Varma Gatha, Chauhan Ritu, Singh Dhananjay
Amity Institute of Information Technology, Amity University, Noida, India.
Center for Computational Biology and Bioinformatics, Amity University, Noida, India.
Cybersecur (Singap). 2022;5(1):26. doi: 10.1186/s42400-022-00129-6. Epub 2022 Aug 3.
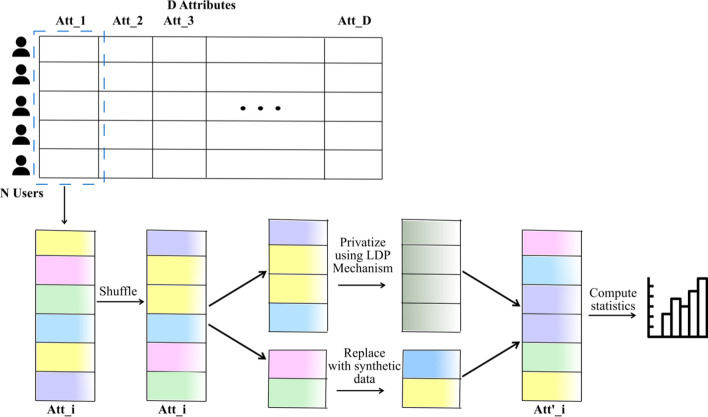
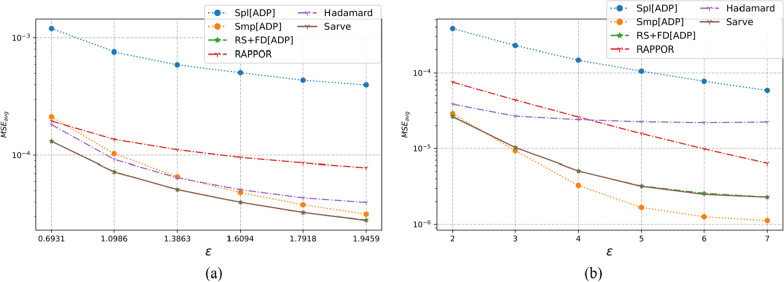
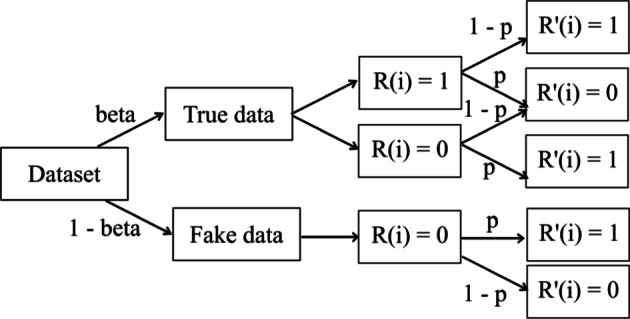
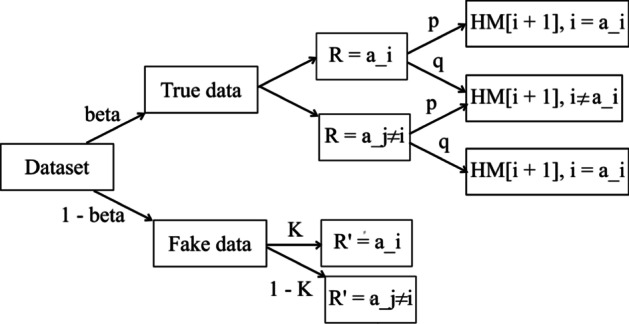
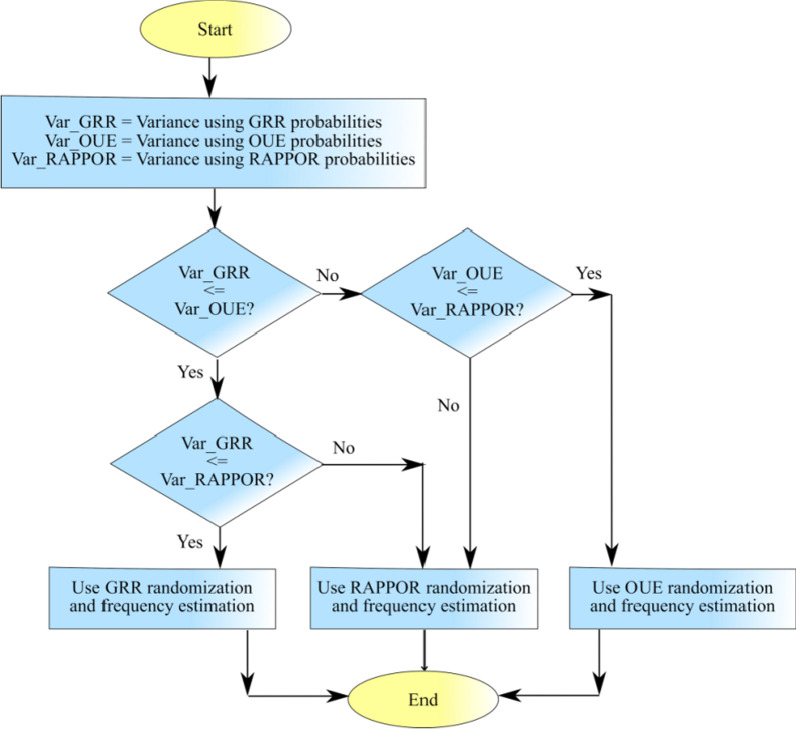
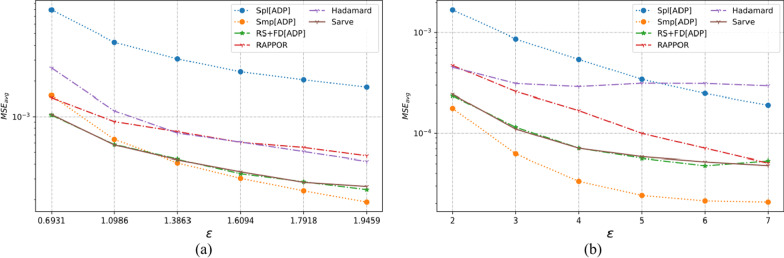
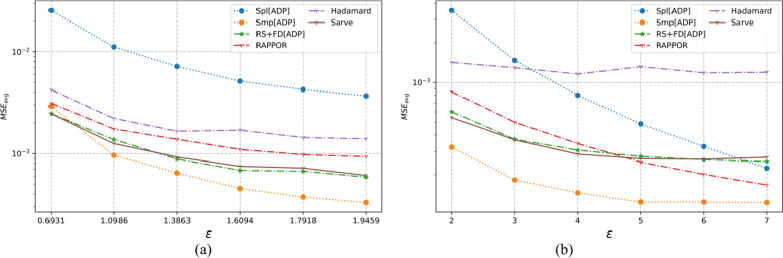
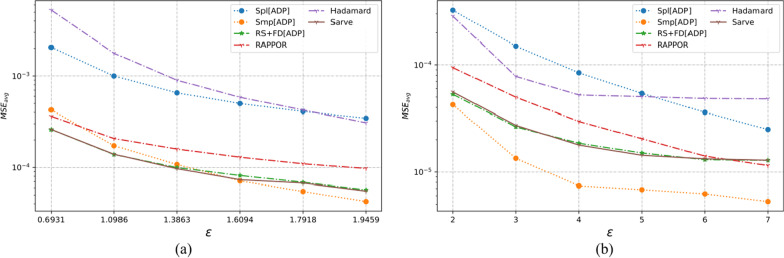
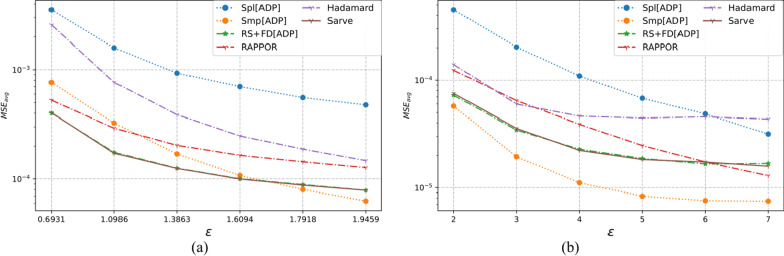
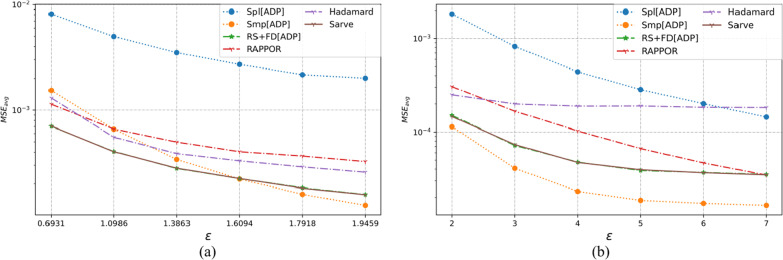
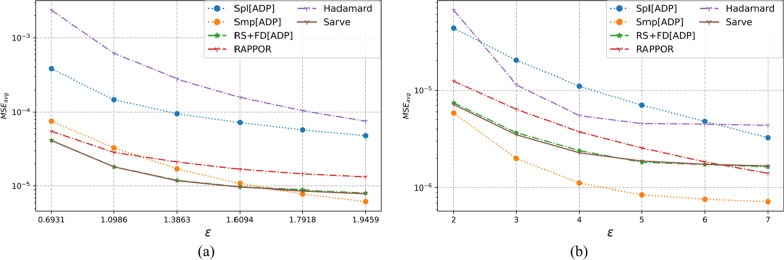
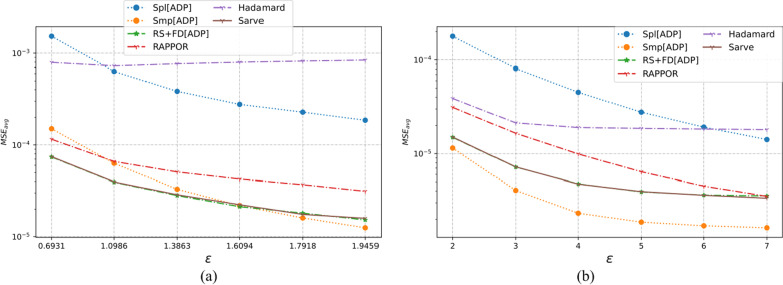
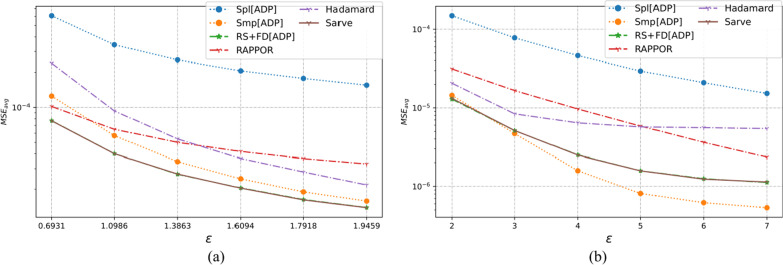
The collection of user attributes by service providers is a double-edged sword. They are instrumental in driving statistical analysis to train more accurate predictive models like recommenders. The analysis of the collected user data includes frequency estimation for categorical attributes. Nonetheless, the users deserve privacy guarantees against inadvertent identity disclosures. Therefore algorithms called frequency oracles were developed to randomize or perturb user attributes and estimate the frequencies of their values. We propose , a frequency oracle that used Randomized Aggregatable Privacy-Preserving Ordinal Response (RAPPOR) and Hadamard Response (HR) for randomization in combination with fake data. The design of a service-oriented architecture must consider two types of complexities, namely computational and communication. The functions of such systems aim to minimize the two complexities and therefore, the choice of privacy-enhancing methods must be a calculated decision. The variant of RAPPOR we had used was realized through bloom filters. A bloom filter is a memory-efficient data structure that offers time complexity of O(1). On the other hand, HR has been proven to give the best communication costs of the order of log(b) for b-bits communication. Therefore, is a step towards frequency oracles that exhibit how privacy provisions of existing methods can be combined with those of fake data to achieve statistical results comparable to the original data. also implemented an adaptive solution enhanced from the work of Arcolezi et al. The use of RAPPOR was found to provide better privacy-utility tradeoffs for specific privacy budgets in both high and general privacy regimes.
服务提供商收集用户属性是一把双刃剑。它们有助于推动统计分析,以训练更准确的预测模型,如推荐系统。对收集到的用户数据进行分析包括对分类属性的频率估计。尽管如此,用户应得到防止身份意外泄露的隐私保障。因此,开发了称为频率预言机的算法来对用户属性进行随机化或扰动,并估计其值的频率。我们提出了一种频率预言机,它使用随机可聚合隐私保护有序响应(RAPPOR)和哈达玛响应(HR)进行随机化,并结合虚假数据。面向服务架构的设计必须考虑两种类型的复杂性,即计算复杂性和通信复杂性。此类系统的功能旨在最小化这两种复杂性,因此,选择隐私增强方法必须是经过深思熟虑的决定。我们使用的RAPPOR变体是通过布隆过滤器实现的。布隆过滤器是一种内存高效的数据结构,其时间复杂度为O(1)。另一方面,已证明HR在b位通信时能提供最佳的通信成本,约为log(b)。因此,这是朝着频率预言机迈出的一步,展示了如何将现有方法的隐私规定与虚假数据的隐私规定相结合,以获得与原始数据相当的统计结果。我们还实现了一种从Arcolezi等人的工作中增强而来的自适应解决方案。研究发现,在高隐私和一般隐私模式下,对于特定的隐私预算,使用RAPPOR能提供更好的隐私-效用权衡。