Manley William, Tran Tam, Prusinski Melissa, Brisson Dustin
University of Pennsylvania.
New York State Department of Health (NYSDOH).
bioRxiv. 2023 Nov 29:2023.03.13.532443. doi: 10.1101/2023.03.13.532443.
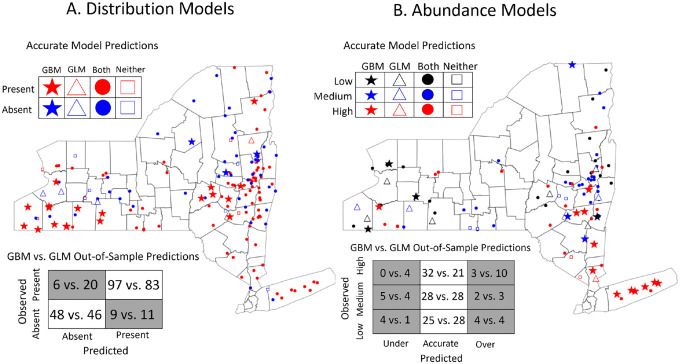
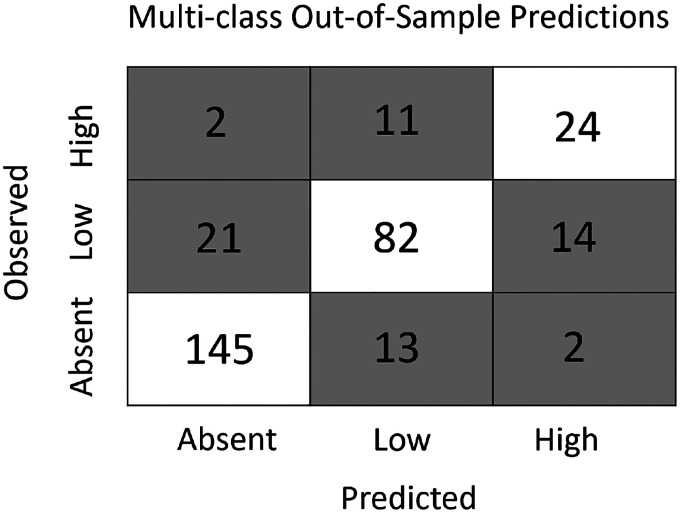
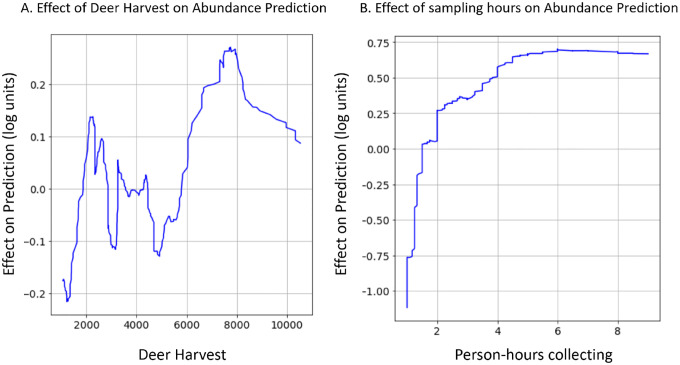
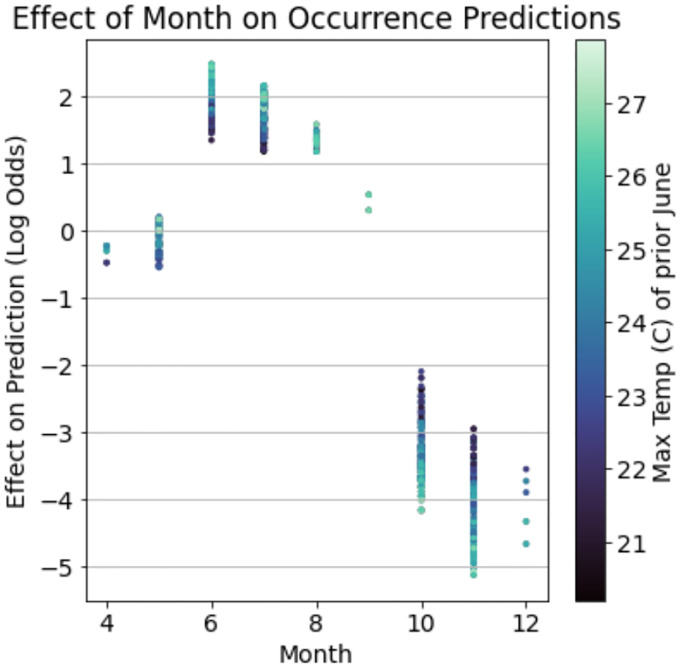
General linear models have been the foundational statistical framework used to discover the ecological processes that explain the distribution and abundance of natural populations. Analyses of the rapidly expanding cache of environmental and ecological data, however, require advanced statistical methods to contend with complexities inherent to extremely large natural data sets. Modern machine learning frameworks such as gradient boosted trees efficiently identify complex ecological relationships in massive data sets, which are expected to result in accurate predictions of the distribution and abundance of organisms in nature. However, rigorous assessments of the theoretical advantages of these methodologies on natural data sets are rare. Here we compare the abilities of gradient boosted and linear models to identify environmental features that explain observed variations in the distribution and abundance of blacklegged tick () populations in a data set collected across New York State over a ten-year period. The gradient boosted and linear models use similar environmental features to explain tick demography, although the gradient boosted models found non-linear relationships and interactions that are difficult to anticipate and often impractical to identify with a linear modeling framework. Further, the gradient boosted models predicted the distribution and abundance of ticks in years and areas beyond the training data with much greater accuracy than their linear model counterparts. The flexible gradient boosting framework also permitted additional model types that provide practical advantages for tick surveillance and public health. The results highlight the potential of gradient boosted models to discover novel ecological phenomena affecting pathogen demography and as a powerful public health tool to mitigate disease risks.
一般线性模型一直是用于发现解释自然种群分布和丰度的生态过程的基础统计框架。然而,对迅速扩充的环境和生态数据集进行分析,需要先进的统计方法来应对超大型自然数据集固有的复杂性。诸如梯度提升树等现代机器学习框架能够在海量数据集中高效识别复杂的生态关系,有望准确预测自然界中生物的分布和丰度。然而,对这些方法在自然数据集上的理论优势进行严格评估的情况却很少见。在此,我们比较了梯度提升模型和线性模型识别环境特征的能力,这些环境特征可解释在纽约州十年间收集的数据集中黑腿蜱()种群分布和丰度的观测变化。梯度提升模型和线性模型使用相似的环境特征来解释蜱虫种群统计学特征,不过梯度提升模型发现了非线性关系和相互作用,这些关系难以预测,在线性建模框架下往往也难以识别。此外,梯度提升模型在预测训练数据之外的年份和区域的蜱虫分布和丰度时,比对应的线性模型精确得多。灵活的梯度提升框架还允许使用其他模型类型,这些模型类型在蜱虫监测和公共卫生方面具有实际优势。研究结果凸显了梯度提升模型在发现影响病原体种群统计学特征的新生态现象方面的潜力,以及作为减轻疾病风险的强大公共卫生工具的潜力。