Division of Cardiovascular Medicine and Cardiovascular Institute Stanford University Stanford CA.
Department of Cardiovascular Medicine Cleveland Clinic Foundation Cleveland OH.
J Am Heart Assoc. 2023 Apr 4;12(7):e028120. doi: 10.1161/JAHA.122.028120. Epub 2023 Mar 28.
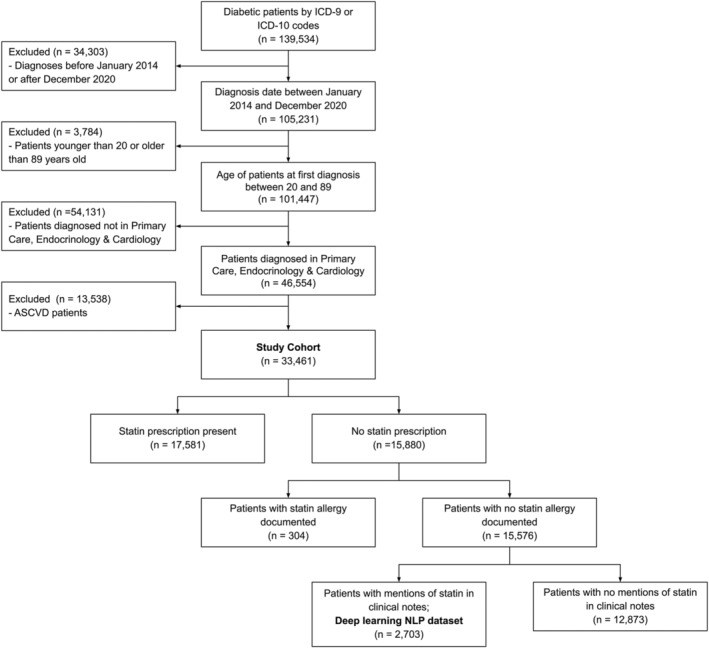
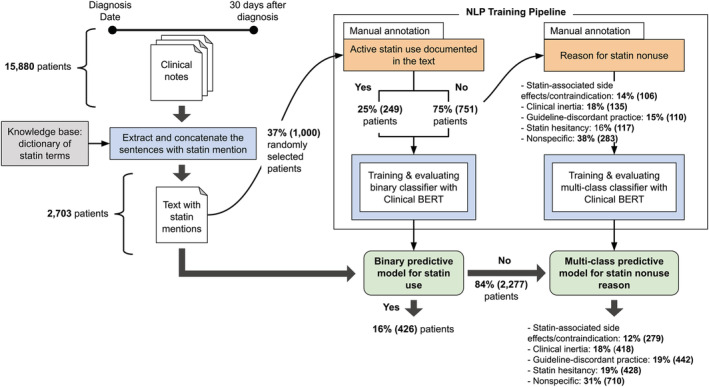
Background Statins are guideline-recommended medications that reduce cardiovascular events in patients with diabetes. Yet, statin use is concerningly low in this high-risk population. Identifying reasons for statin nonuse, which are typically described in unstructured electronic health record data, can inform targeted system interventions to improve statin use. We aimed to leverage a deep learning approach to identify reasons for statin nonuse in patients with diabetes. Methods and Results Adults with diabetes and no statin prescriptions were identified from a multiethnic, multisite Northern California electronic health record cohort from 2014 to 2020. We used a benchmark deep learning natural language processing approach (Clinical Bidirectional Encoder Representations from Transformers) to identify statin nonuse and reasons for statin nonuse from unstructured electronic health record data. Performance was evaluated against expert clinician review from manual annotation of clinical notes and compared with other natural language processing approaches. Of 33 461 patients with diabetes (mean age 59±15 years, 49% women, 36% White patients, 24% Asian patients, and 15% Hispanic patients), 47% (15 580) had no statin prescriptions. From unstructured data, Clinical Bidirectional Encoder Representations from Transformers accurately identified statin nonuse (area under receiver operating characteristic curve [AUC] 0.99 [0.98-1.0]) and key patient (eg, side effects/contraindications), clinician (eg, guideline-discordant practice), and system reasons (eg, clinical inertia) for statin nonuse (AUC 0.90 [0.86-0.93]) and outperformed other natural language processing approaches. Reasons for nonuse varied by clinical and demographic characteristics, including race and ethnicity. Conclusions A deep learning algorithm identified statin nonuse and actionable reasons for statin nonuse in patients with diabetes. Findings may enable targeted interventions to improve guideline-directed statin use and be scaled to other evidence-based therapies.
他汀类药物是指南推荐的药物,可降低糖尿病患者的心血管事件。然而,在这一高危人群中,他汀类药物的使用率令人担忧。识别他汀类药物未使用的原因(通常在非结构化电子健康记录数据中描述)可以为有针对性的系统干预措施提供信息,以改善他汀类药物的使用。我们旨在利用深度学习方法来识别糖尿病患者他汀类药物未使用的原因。
从 2014 年至 2020 年,从加利福尼亚州北部一个多民族、多地点的电子健康记录队列中确定了没有他汀类药物处方的糖尿病成人患者。我们使用基准深度学习自然语言处理方法(临床双向编码器表示来自转换器)从非结构化电子健康记录数据中识别他汀类药物未使用的原因和他汀类药物未使用的原因。通过对临床笔记进行手动注释,由专家临床医生进行评估来评估性能,并与其他自然语言处理方法进行比较。在 33461 名患有糖尿病的患者(平均年龄 59±15 岁,49%为女性,36%为白人患者,24%为亚裔患者,15%为西班牙裔患者)中,有 47%(15580 人)没有他汀类药物处方。从非结构化数据中,临床双向编码器表示来自转换器可以准确识别他汀类药物未使用(接收者操作特征曲线下面积[AUROC]0.99[0.98-1.0])和关键患者(例如,副作用/禁忌症)、临床医生(例如,与指南不符的做法)和系统原因(例如,临床惰性)他汀类药物未使用(AUROC 0.90[0.86-0.93]),并优于其他自然语言处理方法。未使用的原因因临床和人口统计学特征而异,包括种族和民族。
深度学习算法识别了糖尿病患者的他汀类药物未使用情况和他汀类药物未使用的可操作原因。这些发现可能使有针对性的干预措施能够改善基于指南的他汀类药物使用,并扩展到其他循证疗法。