Department of Mathematics and Computer Science, Freie Universität Berlin, Takustr. 9, 14195, Berlin, Germany.
MPI for Molecular Genetics, Ihnestr. 63, 14195, Berlin, Germany.
Genome Biol. 2023 May 31;24(1):131. doi: 10.1186/s13059-023-02971-4.
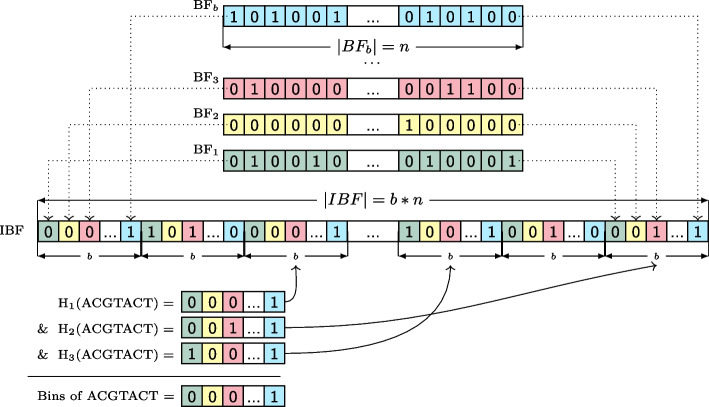
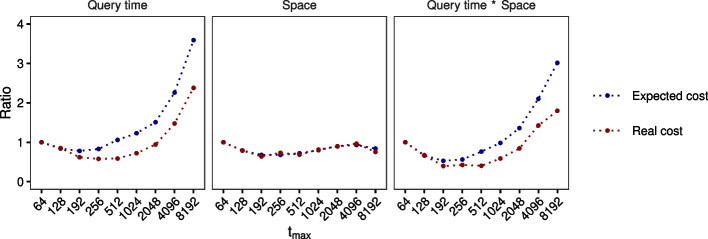
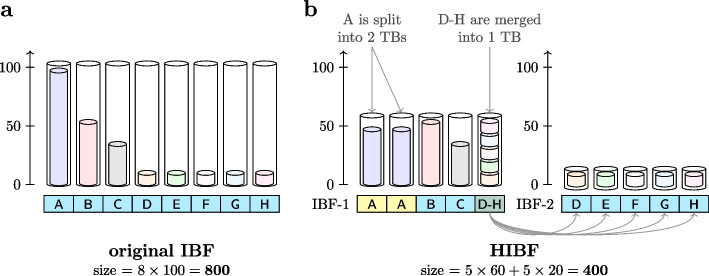
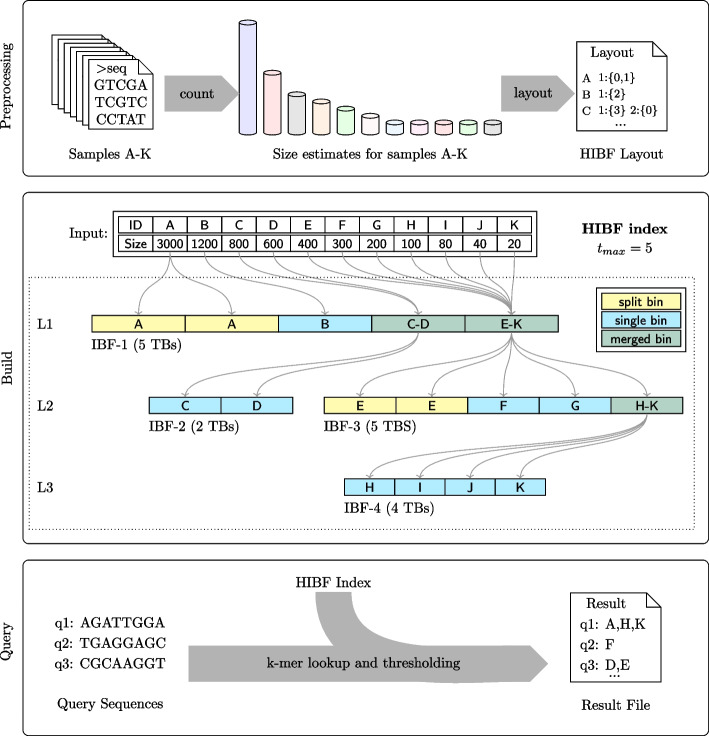
We present a novel data structure for searching sequences in large databases: the Hierarchical Interleaved Bloom Filter (HIBF). It is extremely fast and space efficient, yet so general that it could serve as the underlying engine for many applications. We show that the HIBF is superior in build time, index size, and search time while achieving a comparable or better accuracy compared to other state-of-the-art tools. The HIBF builds an index up to 211 times faster, using up to 14 times less space, and can answer approximate membership queries faster by a factor of up to 129.
分层交错布隆过滤器(HIBF)。它速度极快,空间效率高,但非常通用,可以作为许多应用程序的基础引擎。我们表明,与其他最先进的工具相比,HIBF 在构建时间、索引大小和搜索时间方面具有优势,同时实现了相当或更好的准确性。HIBF 的构建索引速度快 211 倍,使用的空间少 14 倍,并且可以将近似成员查询的响应速度提高 129 倍。