Han Shixing, Liu Jin, Zhang Jinyingming, Gong Peizhu, Zhang Xiliang, He Huihua
College of Information Engineering, Shanghai Maritime University, Shanghai, 201306 China.
College of Early Childhood Education, Shanghai Normal University, Shanghai, 200234 China.
Complex Intell Systems. 2023 Feb 24:1-18. doi: 10.1007/s40747-023-00998-5.
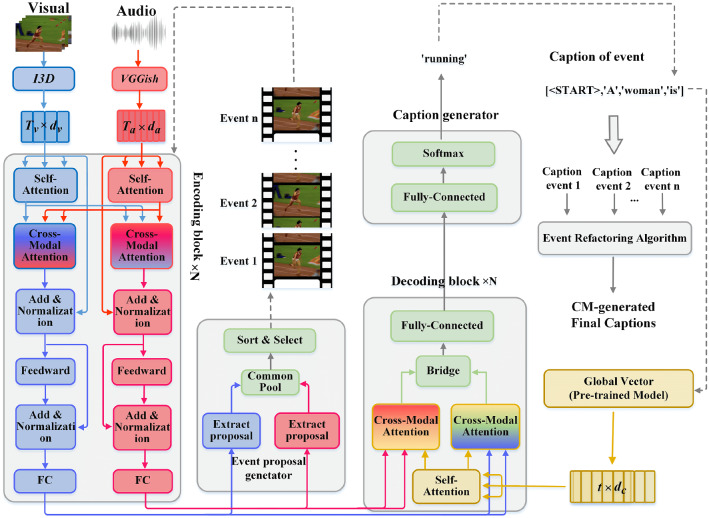
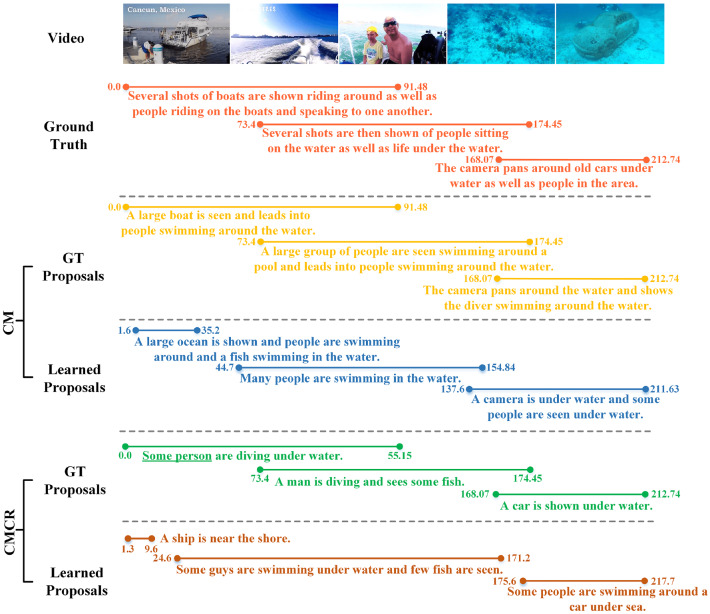
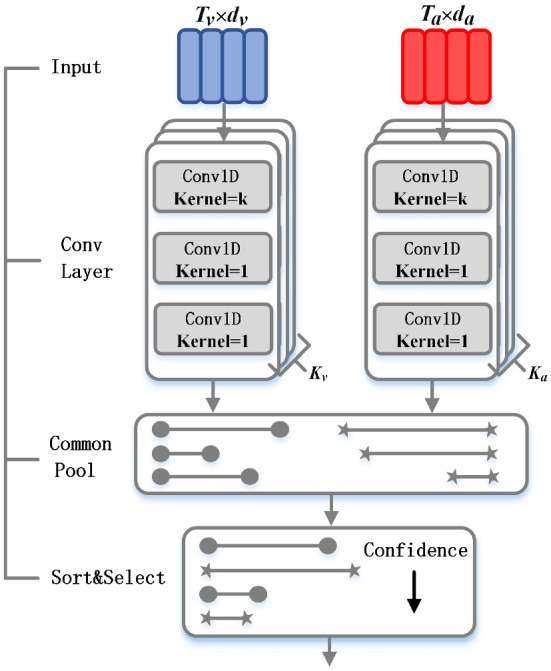
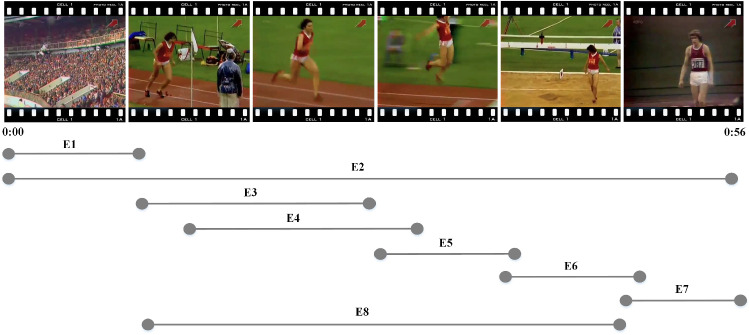
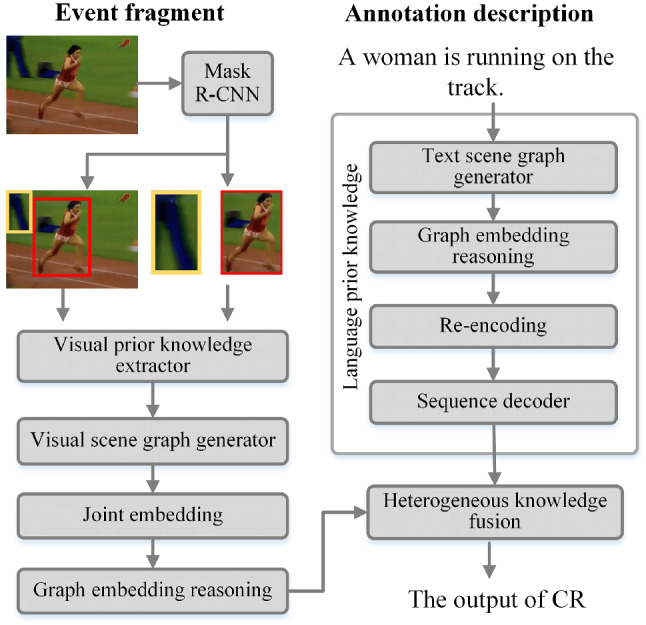
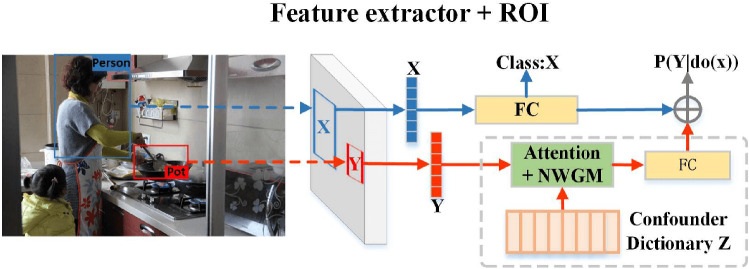
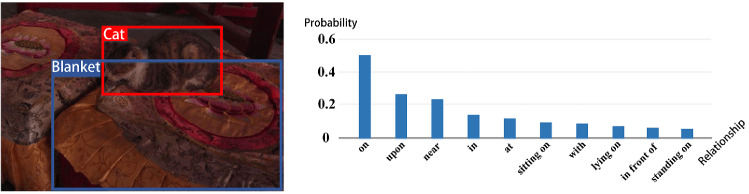
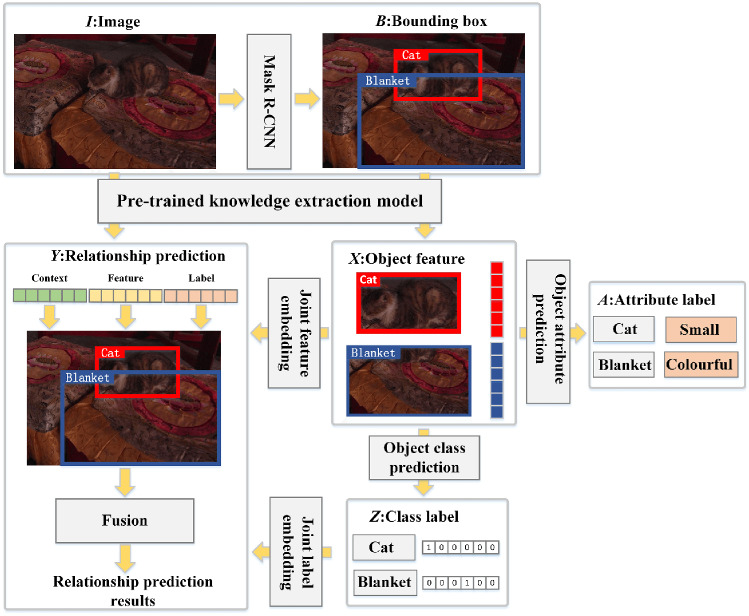
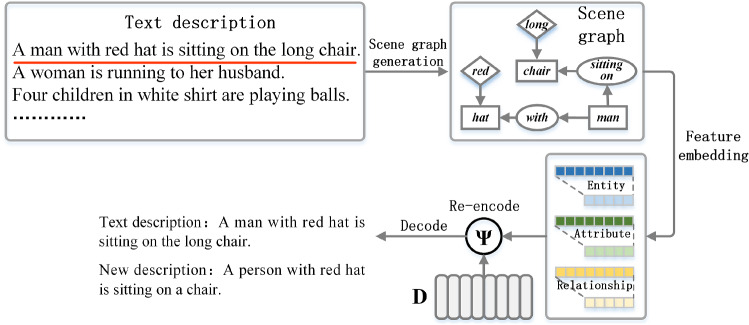
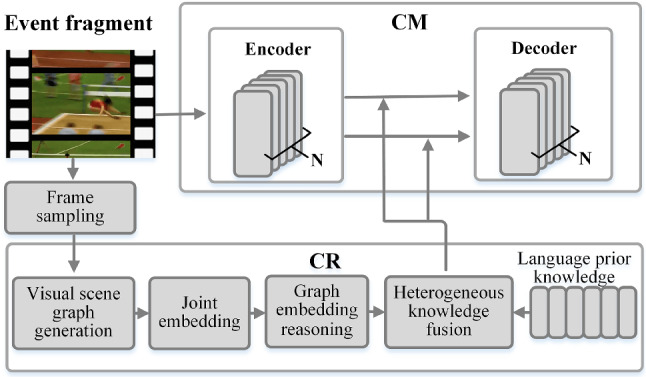
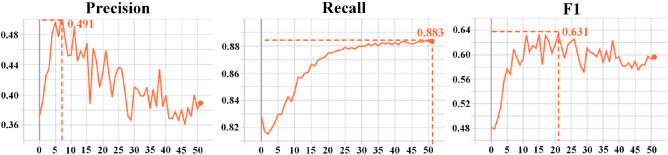
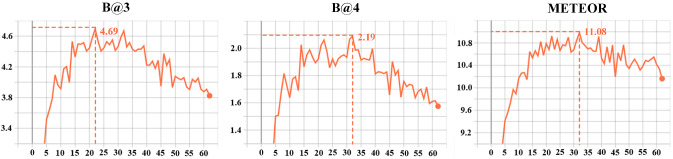
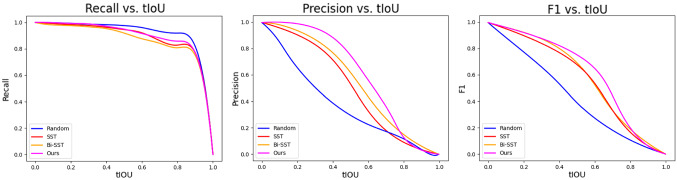
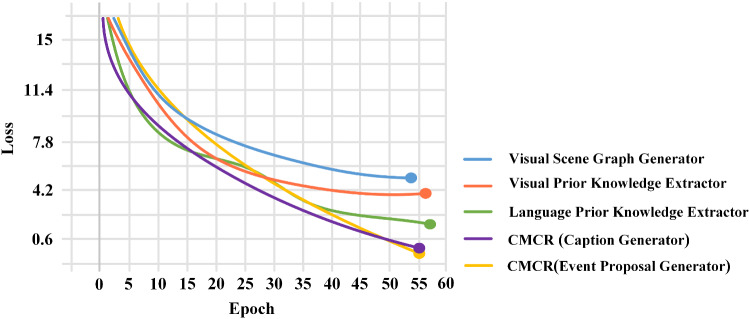
Dense video captioning (DVC) aims at generating description for each scene in a video. Despite attractive progress for this task, previous works usually only concentrate on exploiting visual features while neglecting audio information in the video, resulting in inaccurate scene event location. In this article, we propose a novel DVC model named CMCR, which is mainly composed of a cross-modal processing (CM) module and a commonsense reasoning (CR) module. CM utilizes a cross-modal attention mechanism to encode data in different modalities. An event refactoring algorithm is proposed to deal with inaccurate event localization caused by overlapping events. Besides, a shared encoder is utilized to reduce model redundancy. CR optimizes the logic of generated captions with both heterogeneous prior knowledge and entities' association reasoning achieved by building a knowledge-enhanced unbiased scene graph. Extensive experiments are conducted on ActivityNet Captions dataset, the results demonstrate that our model achieves better performance than state-of-the-art methods. To better understand the performance achieved by CMCR, we also apply ablation experiments to analyze the contributions of different modules.
密集视频字幕(DVC)旨在为视频中的每个场景生成描述。尽管这项任务取得了引人注目的进展,但以往的工作通常只专注于利用视觉特征,而忽略了视频中的音频信息,导致场景事件定位不准确。在本文中,我们提出了一种名为CMCR的新型DVC模型,它主要由跨模态处理(CM)模块和常识推理(CR)模块组成。CM利用跨模态注意力机制对不同模态的数据进行编码。提出了一种事件重构算法来处理由重叠事件导致的不准确事件定位。此外,还使用了一个共享编码器来减少模型冗余。CR通过构建知识增强的无偏场景图实现的异构先验知识和实体关联推理来优化生成字幕的逻辑。在ActivityNet Captions数据集上进行了大量实验,结果表明我们的模型比现有方法具有更好的性能。为了更好地理解CMCR所取得的性能,我们还进行了消融实验来分析不同模块的贡献。