Moisio Anssi, Porjazovski Dejan, Rouhe Aku, Getman Yaroslav, Virkkunen Anja, AlGhezi Ragheb, Lennes Mietta, Grósz Tamás, Lindén Krister, Kurimo Mikko
Department of Signal Processing and Acoustics, Aalto University, Espoo, Finland.
Department of Digital Humanities, University of Helsinki, Helsinki, Finland.
Lang Resour Eval. 2022 Aug 9:1-33. doi: 10.1007/s10579-022-09606-3.
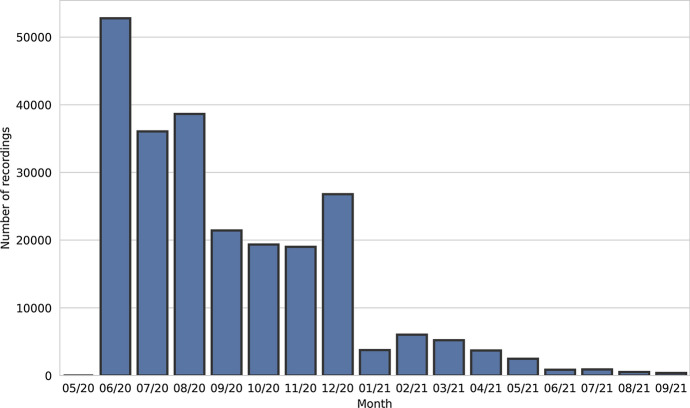
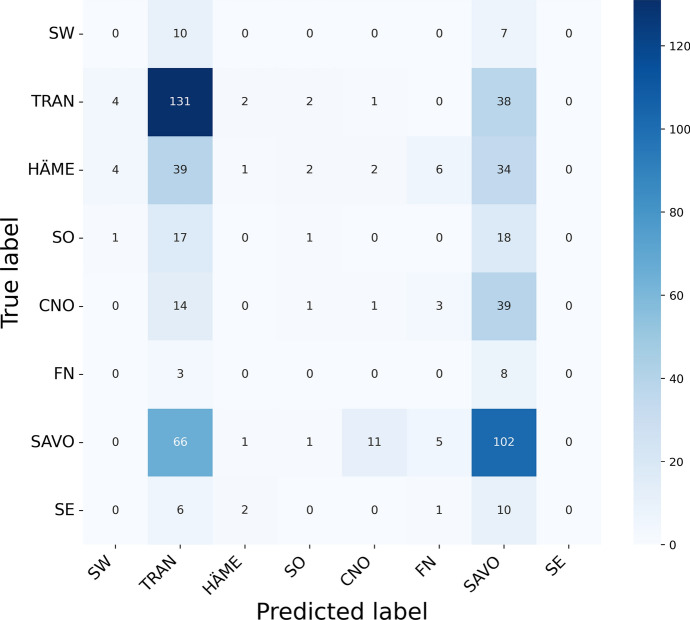
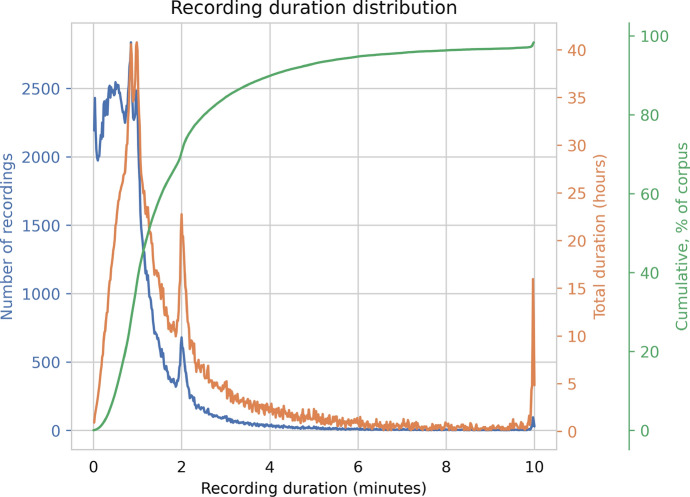
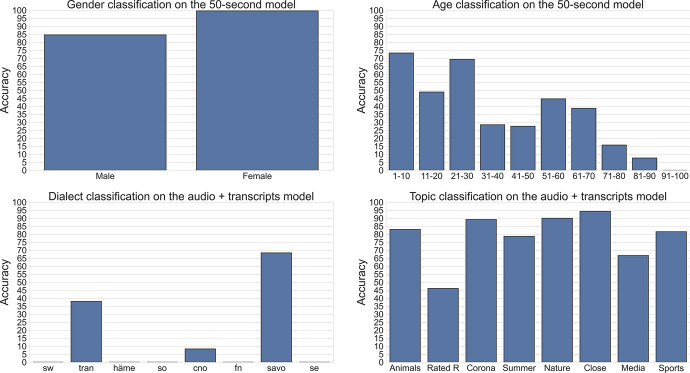
The Donate Speech campaign has so far succeeded in gathering approximately 3600 h of ordinary, colloquial Finnish speech into the () corpus. The corpus includes over twenty thousand speakers from all the regions of Finland and from all age brackets. The primary goals of the collection were to create a representative, large-scale resource to study spontaneous spoken Finnish and to accelerate the development of language technology and speech-based services. In this paper, we present the collection process and the collected corpus, and showcase its versatility through multiple use cases. The evaluated use cases include: automatic speech recognition of spontaneous speech, detection of age, gender, dialect and topic and metadata analysis. We provide benchmarks for the use cases, as well downloadable, trained baseline systems with open-source code for reproducibility. One further use case is to verify the metadata and transcripts given in this corpus itself, and to suggest artificial metadata and transcripts for the part of the corpus where it is missing.
到目前为止,“捐赠语音”活动已成功收集了约3600小时的普通芬兰口语,并将其纳入()语料库。该语料库涵盖了来自芬兰所有地区、各个年龄段的两万多名说话者。收集的主要目标是创建一个具有代表性的大规模资源,用于研究芬兰语自然口语,并加速语言技术和语音服务的发展。在本文中,我们介绍了收集过程和所收集的语料库,并通过多个用例展示了其多功能性。评估的用例包括:自然口语的自动语音识别、年龄、性别、方言和主题检测以及元数据分析。我们为这些用例提供了基准,以及带有开源代码的可下载训练基线系统,以实现可重复性。另一个用例是验证该语料库本身给出的元数据和转录本,并为语料库中缺失的部分建议人工元数据和转录本。