Silva Arthur C, Borba Joyce V V B, Alves Vinicius M, Hall Steven U S, Furnham Nicholas, Kleinstreuer Nicole, Muratov Eugene, Tropsha Alexander, Andrade Carolina Horta
LabMol-Laboratory for Molecular Modeling and Drug Design, Faculdade de Farmácia, Universidade Federal de Goiás-UFG, Goiânia, GO, Brazil.
Laboratory for Molecular Modeling, UNC Eshelman School of Pharmacy, University of North Carolina, Chapel Hill, NC, USA.
Artif Intell Life Sci. 2021 Dec;1. doi: 10.1016/j.ailsci.2021.100028. Epub 2021 Dec 5.
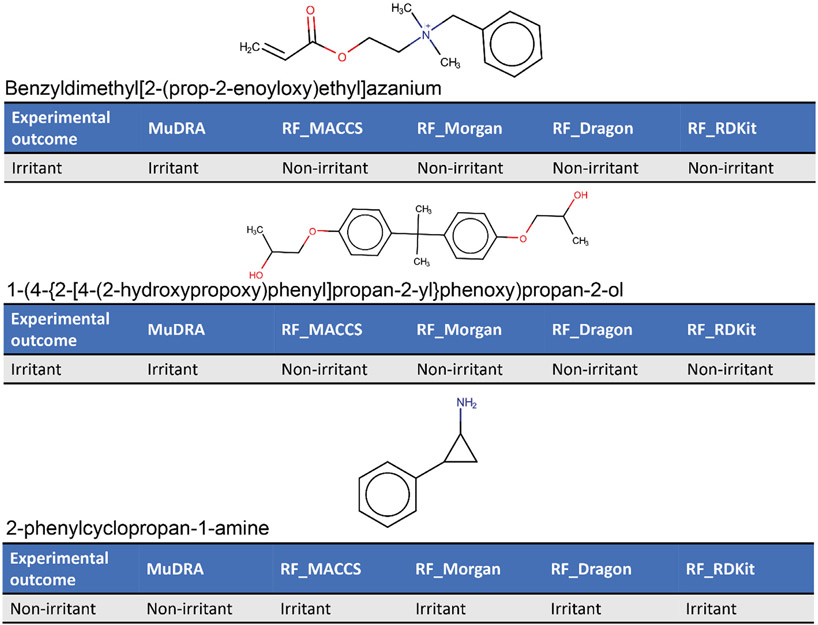
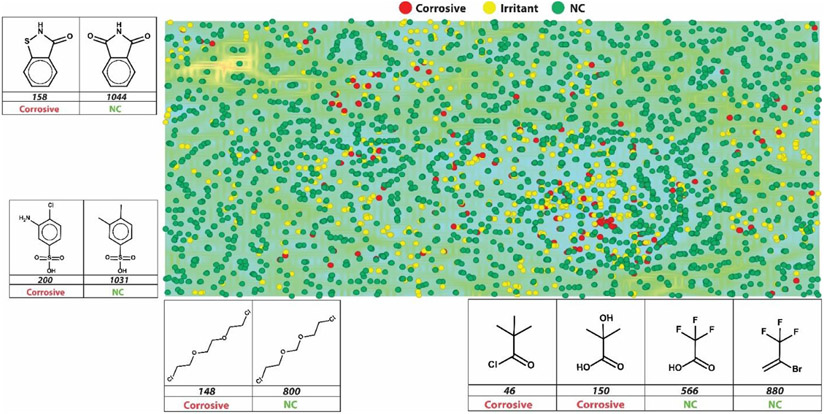
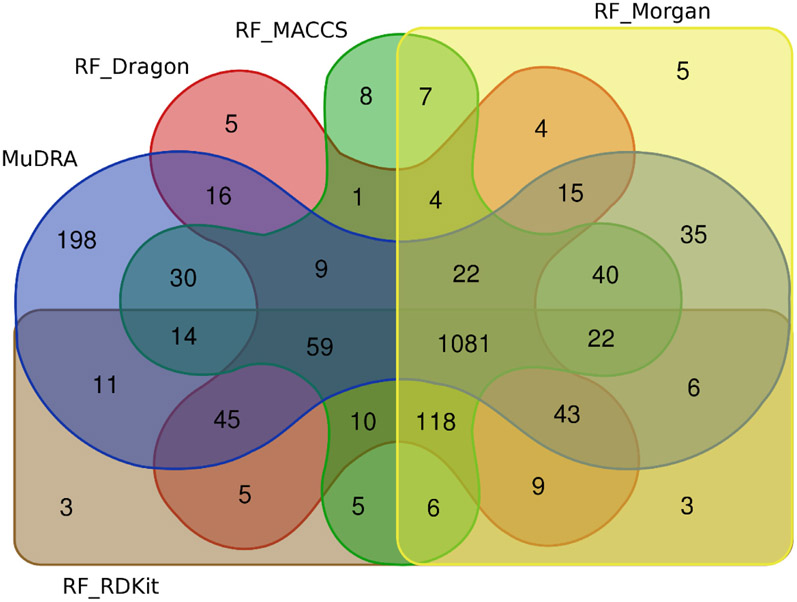
Eye irritation and corrosion are fundamental considerations in developing chemicals to be used in or near the eye, from cleaning products to ophthalmic solutions. Unfortunately, animal testing is currently the standard method to identify compounds that cause eye irritation or corrosion. Yet, there is growing pressure on the part of regulatory agencies both in the USA and abroad to develop New Approach Methodologies (NAMs) that help reduce the need for animal testing and address unmet need to modernize safety evaluation of chemical hazards. In furthering the development and applications of computational NAMs in chemical safety assessment, in this study we have collected the largest expertly curated dataset of compounds tested for eye irritation and corrosion, and employed this data to build and validate binary and multi-classification Quantitative Structure-Activity Relationships (QSAR) models that can reliably assess eye irritation/corrosion potential of novel untested compounds. QSAR models were generated with Random Forest (RF) and Multi-Descriptor Read Across (MuDRA) machine learning (ML) methods, and validated using a 5-fold external cross-validation protocol. These models demonstrated high balanced accuracy (CCR of 0.68-0.88), sensitivity (SE of 0.61-0.84), positive predictive value (PPV of 0.65-0.90), specificity (SP of 0.56-0.91), and negative predictive value (NPV of 0.68-0.85). Overall, MuDRA models outperformed RF models and were applied to predict compounds' irritation/corrosion potential from the Inactive Ingredient Database, which contains components present in FDA-approved drug products, and from the Cosmetic Ingredient Database, the European Commission source of information on cosmetic substances. All models built and validated in this study are publicly available at the STopTox web portal (https://stoptox.mml.unc.edu/). These models can be employed as reliable tools for identifying potential eye irritant/corrosive compounds.
从清洁产品到眼科溶液,在开发用于眼部或眼部附近的化学品时,眼部刺激和腐蚀性是基本要考虑的因素。不幸的是,动物试验目前是识别引起眼部刺激或腐蚀的化合物的标准方法。然而,美国和国外的监管机构越来越多地面临压力,要求开发新方法学(NAMs),以帮助减少动物试验的需求,并满足化学危害安全评估现代化的未满足需求。为了进一步推动计算性NAMs在化学安全评估中的开发和应用,在本研究中,我们收集了经过专家精心策划的、用于眼部刺激和腐蚀测试的最大化合物数据集,并利用这些数据构建和验证了二元和多分类定量构效关系(QSAR)模型,这些模型能够可靠地评估新型未测试化合物的眼部刺激/腐蚀潜力。QSAR模型采用随机森林(RF)和多描述符跨类别阅读(MuDRA)机器学习(ML)方法生成,并使用5倍外部交叉验证协议进行验证。这些模型表现出高平衡准确率(CCR为0.68 - 0.88)、灵敏度(SE为0.61 - 0.84)、阳性预测值(PPV为0.65 - 0.90)、特异性(SP为0.56 - 0.91)和阴性预测值(NPV为0.68 - 0.85)。总体而言,MuDRA模型优于RF模型,并被应用于从非活性成分数据库(其中包含FDA批准的药品中存在的成分)和化妆品成分数据库(欧盟委员会关于化妆品物质的信息来源)预测化合物的刺激/腐蚀潜力。本研究中构建和验证的所有模型均可在STopTox门户网站(https://stoptox.mml.unc.edu/)上公开获取。这些模型可作为识别潜在眼部刺激/腐蚀性化合物的可靠工具。