于高质量、大规模、人工标注的训练数据集。在生物医学领域,创建此类数据集的一个关键挑战是需要领域知识,这导致了标记数据的稀缺性,并需要从标记的通用(源)领域到生物医学(目标)领域进行迁移学习。然而,由于主题的差异,通用领域和生物医学领域之间的边缘分布存在差异。因此,直接将从通用领域训练的模型中学习到的表示转移到生物医学领域可能会损害模型的性能。
我们提出了一种基于对抗学习的生物医学机器阅读理解任务的域自适应框架(BioADAPT-MRC),这是一种基于神经网络的方法,可以解决通用和生物医学领域数据集之间边缘分布差异的问题。BioADAPT-MRC 放宽了对训练表现良好的生物医学-MRC 模型生成伪标签的需求。我们通过将 BioADAPT-MRC 与三个广泛使用的生物医学-MRC 基准数据集(BioASQ-7b、BioASQ-8b 和 BioASQ-9b)上的最佳现有方法进行比较,对其性能进行了广泛评估。我们的结果表明,在不使用任何来自生物医学领域的合成或人工标注数据的情况下,BioADAPT-MRC 可以在这些数据集上实现最先进的性能。
BioADAPT-MRC 可在 https://github.com/mmahbub/BioADAPT-MRC 上作为一个开源项目免费获得。
补充数据可在 Bioinformatics 在线获取。