Institute for Medical Information Processing, Biometry, and Epidemiology, Ludwig-Maximilians-Universität München, München, Germany.
Munich Center for Machine Learning (MCML), München, Germany.
PLoS Comput Biol. 2023 Jan 6;19(1):e1010820. doi: 10.1371/journal.pcbi.1010820. eCollection 2023 Jan.
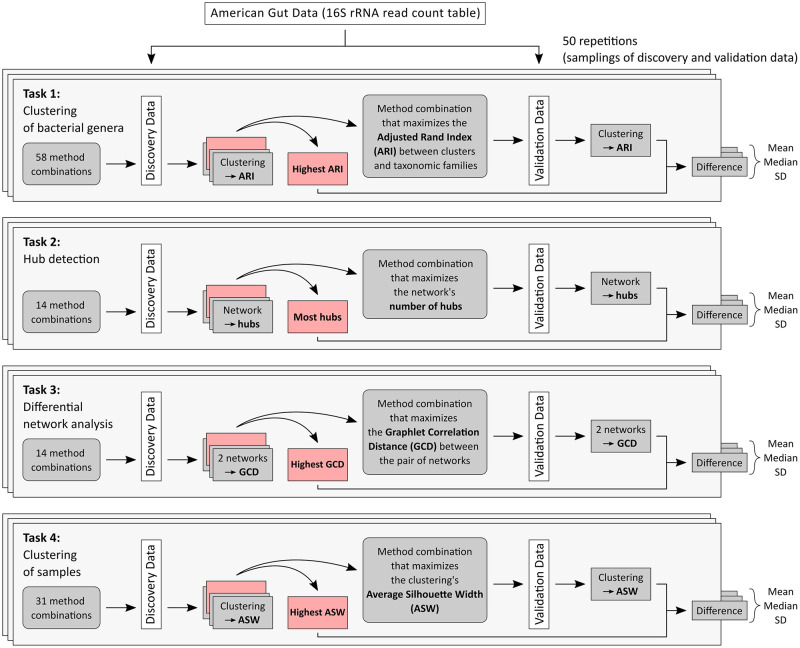
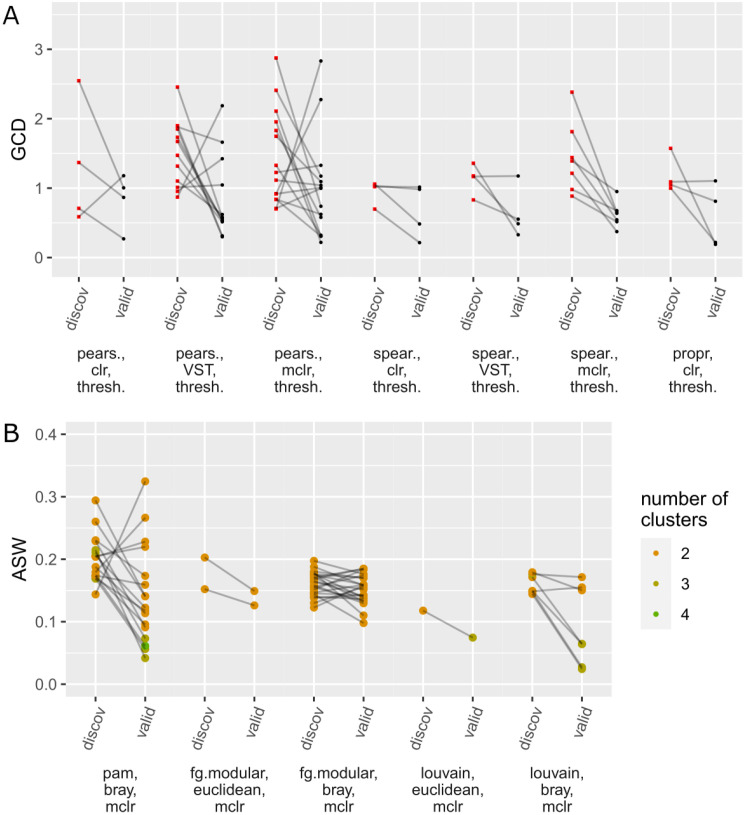
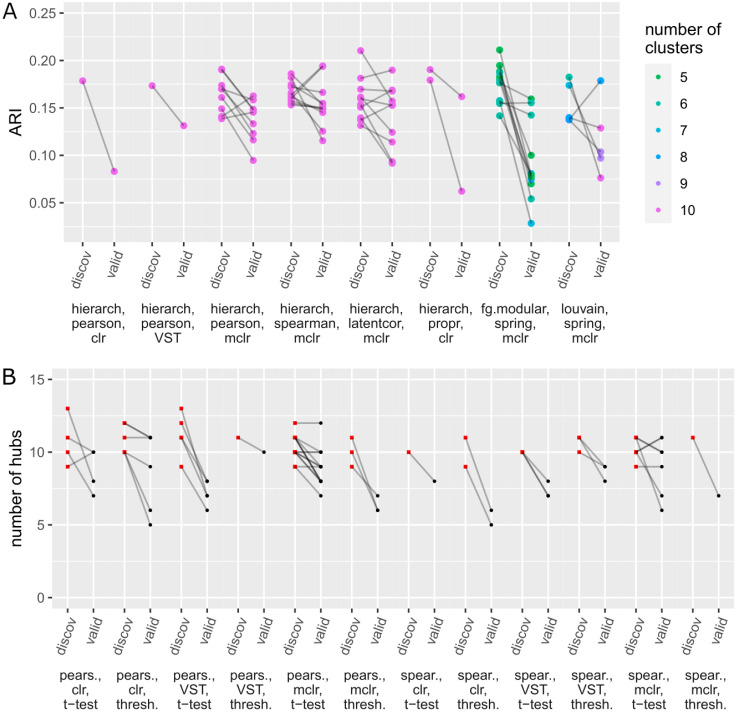
In recent years, unsupervised analysis of microbiome data, such as microbial network analysis and clustering, has increased in popularity. Many new statistical and computational methods have been proposed for these tasks. This multiplicity of analysis strategies poses a challenge for researchers, who are often unsure which method(s) to use and might be tempted to try different methods on their dataset to look for the "best" ones. However, if only the best results are selectively reported, this may cause over-optimism: the "best" method is overly fitted to the specific dataset, and the results might be non-replicable on validation data. Such effects will ultimately hinder research progress. Yet so far, these topics have been given little attention in the context of unsupervised microbiome analysis. In our illustrative study, we aim to quantify over-optimism effects in this context. We model the approach of a hypothetical microbiome researcher who undertakes four unsupervised research tasks: clustering of bacterial genera, hub detection in microbial networks, differential microbial network analysis, and clustering of samples. While these tasks are unsupervised, the researcher might still have certain expectations as to what constitutes interesting results. We translate these expectations into concrete evaluation criteria that the hypothetical researcher might want to optimize. We then randomly split an exemplary dataset from the American Gut Project into discovery and validation sets multiple times. For each research task, multiple method combinations (e.g., methods for data normalization, network generation, and/or clustering) are tried on the discovery data, and the combination that yields the best result according to the evaluation criterion is chosen. While the hypothetical researcher might only report this result, we also apply the "best" method combination to the validation dataset. The results are then compared between discovery and validation data. In all four research tasks, there are notable over-optimism effects; the results on the validation data set are worse compared to the discovery data, averaged over multiple random splits into discovery/validation data. Our study thus highlights the importance of validation and replication in microbiome analysis to obtain reliable results and demonstrates that the issue of over-optimism goes beyond the context of statistical testing and fishing for significance.
近年来,微生物组数据的无监督分析(如微生物网络分析和聚类)越来越受欢迎。针对这些任务,已经提出了许多新的统计和计算方法。这种分析策略的多样性给研究人员带来了挑战,他们通常不确定使用哪种(或哪些)方法,并且可能会尝试在自己的数据集上使用不同的方法来寻找“最佳”方法。然而,如果只选择性地报告最好的结果,这可能会导致过度乐观:“最佳”方法过于适应特定的数据集,并且结果在验证数据上可能不可复制。这些影响最终将阻碍研究进展。然而,到目前为止,这些主题在无监督微生物组分析的背景下很少受到关注。在我们的说明性研究中,我们旨在量化这种情况下的过度乐观效应。我们模拟了一位假设的微生物组研究人员的方法,该研究人员承担了四个无监督研究任务:细菌属聚类、微生物网络中枢纽检测、差异微生物网络分析和样本聚类。虽然这些任务是无监督的,但研究人员可能仍然对什么是有趣的结果有一定的期望。我们将这些期望转化为假设研究人员可能希望优化的具体评估标准。然后,我们将美国肠道计划的一个示例数据集多次随机分为发现集和验证集。对于每个研究任务,我们在发现数据上尝试了多种方法组合(例如,数据标准化、网络生成和/或聚类方法),并根据评估标准选择产生最佳结果的组合。虽然假设研究人员可能只报告此结果,但我们也将“最佳”方法组合应用于验证数据集。然后在发现数据和验证数据之间比较结果。在所有四个研究任务中,都存在明显的过度乐观效应;与发现数据相比,在多个随机划分到发现/验证数据的情况下,验证数据集上的结果更差。因此,我们的研究强调了在微生物组分析中验证和复制的重要性,以获得可靠的结果,并表明过度乐观的问题不仅仅超出了统计检验和寻找显著性的范围。