Das Dipmala, Kumar Nikhil, Longjam Langamba Angom, Sinha Ranwir, Deb Roy Asitava, Mondal Himel, Gupta Pratima
Microbiology, All India Institute of Medical Sciences, Deoghar, Deoghar, IND.
Pathology, All India Institute of Medical Sciences, Deoghar, Deoghar, IND.
Cureus. 2023 Mar 12;15(3):e36034. doi: 10.7759/cureus.36034. eCollection 2023 Mar.
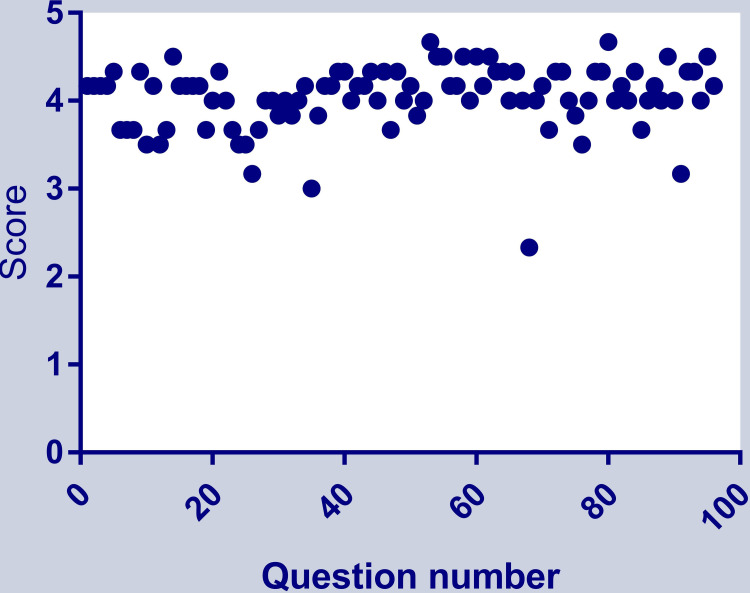
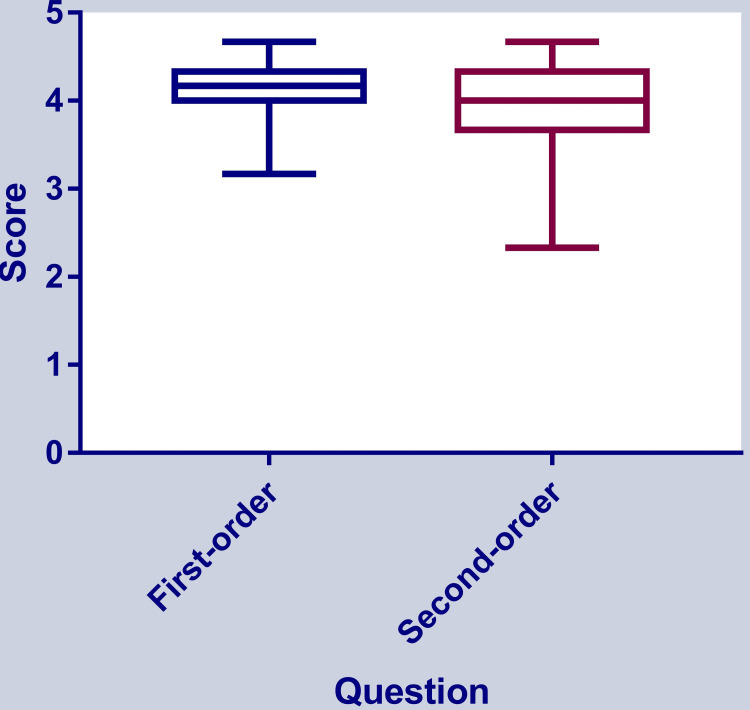
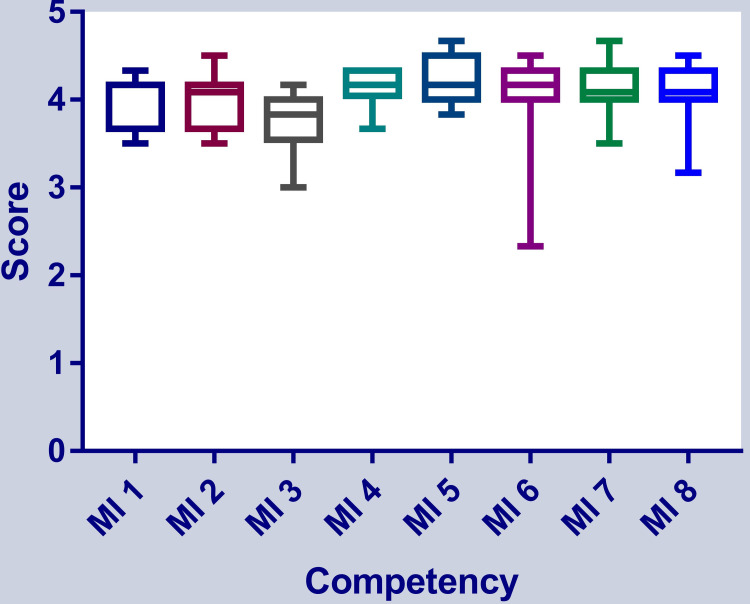
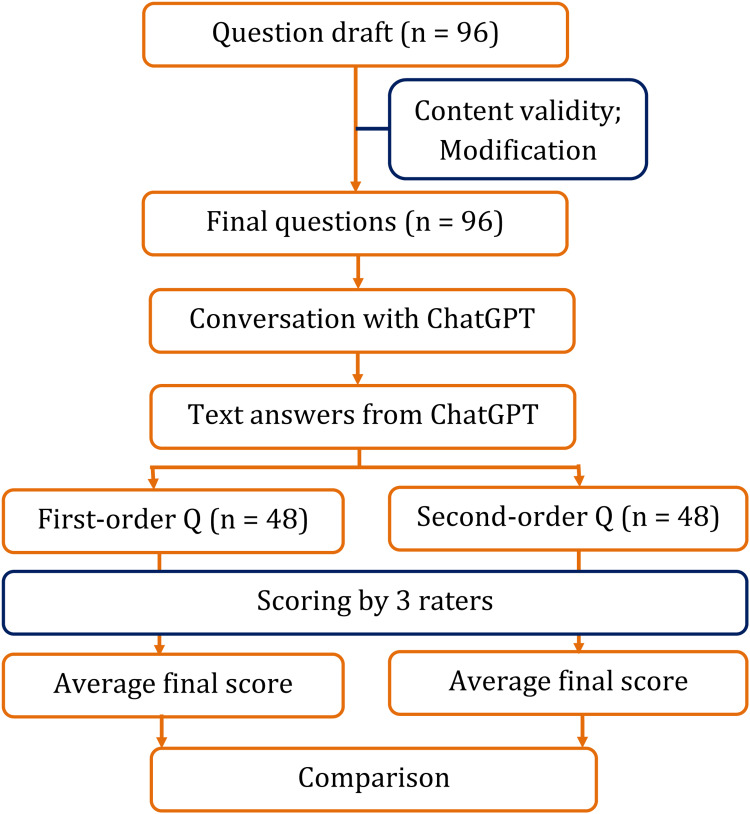
Background and objective ChatGPT is an artificial intelligence (AI) language model that has been trained to process and respond to questions across a wide range of topics. It is also capable of solving problems in medical educational topics. However, the capability of ChatGPT to accurately answer first- and second-order knowledge questions in the field of microbiology has not been explored so far. Hence, in this study, we aimed to analyze the capability of ChatGPT in answering first- and second-order questions on the subject of microbiology. Materials and methods Based on the competency-based medical education (CBME) curriculum of the subject of microbiology, we prepared a set of first-order and second-order questions. For the total of eight modules in the CBME curriculum for microbiology, we prepared six first-order and six second-order knowledge questions according to the National Medical Commission-recommended CBME curriculum, amounting to a total of (8 x 12) 96 questions. The questions were checked for content validity by three expert microbiologists. These questions were used to converse with ChatGPT by a single user and responses were recorded for further analysis. The answers were scored by three microbiologists on a rating scale of 0-5. The average of three scores was taken as the final score for analysis. As the data were not normally distributed, we used a non-parametric statistical test. The overall scores were tested by a one-sample median test with hypothetical values of 4 and 5. The scores of answers to first-order and second-order questions were compared by the Mann-Whitney U test. Module-wise responses were tested by the Kruskall-Wallis test followed by the post hoc test for pairwise comparisons. Results The overall score of 96 answers was 4.04 ±0.37 (median: 4.17, Q1-Q3: 3.88-4.33) with the mean score of answers to first-order knowledge questions being 4.07 ±0.32 (median: 4.17, Q1-Q3: 4-4.33) and that of answers to second-order knowledge questions being 3.99 ±0.43 (median: 4, Q1-Q3: 3.67-4.33) (Mann-Whitney p=0.4). The score was significantly below the score of 5 (one-sample median test p<0.0001) and similar to 4 (one-sample median test p=0.09). Overall, there was a variation in median scores obtained in eight categories of topics in microbiology, indicating inconsistent performance in different topics. Conclusion The results of the study indicate that ChatGPT is capable of answering both first- and second-order knowledge questions related to the subject of microbiology. The model achieved an accuracy of approximately 80% and there was no difference between the model's capability of answering first-order questions and second-order knowledge questions. The findings of this study suggest that ChatGPT has the potential to be an effective tool for automated question-answering in the field of microbiology. However, continued improvement in the training and development of language models is necessary to enhance their performance and make them suitable for academic use.
背景与目的 ChatGPT是一种人工智能(AI)语言模型,经过训练可处理和回答广泛主题的问题。它也能够解决医学教育主题中的问题。然而,ChatGPT在微生物学领域准确回答一阶和二阶知识问题的能力迄今尚未得到探索。因此,在本研究中,我们旨在分析ChatGPT回答微生物学主题一阶和二阶问题的能力。
材料与方法 基于微生物学主题的基于胜任力的医学教育(CBME)课程,我们准备了一组一阶和二阶问题。针对微生物学CBME课程的总共八个模块,我们根据国家医学委员会推荐的CBME课程准备了六个一阶和六个二阶知识问题,共计(8×12)96个问题。这些问题由三位微生物学专家检查内容效度。这些问题由一名用户用于与ChatGPT进行对话,并记录回答以供进一步分析。答案由三位微生物学家按照0至5的评分量表进行评分。取三个分数的平均值作为最终分析分数。由于数据非正态分布,我们使用非参数统计检验。总体分数通过单样本中位数检验进行测试,假设值为4和5。一阶和二阶问题答案的分数通过曼-惠特尼U检验进行比较。按模块的回答通过Kruskal-Wallis检验进行测试,随后进行两两比较的事后检验。
结果 96个答案的总体分数为4.04±0.37(中位数:4.17,四分位数间距:3.88 - 4.33),一阶知识问题答案的平均分数为4.07±0.32(中位数:4.17,四分位数间距:4 - 4.33),二阶知识问题答案的平均分数为3.99±0.43(中位数:4,四分位数间距:3.67 - 4.33)(曼-惠特尼检验p = 0.4)。该分数显著低于5分(单样本中位数检验p<0.0001)且与4分相似(单样本中位数检验p = 0.09)。总体而言,微生物学八个主题类别获得的中位数分数存在差异,表明在不同主题中的表现不一致。
结论 研究结果表明,ChatGPT能够回答与微生物学主题相关的一阶和二阶知识问题。该模型的准确率约为80%,且在回答一阶问题和二阶知识问题的能力之间没有差异。本研究结果表明,ChatGPT有潜力成为微生物学领域自动问答的有效工具。然而,有必要持续改进语言模型的训练和开发,以提高其性能并使其适用于学术用途。