Lenski Marie, Maallem Saïd, Zarcone Gianni, Garçon Guillaume, Lo-Guidice Jean-Marc, Anthérieu Sébastien, Allorge Delphine
ULR 4483, IMPECS-IMPact de l'Environnement Chimique sur la Santé humaine, CHU Lille, Institut Pasteur de Lille, Université de Lille, F-59000 Lille, France.
CHU Lille, Unité Fonctionnelle de Toxicologie, F-59037 Lille, France.
Metabolites. 2023 Feb 15;13(2):282. doi: 10.3390/metabo13020282.
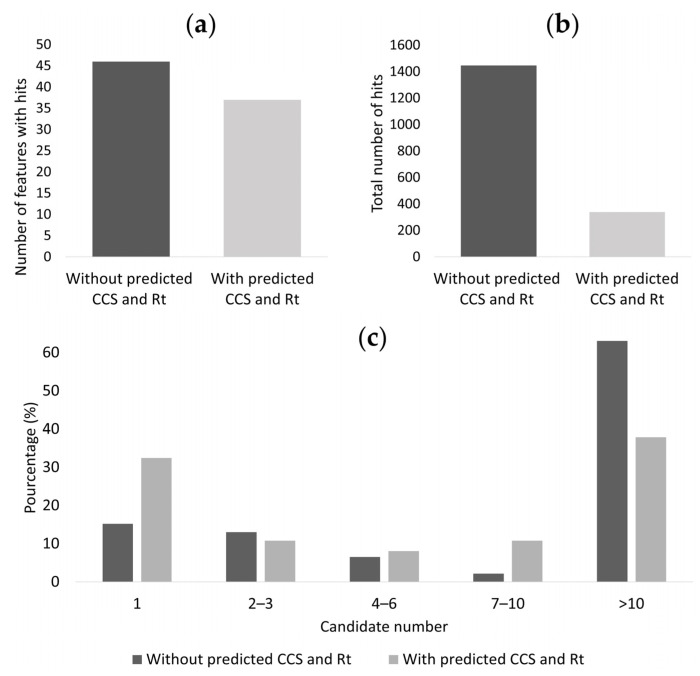
Metabolite identification in untargeted metabolomics is complex, with the risk of false positive annotations. This work aims to use machine learning to successively predict the retention time (Rt) and the collision cross-section (CCS) of an open-access database to accelerate the interpretation of metabolomic results. Standards of metabolites were tested using liquid chromatography coupled with high-resolution mass spectrometry. In CCSBase and QSRR predictor machine learning models, experimental results were used to generate predicted CCS and Rt of the Human Metabolome Database. From 542 standards, 266 and 301 compounds were detected in positive and negative electrospray ionization mode, respectively, corresponding to 380 different metabolites. CCS and Rt were then predicted using machine learning tools for almost 114,000 metabolites. R score of the linear regression between predicted and measured data achieved 0.938 and 0.898 for CCS and Rt, respectively, demonstrating the models' reliability. A CCS and Rt index filter of mean error ± 2 standard deviations could remove most misidentifications. Its application to data generated from a toxicology study on tobacco cigarettes reduced hits by 76%. Regarding the volume of data produced by metabolomics, the practical workflow provided allows for the implementation of valuable large-scale databases to improve the biological interpretation of metabolomics data.
非靶向代谢组学中的代谢物鉴定很复杂,存在假阳性注释的风险。这项工作旨在利用机器学习依次预测开放获取数据库的保留时间(Rt)和碰撞截面(CCS),以加速代谢组学结果的解读。使用液相色谱与高分辨率质谱联用对代谢物标准品进行检测。在CCSBase和QSRR预测器机器学习模型中,利用实验结果生成人类代谢组数据库的预测CCS和Rt。在542种标准品中,分别在正离子和负离子电喷雾电离模式下检测到266种和301种化合物,对应380种不同的代谢物。然后使用机器学习工具对近114,000种代谢物的CCS和Rt进行预测。预测数据与实测数据之间的线性回归R值,CCS和Rt分别达到0.938和0.898,证明了模型的可靠性。平均误差±2个标准差的CCS和Rt指数过滤器可以去除大多数错误鉴定。将其应用于烟草毒理学研究产生的数据,命中次数减少了76%。鉴于代谢组学产生的数据量,所提供的实际工作流程允许实施有价值的大规模数据库,以改善代谢组学数据的生物学解读。