Center of Excellence in Genomics and Systems Biology, International Crops Research Institute for the Semi-Arid Tropics (ICRISAT), Hyderabad, India.
ICAR-National Bureau of Plant Genetic Resources, PUSA Campus, New Delhi, India.
PLoS One. 2023 Jun 2;18(6):e0286599. doi: 10.1371/journal.pone.0286599. eCollection 2023.
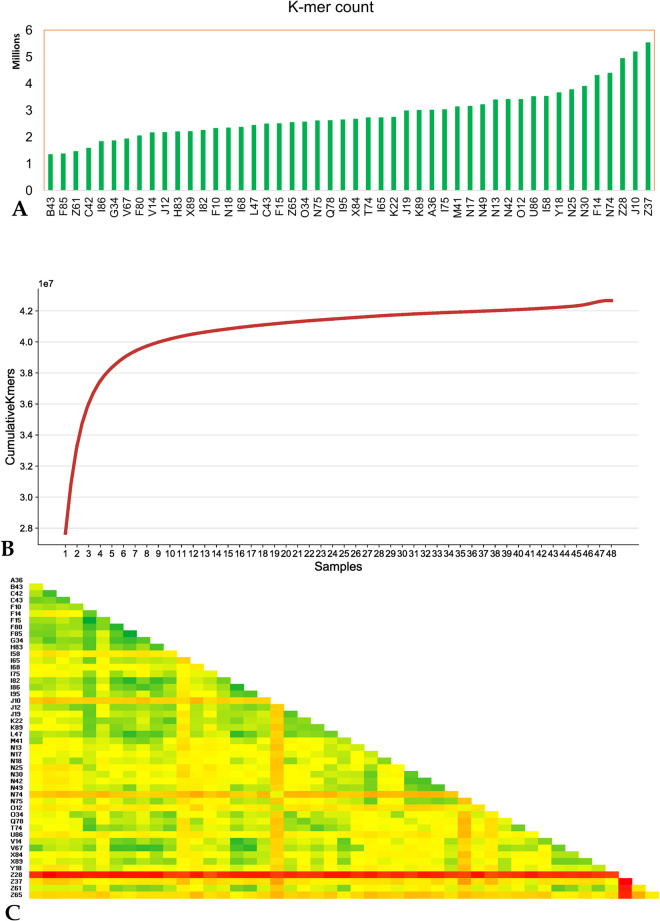
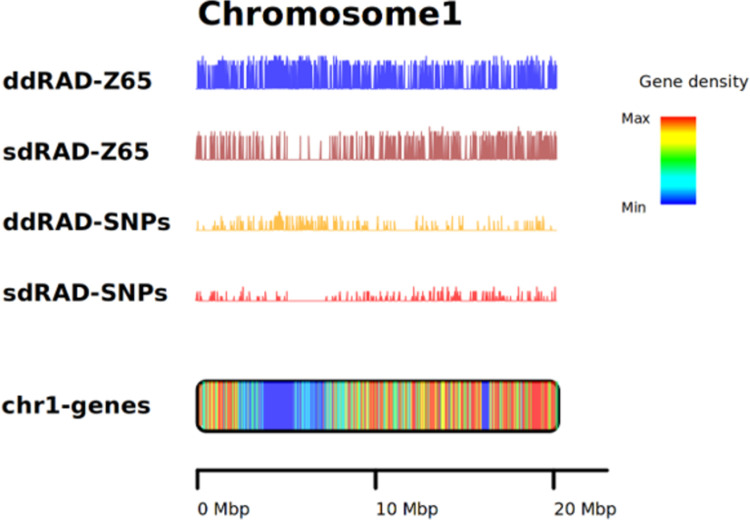
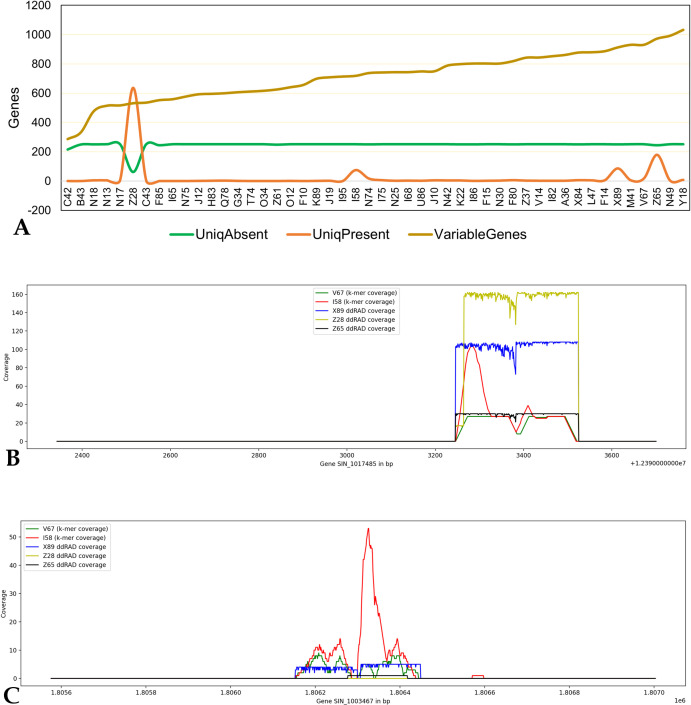
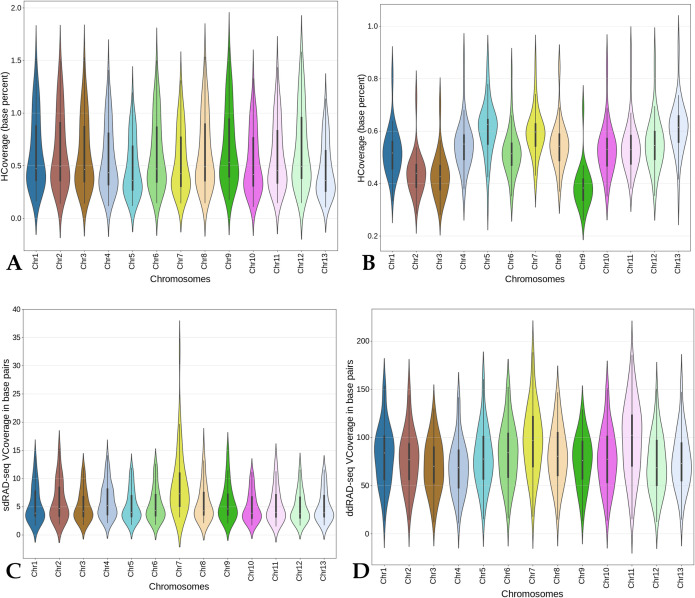
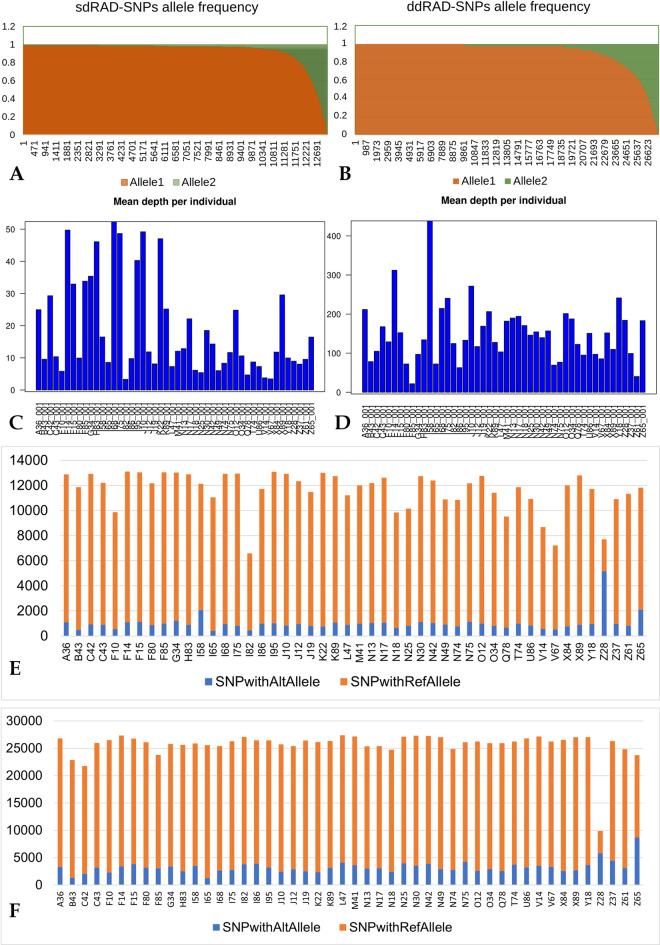
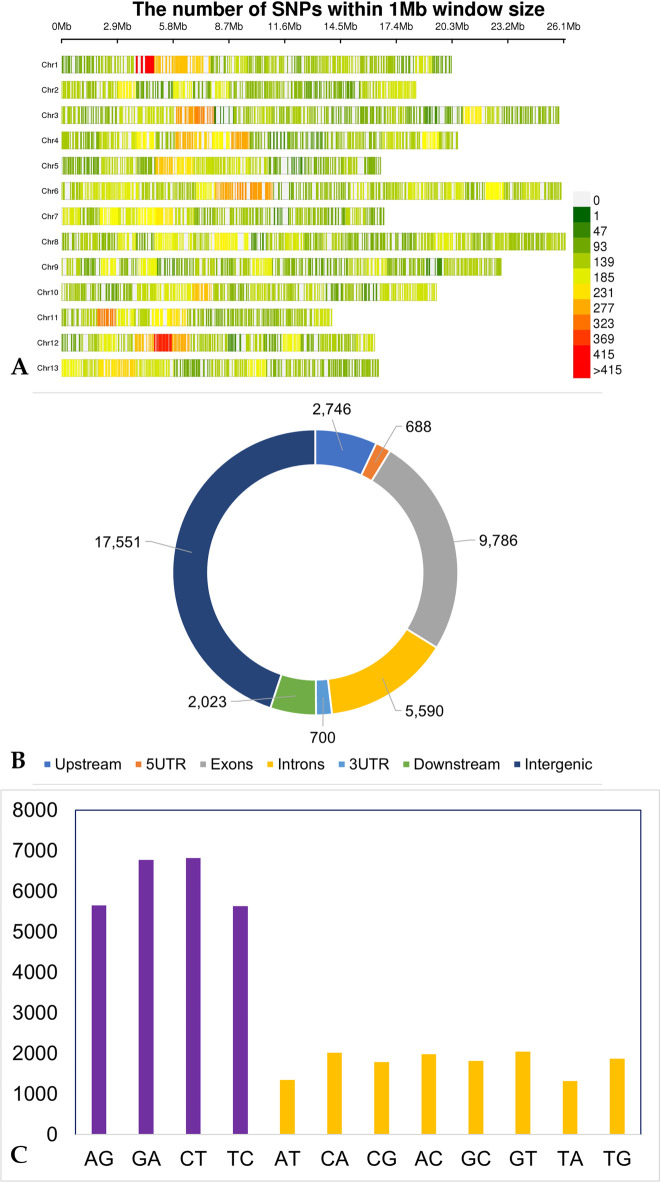
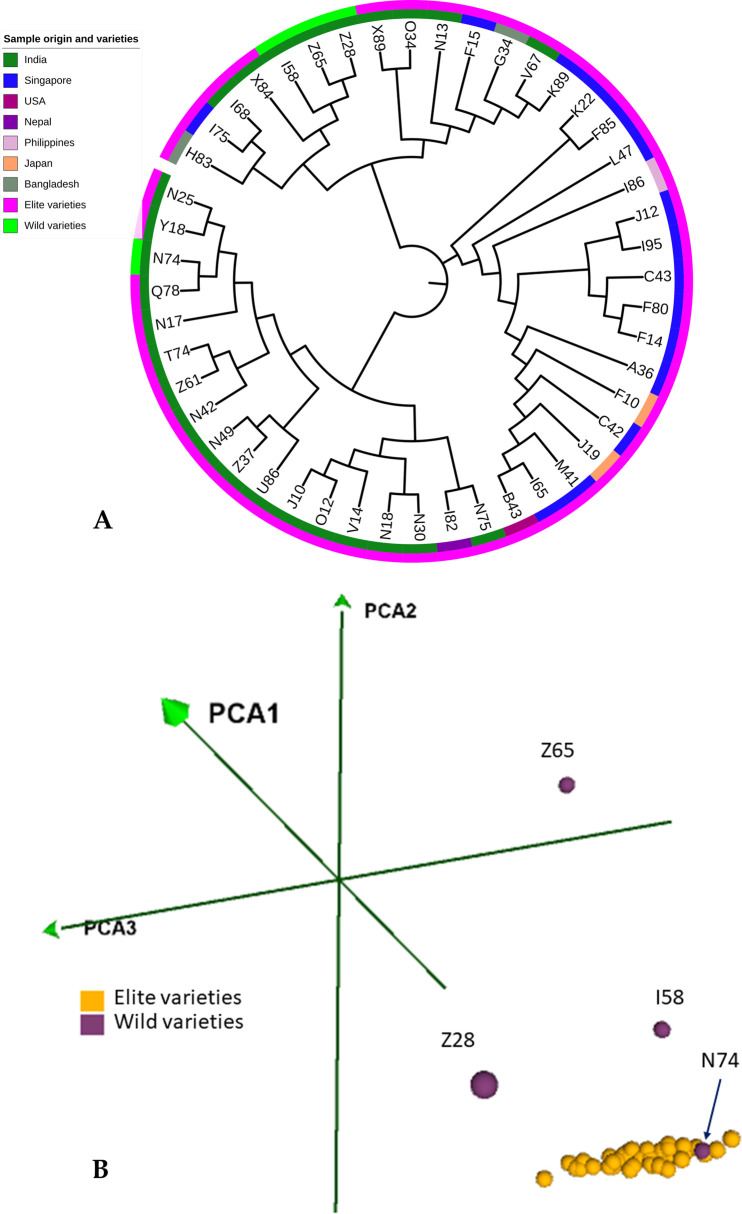
To reduce the genome sequence representation, restriction site-associated DNA sequencing (RAD-seq) protocols is being widely used either with single-digest or double-digest methods. In this study, we genotyped the sesame population (48 sample size) in a pilot scale to compare single and double-digest RAD-seq (sd and ddRAD-seq) methods. We analysed the resulting short-read data generated from both protocols and assessed their performance impacting the downstream analysis using various parameters. The distinct k-mer count and gene presence absence variation (PAV) showed a significant difference between the sesame samples studied. Additionally, the variant calling from both datasets (sdRAD-seq and ddRAD-seq) exhibits a significant difference between them. The combined variants from both datasets helped in identifying the most diverse samples and possible sub-groups in the sesame population. The most diverse samples identified from each analysis (k-mer, gene PAV, SNP count, Heterozygosity, NJ and PCA) can possibly be representative samples holding major diversity of the small sesame population used in this study. The best possible strategies with suggested inputs for modifications to utilize the RAD-seq strategy efficiently on a large dataset containing thousands of samples to be subjected to molecular analysis like diversity, population structure and core development studies were discussed.
为了减少基因组序列的表示,限制位点相关的 DNA 测序(RAD-seq)协议被广泛应用于单消化或双消化方法。在这项研究中,我们以试点规模对芝麻群体(48 个样本大小)进行了基因分型,以比较单消化和双消化 RAD-seq(sd 和 ddRAD-seq)方法。我们分析了两种方案产生的短读数据,并使用各种参数评估它们对下游分析的影响。不同的 k-mer 计数和基因存在缺失变异(PAV)在研究的芝麻样本之间表现出显著差异。此外,来自两个数据集(sdRAD-seq 和 ddRAD-seq)的变异调用也存在显著差异。两个数据集的组合变体有助于识别芝麻群体中最多样化的样本和可能的亚群。从每个分析中确定的最多样化的样本(k-mer、基因 PAV、SNP 计数、杂合度、NJ 和 PCA)可能是具有代表性的样本,代表了本研究中小芝麻群体的主要多样性。讨论了在包含数千个样本的大型数据集上进行分子分析(如多样性、群体结构和核心开发研究)时,利用 RAD-seq 策略的最佳可能策略和建议的输入修改,以提高效率。