Department of Computer Engineering, Qazvin Branch, Islamic Azad University, Qazvin, Iran.
Department of Computer Engineering, Urmia Branch, Islamic Azad University, Urmia, Iran.
Comput Intell Neurosci. 2022 Jul 31;2022:7612276. doi: 10.1155/2022/7612276. eCollection 2022.
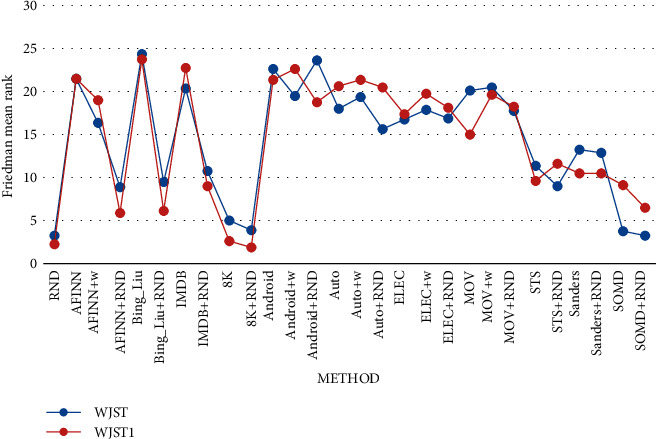
Latent Dirichlet Allocation (LDA) is an approach to unsupervised learning that aims to investigate the semantics among words in a document as well as the influence of a subject on a word. As an LDA-based model, Joint Sentiment-Topic (JST) examines the impact of topics and emotions on words. The emotion parameter is insufficient, and additional parameters may play valuable roles in achieving better performance. In this study, two new topic models, Weighted Joint Sentiment-Topic (WJST) and Weighted Joint Sentiment-Topic 1 (WJST1), have been presented to extend and improve JST through two new parameters that can generate a sentiment dictionary. In the proposed methods, each word in a document affects its neighbors, and different words in the document may be affected simultaneously by several neighbor words. Therefore, proposed models consider the effect of words on each other, which, from our view, is an important factor and can increase the performance of baseline methods. Regarding evaluation results, the new parameters have an immense effect on model accuracy. While not requiring labeled data, the proposed methods are more accurate than discriminative models such as SVM and logistic regression in accordance with evaluation results. The proposed methods are simple with a low number of parameters. While providing a broad perception of connections between different words in documents of a single collection (single-domain) or multiple collections (multidomain), the proposed methods have prepared solutions for two different situations (single-domain and multidomain). WJST is suitable for multidomain datasets, and WJST1 is a version of WJST which is suitable for single-domain datasets. While being able to detect emotion at the level of the document, the proposed models improve the evaluation outcomes of the baseline approaches. Thirteen datasets with different sizes have been used in implementations. In this study, perplexity, opinion mining at the level of the document, and topic_coherency are employed for assessment. Also, a statistical test called Friedman test is used to check whether the results of the proposed models are statistically different from the results of other algorithms. As can be seen from results, the accuracy of proposed methods is above 80% for most of the datasets. WJST1 achieves the highest accuracy on Movie dataset with 97 percent, and WJST achieves the highest accuracy on Electronic dataset with 86 percent. The proposed models obtain better results compared to Adaptive Lexicon learning using Genetic Algorithm (ALGA), which employs an evolutionary approach to make an emotion dictionary. Results show that the proposed methods perform better with different topic number settings, especially for WJST1 with 97% accuracy at || = 5 on the Movie dataset.
潜在狄利克雷分配 (LDA) 是一种无监督学习方法,旨在研究文档中单词之间的语义以及主题对单词的影响。作为基于 LDA 的模型,联合情感主题 (JST) 检查主题和情感对单词的影响。情感参数不足,并且其他参数可能在实现更好的性能方面发挥有价值的作用。在这项研究中,提出了两种新的主题模型,加权联合情感主题 (WJST) 和加权联合情感主题 1 (WJST1),通过两个新的参数来扩展和改进 JST,这些参数可以生成情感词典。在所提出的方法中,文档中的每个单词都会影响其邻居,并且文档中的不同单词可能会同时受到几个邻居单词的影响。因此,所提出的模型考虑了单词之间的相互影响,这从我们的角度来看是一个重要因素,可以提高基线方法的性能。关于评估结果,新参数对模型准确性有巨大影响。虽然不需要标记数据,但与 SVM 和逻辑回归等判别模型相比,所提出的方法根据评估结果更准确。所提出的方法简单,参数数量少。在为单域和多域两种情况(单域和多域)提供解决方案的同时,所提出的方法提供了对单个集合(单域)或多个集合(多域)中不同单词之间连接的广泛认识。WJST 适用于多域数据集,而 WJST1 是适用于单域数据集的 WJST 版本。虽然能够在文档级别检测情感,但所提出的模型提高了基线方法的评估结果。在实现中使用了 13 个具有不同大小的数据集。在这项研究中,使用困惑度、文档级别的意见挖掘和主题一致性进行评估。此外,还使用称为 Friedman 检验的统计检验来检查所提出的模型的结果是否与其他算法的结果在统计上有显著差异。从结果可以看出,在所提出的方法中,大多数数据集的准确率都在 80%以上。WJST1 在 Movie 数据集上的准确率最高,为 97%,WJST 在 Electronic 数据集上的准确率最高,为 86%。与使用遗传算法 (ALGA) 进行自适应词汇学习的方法相比,所提出的方法具有更好的效果,该方法采用进化方法制作情感词典。结果表明,在所提出的方法中,不同主题数量的设置效果更好,特别是对于 WJST1,在 Movie 数据集上的||=5 时准确率为 97%。