Basque Center for Applied Mathematics (BCAM), Bilbao, Basque Country, Spain.
Department of Electronic Technology, University of the Basque Country (UPV/EHU), Leioa, Basque Country, Spain.
PLoS One. 2023 Apr 13;18(4):e0284150. doi: 10.1371/journal.pone.0284150. eCollection 2023.
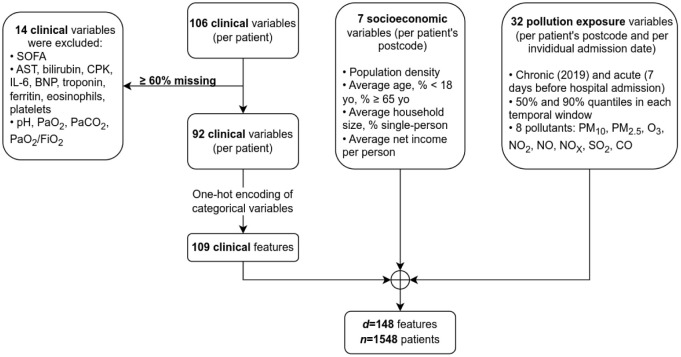
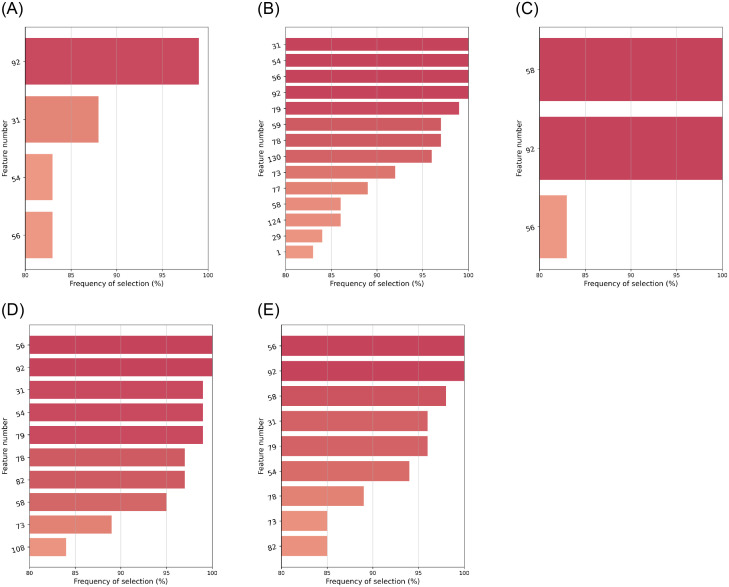
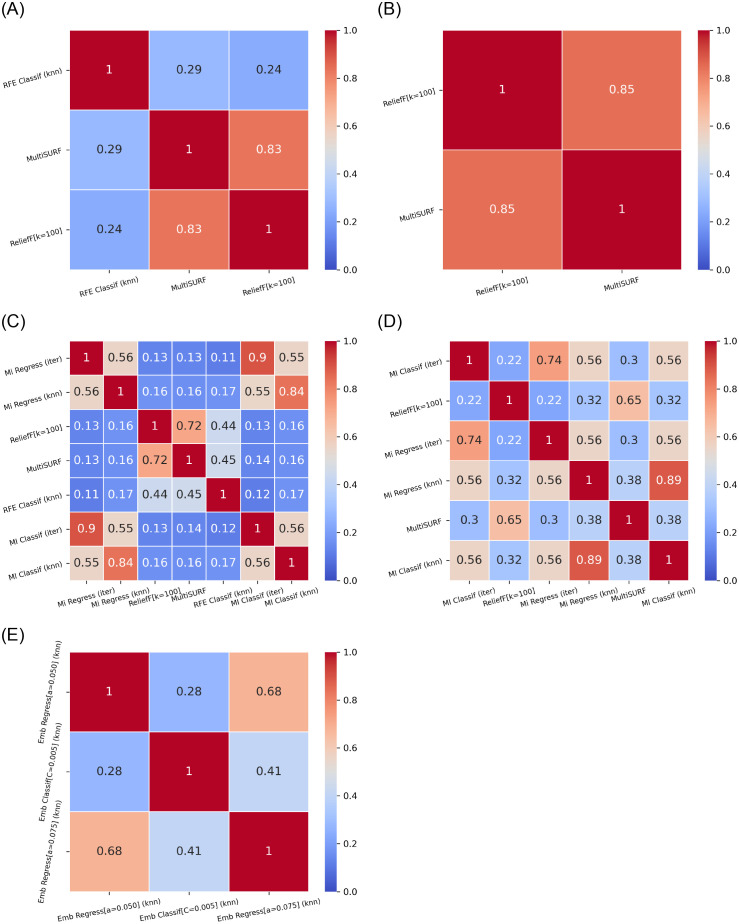
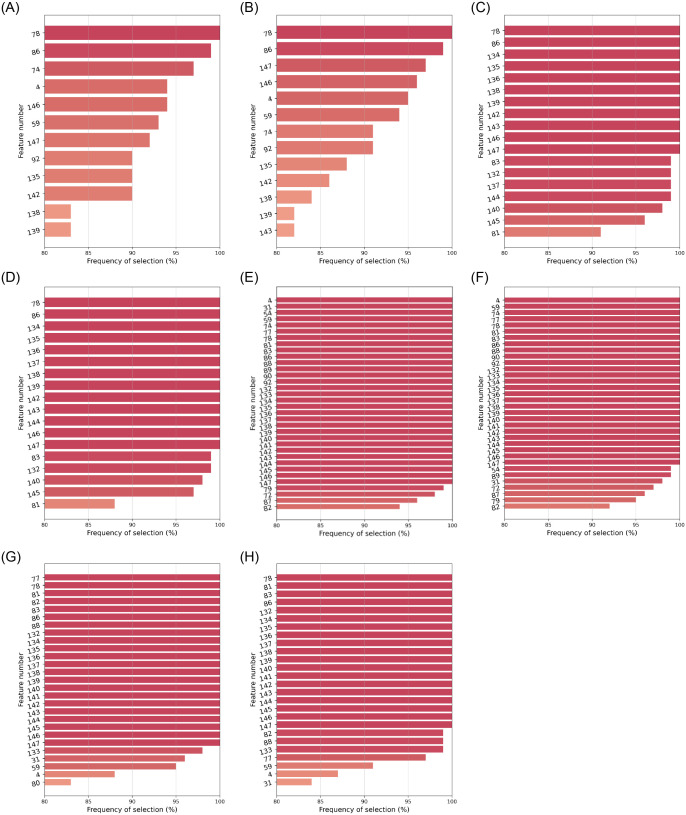
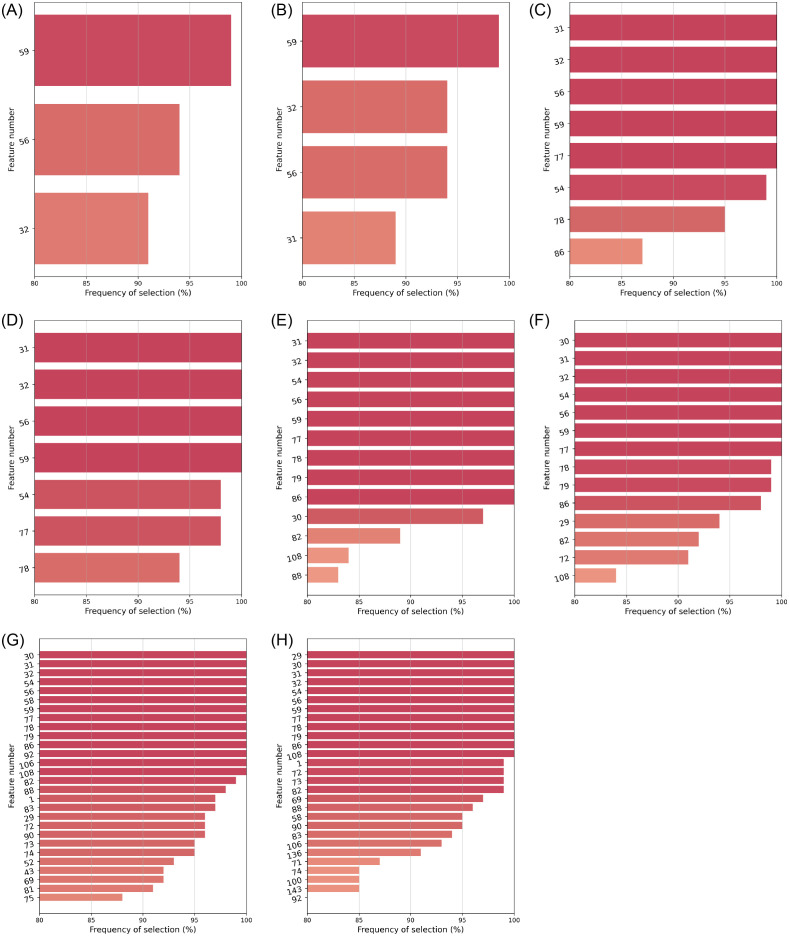
With the COVID-19 pandemic having caused unprecedented numbers of infections and deaths, large research efforts have been undertaken to increase our understanding of the disease and the factors which determine diverse clinical evolutions. Here we focused on a fully data-driven exploration regarding which factors (clinical or otherwise) were most informative for SARS-CoV-2 pneumonia severity prediction via machine learning (ML). In particular, feature selection techniques (FS), designed to reduce the dimensionality of data, allowed us to characterize which of our variables were the most useful for ML prognosis. We conducted a multi-centre clinical study, enrolling n = 1548 patients hospitalized due to SARS-CoV-2 pneumonia: where 792, 238, and 598 patients experienced low, medium and high-severity evolutions, respectively. Up to 106 patient-specific clinical variables were collected at admission, although 14 of them had to be discarded for containing ⩾60% missing values. Alongside 7 socioeconomic attributes and 32 exposures to air pollution (chronic and acute), these became d = 148 features after variable encoding. We addressed this ordinal classification problem both as a ML classification and regression task. Two imputation techniques for missing data were explored, along with a total of 166 unique FS algorithm configurations: 46 filters, 100 wrappers and 20 embeddeds. Of these, 21 setups achieved satisfactory bootstrap stability (⩾0.70) with reasonable computation times: 16 filters, 2 wrappers, and 3 embeddeds. The subsets of features selected by each technique showed modest Jaccard similarities across them. However, they consistently pointed out the importance of certain explanatory variables. Namely: patient's C-reactive protein (CRP), pneumonia severity index (PSI), respiratory rate (RR) and oxygen levels -saturation Sp O2, quotients Sp O2/RR and arterial Sat O2/Fi O2-, the neutrophil-to-lymphocyte ratio (NLR) -to certain extent, also neutrophil and lymphocyte counts separately-, lactate dehydrogenase (LDH), and procalcitonin (PCT) levels in blood. A remarkable agreement has been found a posteriori between our strategy and independent clinical research works investigating risk factors for COVID-19 severity. Hence, these findings stress the suitability of this type of fully data-driven approaches for knowledge extraction, as a complementary to clinical perspectives.
由于 COVID-19 大流行导致了前所未有的感染和死亡人数,因此进行了大量的研究工作,以提高我们对该疾病的认识以及决定不同临床演变的因素。在这里,我们专注于通过机器学习 (ML) 对哪些因素(临床或其他因素)对 SARS-CoV-2 肺炎严重程度预测最具信息性进行完全数据驱动的探索。特别是,特征选择技术 (FS) 旨在降低数据的维数,使我们能够描述我们的变量中哪些对 ML 预后最有用。我们进行了一项多中心临床研究,共纳入 1548 名因 SARS-CoV-2 肺炎住院的患者:其中 792、238 和 598 例患者的病情分别为低、中、重度。在入院时收集了多达 106 个患者特定的临床变量,但其中 14 个变量由于包含 ⩾60%的缺失值而不得不丢弃。除了 7 个社会经济属性和 32 个空气污染暴露(慢性和急性)外,这些变量经过变量编码后成为 d = 148 个特征。我们将这个有序分类问题作为机器学习分类和回归任务来解决。我们探索了两种缺失数据的插补技术,以及总共 166 种独特的 FS 算法配置:46 个过滤器、100 个包装器和 20 个嵌入式。其中,21 种设置通过合理的计算时间实现了令人满意的自举稳定性(⩾0.70):16 个过滤器、2 个包装器和 3 个嵌入式。每个技术选择的特征子集之间的杰卡德相似度适中。然而,它们始终指出了某些解释变量的重要性。具体来说:患者的 C 反应蛋白 (CRP)、肺炎严重指数 (PSI)、呼吸频率 (RR) 和氧饱和度-SpO2、SpO2/RR 和动脉 SatO2/FiO2 的比值、中性粒细胞与淋巴细胞的比值 (NLR)-在某种程度上,也分别是中性粒细胞和淋巴细胞计数-乳酸脱氢酶 (LDH) 和血液中的降钙素原 (PCT) 水平。我们的策略与独立的 COVID-19 严重程度危险因素研究工作之间存在着显著的后验一致性。因此,这些发现强调了这种完全数据驱动方法的适用性,可作为临床观点的补充,用于知识提取。