Hebei Machine Vision Engineering Research Center, School of Cyber Security and Computer, Hebei University, Baoding 071002, China.
Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China.
Sensors (Basel). 2022 Dec 8;22(24):9606. doi: 10.3390/s22249606.
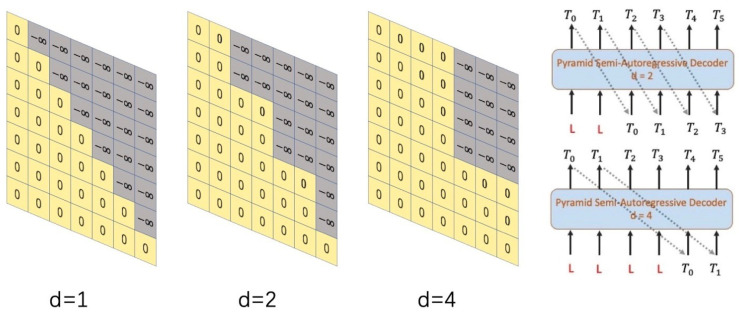
As a typical sequence to sequence task, sign language production (SLP) aims to automatically translate spoken language sentences into the corresponding sign language sequences. The existing SLP methods can be classified into two categories: autoregressive and non-autoregressive SLP. The autoregressive methods suffer from high latency and error accumulation caused by the long-term dependence between current output and the previous poses. And non-autoregressive methods suffer from repetition and omission during the parallel decoding process. To remedy these issues in SLP, we propose a novel method named Pyramid Semi-Autoregressive Transformer with Rich Semantics (PSAT-RS) in this paper. In PSAT-RS, we first introduce a pyramid Semi-Autoregressive mechanism with dividing target sequence into groups in a coarse-to-fine manner, which globally keeps the autoregressive property while locally generating target frames. Meanwhile, the relaxed masked attention mechanism is adopted to make the decoder not only capture the pose sequences in the previous groups, but also pay attention to the current group. Finally, considering the importance of spatial-temporal information, we also design a Rich Semantics embedding (RS) module to encode the sequential information both on time dimension and spatial displacement into the same high-dimensional space. This significantly improves the coordination of joints motion, making the generated sign language videos more natural. Results of our experiments conducted on RWTH-PHOENIX-Weather-2014T and CSL datasets show that the proposed PSAT-RS is competitive to the state-of-the-art autoregressive and non-autoregressive SLP models, achieving a better trade-off between speed and accuracy.
作为一种典型的序列到序列任务,手语生成 (SLP) 旨在自动将口语句子翻译成相应的手语序列。现有的 SLP 方法可分为两类:自回归和非自回归 SLP。自回归方法由于当前输出和前一姿势之间的长期依赖关系,存在高延迟和错误积累的问题。而非自回归方法在并行解码过程中会出现重复和遗漏的问题。为了解决 SLP 中的这些问题,我们在本文中提出了一种名为 Pyramid Semi-Autoregressive Transformer with Rich Semantics (PSAT-RS) 的新方法。在 PSAT-RS 中,我们首先引入了一种金字塔半自回归机制,该机制以粗到细的方式将目标序列划分为组,全局上保持自回归性质,同时局部生成目标帧。同时,采用宽松的掩蔽注意力机制,使解码器不仅可以捕捉到前一组中的姿势序列,还可以关注当前组。最后,考虑到时空信息的重要性,我们还设计了一个丰富语义嵌入 (RS) 模块,将时间维度和空间位移上的序列信息编码到相同的高维空间中。这显著提高了关节运动的协调性,使生成的手语视频更加自然。在 RWTH-PHOENIX-Weather-2014T 和 CSL 数据集上的实验结果表明,所提出的 PSAT-RS 与最先进的自回归和非自回归 SLP 模型具有竞争力,在速度和准确性之间取得了更好的折衷。