Weaver Davis T, King Eshan S, Maltas Jeff, Scott Jacob G
Case Western Reserve University School of Medicine, Cleveland, OH, 44106, USA.
Translational Hematology Oncology Research, Cleveland Clinic, Cleveland OH, 44106, USA.
bioRxiv. 2023 Nov 16:2023.01.12.523765. doi: 10.1101/2023.01.12.523765.
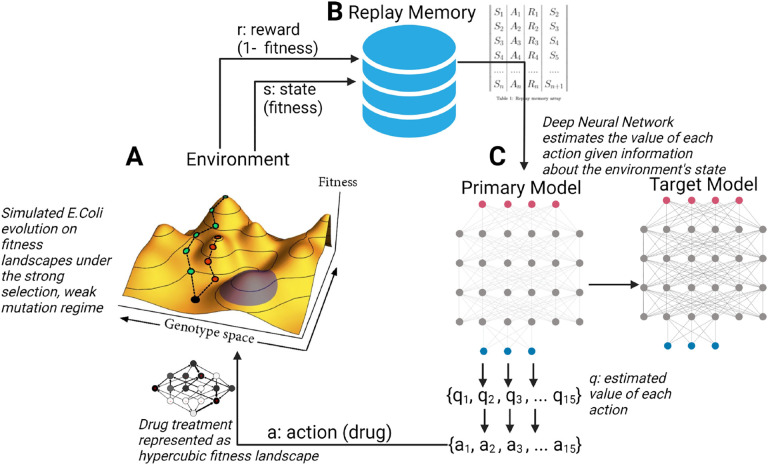
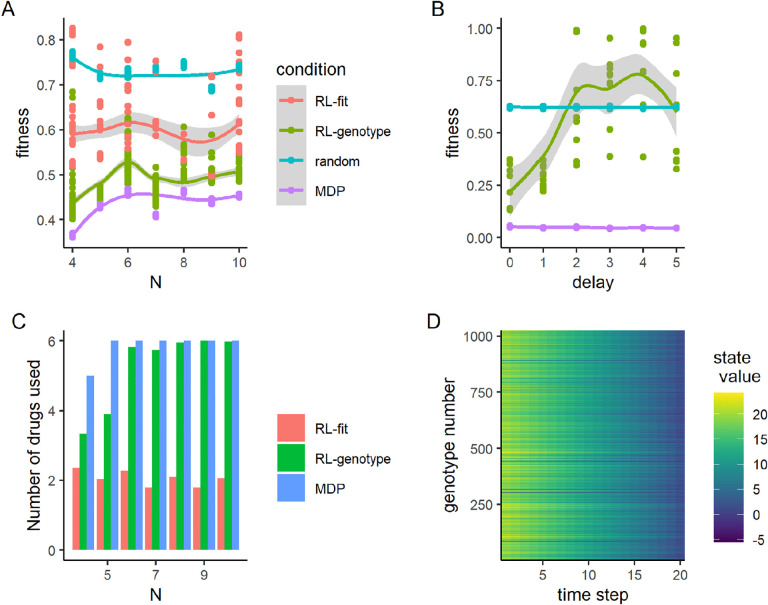
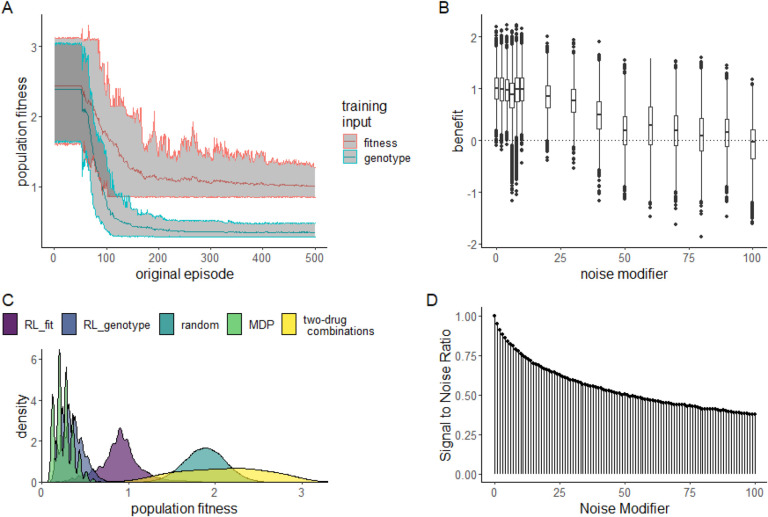
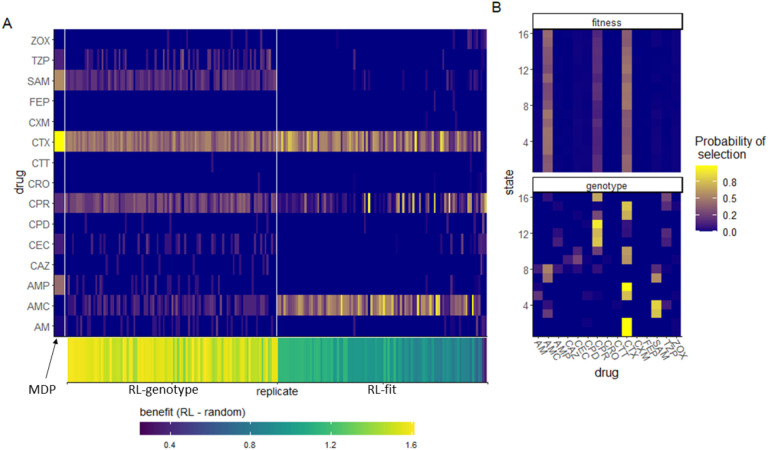
Antimicrobial resistance was estimated to be associated with 4.95 million deaths worldwide in 2019. It is possible to frame the antimicrobial resistance problem as a feedback-control problem. If we could optimize this feedback-control problem and translate our findings to the clinic, we could slow, prevent or reverse the development of high-level drug resistance. Prior work on this topic has relied on systems where the exact dynamics and parameters were known . In this study, we extend this work using a reinforcement learning (RL) approach capable of learning effective drug cycling policies in a system defined by empirically measured fitness landscapes. Crucially, we show that is possible to learn effective drug cycling policies despite the problems of noisy, limited, or delayed measurement. Given access to a panel of 15 -lactam antibiotics with which to treat the simulated population, we demonstrate that RL agents outperform two naive treatment paradigms at minimizing the population fitness over time. We also show that RL agents approach the performance of the optimal drug cycling policy. Even when stochastic noise is introduced to the measurements of population fitness, we show that RL agents are capable of maintaining evolving populations at lower growth rates compared to controls. We further tested our approach in arbitrary fitness landscapes of up to 1024 genotypes. We show that minimization of population fitness using drug cycles is not limited by increasing genome size. Our work represents a proof-of-concept for using AI to control complex evolutionary processes.
据估计,2019年全球有495万人的死亡与抗菌药物耐药性有关。可以将抗菌药物耐药性问题构建为一个反馈控制问题。如果我们能够优化这个反馈控制问题,并将研究结果应用于临床,就可以减缓、预防或逆转高水平耐药性的发展。此前关于这个主题的研究依赖于已知确切动态和参数的系统。在本研究中,我们使用强化学习(RL)方法扩展了这项工作,该方法能够在由经验测量的适应度景观定义的系统中学习有效的药物循环策略。至关重要的是,我们表明,尽管存在测量噪声、测量有限或测量延迟等问题,但仍有可能学习到有效的药物循环策略。在有一组15种β-内酰胺抗生素可用于治疗模拟种群的情况下,我们证明强化学习智能体在随时间最小化种群适应度方面优于两种简单的治疗范式。我们还表明,强化学习智能体接近最优药物循环策略的性能。即使在种群适应度测量中引入随机噪声,我们也表明,与对照组相比,强化学习智能体能够使不断进化的种群维持在较低的增长率。我们在多达1024个基因型的任意适应度景观中进一步测试了我们的方法。我们表明,使用药物循环最小化种群适应度不受基因组大小增加的限制。我们的工作代表了使用人工智能控制复杂进化过程的概念验证。