Hunan Provincial Key Lab on Bioinformatics, School of Computer Science and Engineering, Central South University, Changsha 410083, China.
Division of Biomedical Engineering, Department of Computer Science, Department of Mechanical Engineering University of Saskatchewan, Saskatoon, SK S7N 5A9, Canada.
Bioinformatics. 2023 Jan 1;39(1). doi: 10.1093/bioinformatics/btac779.
Protein essentiality is usually accepted to be a conditional trait and strongly affected by cellular environments. However, existing computational methods often do not take such characteristics into account, preferring to incorporate all available data and train a general model for all cell lines. In addition, the lack of model interpretability limits further exploration and analysis of essential protein predictions.
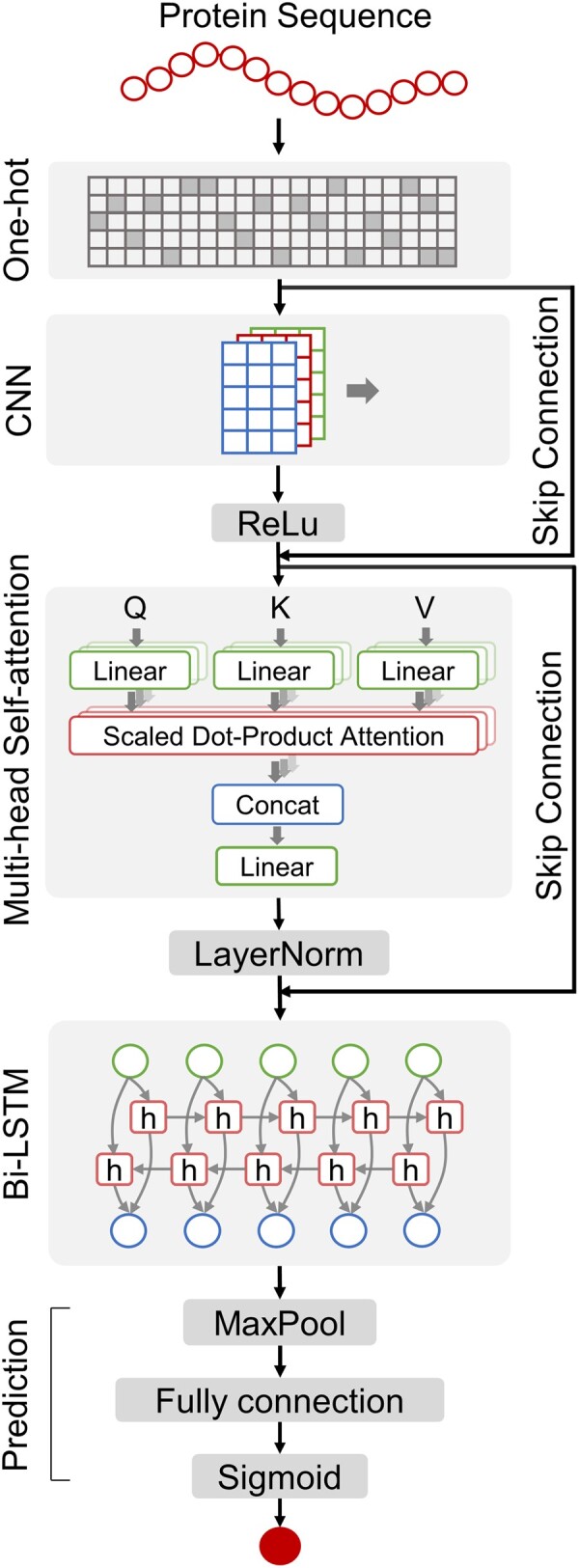
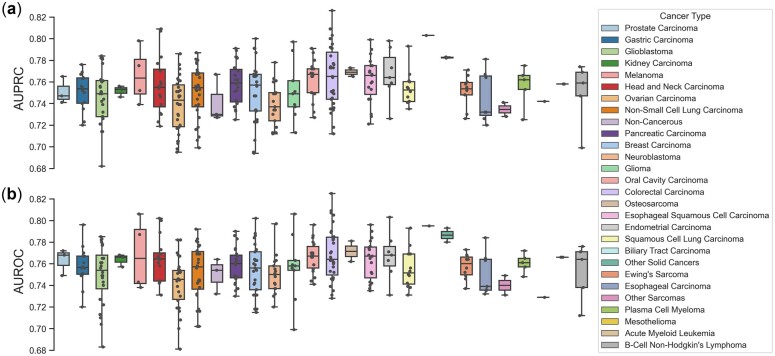
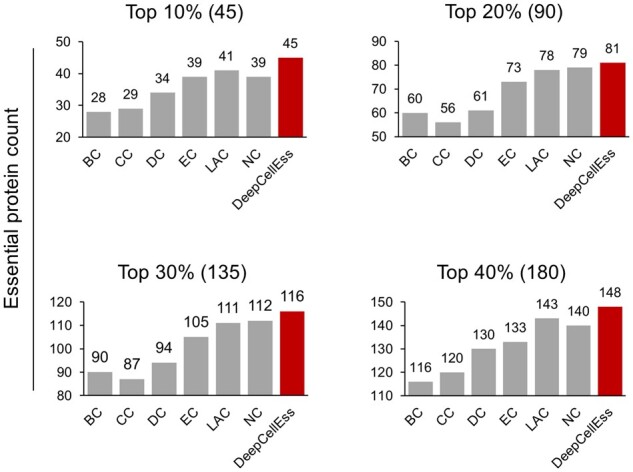
In this study, we proposed DeepCellEss, a sequence-based interpretable deep learning framework for cell line-specific essential protein predictions. DeepCellEss utilizes a convolutional neural network and bidirectional long short-term memory to learn short- and long-range latent information from protein sequences. Further, a multi-head self-attention mechanism is used to provide residue-level model interpretability. For model construction, we collected extremely large-scale benchmark datasets across 323 cell lines. Extensive computational experiments demonstrate that DeepCellEss yields effective prediction performance for different cell lines and outperforms existing sequence-based methods as well as network-based centrality measures. Finally, we conducted some case studies to illustrate the necessity of considering specific cell lines and the superiority of DeepCellEss. We believe that DeepCellEss can serve as a useful tool for predicting essential proteins across different cell lines.
The DeepCellEss web server is available at http://csuligroup.com:8000/DeepCellEss. The source code and data underlying this study can be obtained from https://github.com/CSUBioGroup/DeepCellEss.
Supplementary data are available at Bioinformatics online.
蛋白质的必需性通常被认为是一种有条件的特征,并且受到细胞环境的强烈影响。然而,现有的计算方法往往没有考虑到这些特征,而是倾向于整合所有可用的数据,并为所有细胞系训练一个通用模型。此外,缺乏模型可解释性限制了对必需蛋白质预测的进一步探索和分析。
在这项研究中,我们提出了 DeepCellEss,这是一个基于序列的可解释深度学习框架,用于细胞系特异性必需蛋白质预测。DeepCellEss 利用卷积神经网络和双向长短期记忆从蛋白质序列中学习短程和长程潜在信息。此外,使用多头自注意力机制提供残基级别的模型可解释性。为了构建模型,我们收集了跨越 323 个细胞系的超大规模基准数据集。广泛的计算实验表明,DeepCellEss 为不同的细胞系提供了有效的预测性能,并优于现有的基于序列的方法和基于网络的中心性度量。最后,我们进行了一些案例研究来说明考虑特定细胞系的必要性和 DeepCellEss 的优越性。我们相信 DeepCellEss 可以作为预测不同细胞系中必需蛋白质的有用工具。
DeepCellEss 的网络服务器可在 http://csuligroup.com:8000/DeepCellEss 访问。本研究的源代码和基础数据可从 https://github.com/CSUBioGroup/DeepCellEss 获得。
补充数据可在《生物信息学》在线获取。