Faculty of Computer Science, Otto-von-Guericke-University Magdeburg, Universitätsplatz 2, 39106, Magdeburg, Germany.
Faculty of Process and Systems Engineering, Otto-von-Guericke-University Magdeburg, Universitätsplatz 2, 39106, Magdeburg, Germany.
BMC Med Inform Decis Mak. 2023 Mar 6;22(Suppl 6):347. doi: 10.1186/s12911-023-02112-8.
Graph databases enable efficient storage of heterogeneous, highly-interlinked data, such as clinical data. Subsequently, researchers can extract relevant features from these datasets and apply machine learning for diagnosis, biomarker discovery, or understanding pathogenesis.
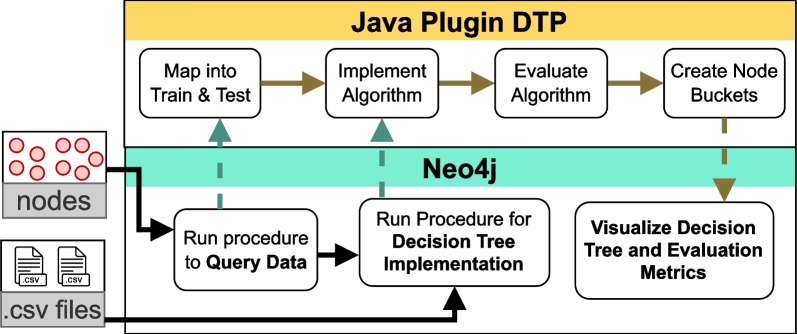
To facilitate machine learning and save time for extracting data from the graph database, we developed and optimized Decision Tree Plug-in (DTP) containing 24 procedures to generate and evaluate decision trees directly in the graph database Neo4j on homogeneous and unconnected nodes.
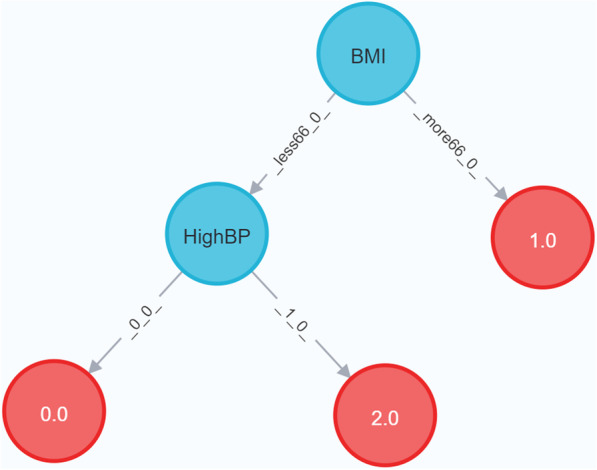
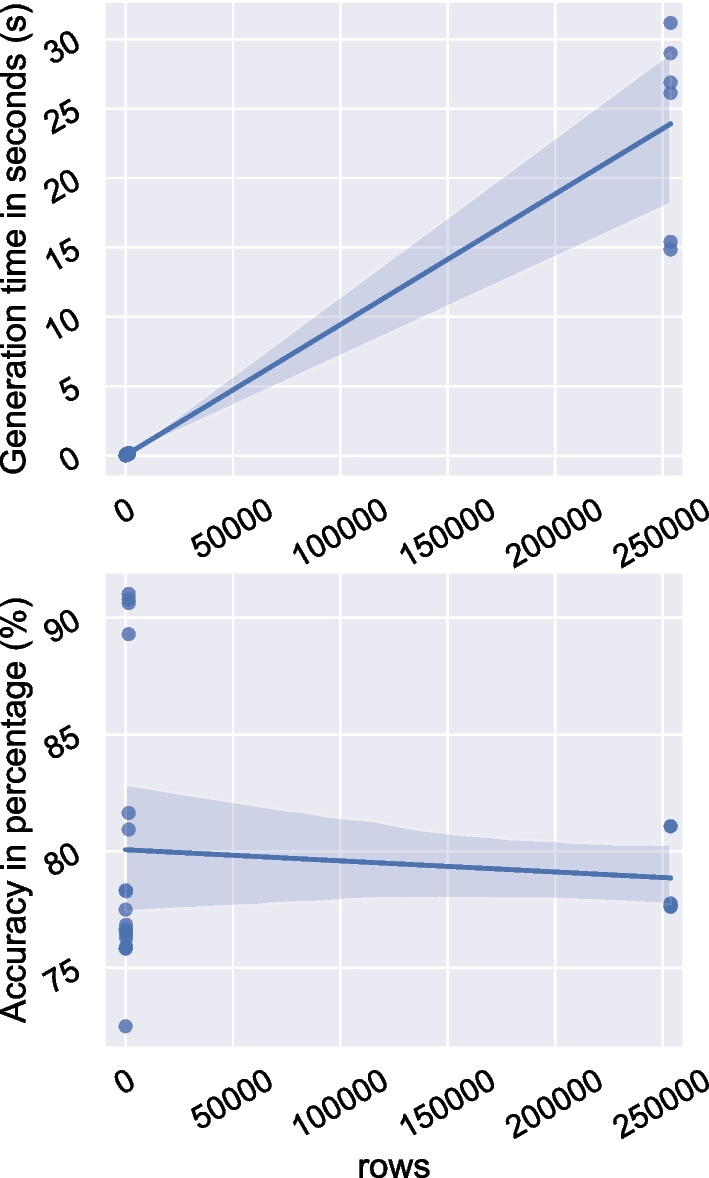
Creation of the decision tree for three clinical datasets directly in the graph database from the nodes required between 0.059 and 0.099 s, while calculating the decision tree with the same algorithm in Java from CSV files took 0.085-0.112 s. Furthermore, our approach was faster than the standard decision tree implementations in R (0.62 s) and equal to Python (0.08 s), also using CSV files as input for small datasets. In addition, we have explored the strengths of DTP by evaluating a large dataset (approx. 250,000 instances) to predict patients with diabetes and compared the performance against algorithms generated by state-of-the-art packages in R and Python. By doing so, we have been able to show competitive results on the performance of Neo4j, in terms of quality of predictions as well as time efficiency. Furthermore, we could show that high body-mass index and high blood pressure are the main risk factors for diabetes.
Overall, our work shows that integrating machine learning into graph databases saves time for additional processes as well as external memory, and could be applied to a variety of use cases, including clinical applications. This provides user with the advantages of high scalability, visualization and complex querying.
图数据库能够高效存储异构的、高度关联的数据,如临床数据。随后,研究人员可以从这些数据集提取相关特征,并应用机器学习进行诊断、生物标志物发现或了解发病机制。
为了便于机器学习并节省从图数据库中提取数据的时间,我们开发并优化了决策树插件(Decision Tree Plug-in,DTP),其中包含 24 个过程,可直接在图数据库 Neo4j 中的同构和无连接节点上生成和评估决策树。
直接从图数据库中的节点创建三个临床数据集的决策树所需时间为 0.059 到 0.099 秒,而使用相同算法从 CSV 文件计算决策树则需要 0.085 到 0.112 秒。此外,对于小数据集,我们的方法比 R 中的标准决策树实现(0.62 秒)和 Python (0.08 秒)更快。此外,我们通过评估一个包含大约 250,000 个实例的大型数据集来探索 DTP 的优势,以预测糖尿病患者,并将性能与 R 和 Python 中的最新软件包生成的算法进行比较。通过这样做,我们能够展示 Neo4j 在预测质量和时间效率方面的竞争结果。此外,我们还可以表明,高体重指数和高血压是糖尿病的主要危险因素。
总的来说,我们的工作表明,将机器学习集成到图数据库中可以节省额外的处理时间和外部内存,并且可以应用于各种用例,包括临床应用。这为用户提供了高可扩展性、可视化和复杂查询的优势。