National Security Directorate, Pacific Northwest National Laboratory, Richland, Washington, USA.
Physical and Computational Sciences Directorate, Pacific Northwest National Laboratory, Richland, Washington, USA.
Protein Sci. 2023 Mar;32(3):e4591. doi: 10.1002/pro.4591.
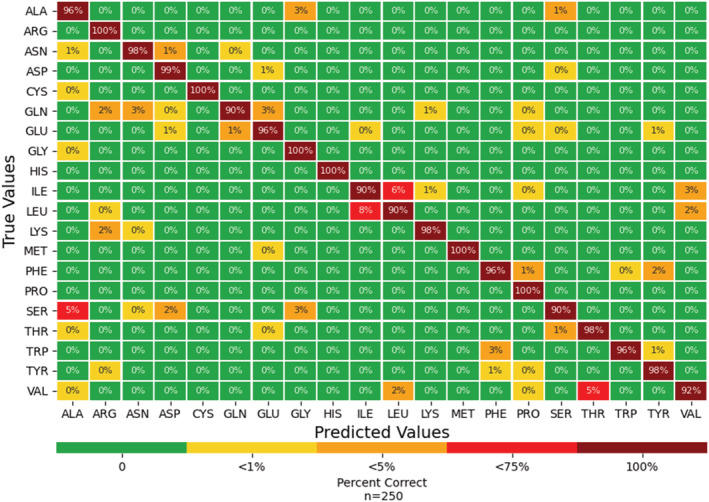
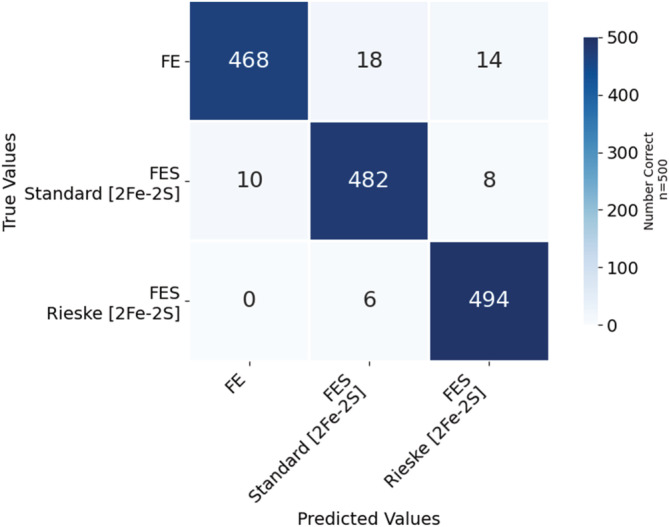
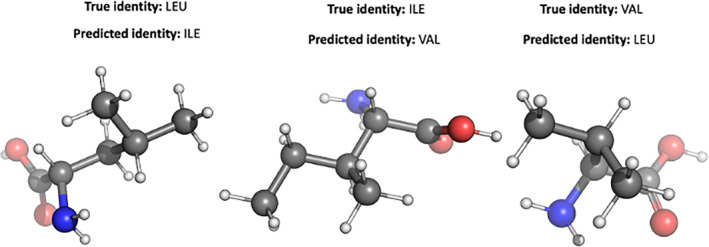
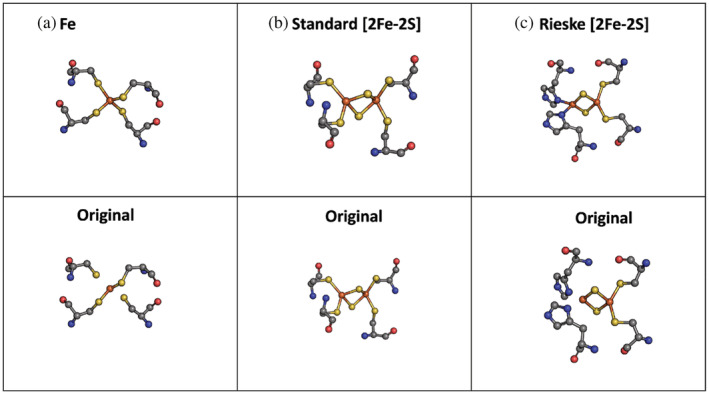
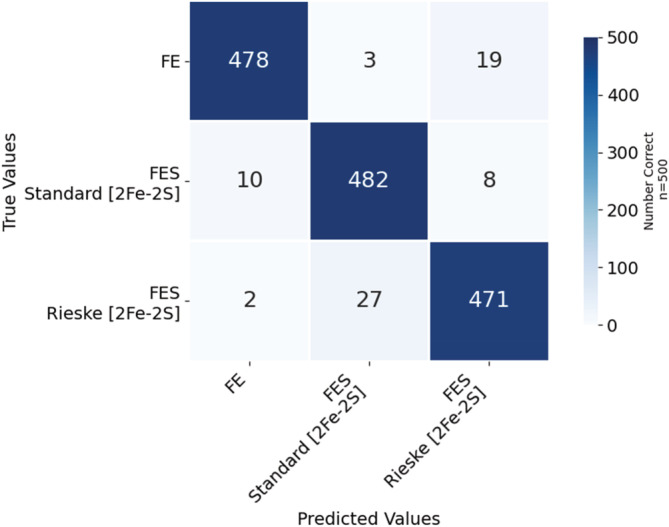
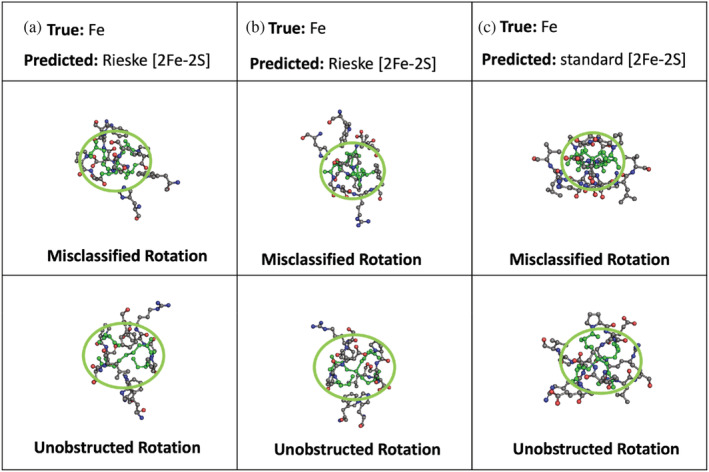
To advance our ability to predict impacts of the protein scaffold on catalysis, robust classification schemes to define features of proteins that will influence reactivity are needed. One of these features is a protein's metal-binding ability, as metals are critical to catalytic conversion by metalloenzymes. As a step toward realizing this goal, we used convolutional neural networks (CNNs) to enable the classification of a metal cofactor binding pocket within a protein scaffold. CNNs enable images to be classified based on multiple levels of detail in the image, from edges and corners to entire objects, and can provide rapid classification. First, six CNN models were fine-tuned to classify the 20 standard amino acids to choose a performant model for amino acid classification. This model was then trained in two parallel efforts: to classify a 2D image of the environment within a given radius of the central metal binding site, either an Fe ion or a [2Fe-2S] cofactor, with the metal visible (effort 1) or the metal hidden (effort 2). We further used two sub-classifications of the [2Fe-2S] cofactor: (1) a standard [2Fe-2S] cofactor and (2) a Rieske [2Fe-2S] cofactor. The accuracy for the model correctly identifying all three defined features was >95%, despite our perception of the increased challenge of the metalloenzyme identification. This demonstrates that machine learning methodology to classify and distinguish similar metal-binding sites, even in the absence of a visible cofactor, is indeed possible and offers an additional tool for metal-binding site identification in proteins.
为了提高我们预测蛋白质支架对催化影响的能力,需要有强大的分类方案来定义影响反应性的蛋白质特征。这些特征之一是蛋白质的金属结合能力,因为金属对金属酶的催化转化至关重要。作为实现这一目标的一步,我们使用卷积神经网络(CNN)来对蛋白质支架中的金属辅因子结合口袋进行分类。CNN 可以根据图像中的多个细节级别对图像进行分类,从边缘和角落到整个对象,并且可以提供快速分类。首先,我们微调了六个 CNN 模型来对 20 个标准氨基酸进行分类,以选择用于氨基酸分类的高性能模型。然后,我们使用两种并行的方法来训练这个模型:(1)在给定的中央金属结合位点的半径内,对一个给定半径内的环境的 2D 图像进行分类,要么是 Fe 离子,要么是 [2Fe-2S] 辅因子,金属是可见的(努力 1),要么是金属隐藏的(努力 2);(2)对 [2Fe-2S] 辅因子进行两个子类别的分类:(1)标准 [2Fe-2S] 辅因子和(2) Rieske [2Fe-2S] 辅因子。尽管我们认为鉴定金属酶的难度增加,但该模型正确识别所有三个定义特征的准确率>95%。这表明,即使在没有可见辅因子的情况下,使用机器学习方法对类似的金属结合位点进行分类和区分确实是可能的,并为蛋白质中的金属结合位点鉴定提供了另一种工具。