Tuzhilina Elena, Tozzi Leonardo, Hastie Trevor
Department of Statistics, Stanford University, Stanford, CA, USA.
Department of Psychiatry and Behavioral Sciences, Stanford University, Stanford, CA, USA.
Stat Modelling. 2023 Jun;23(3):203-227. doi: 10.1177/1471082x211041033. Epub 2021 Oct 3.
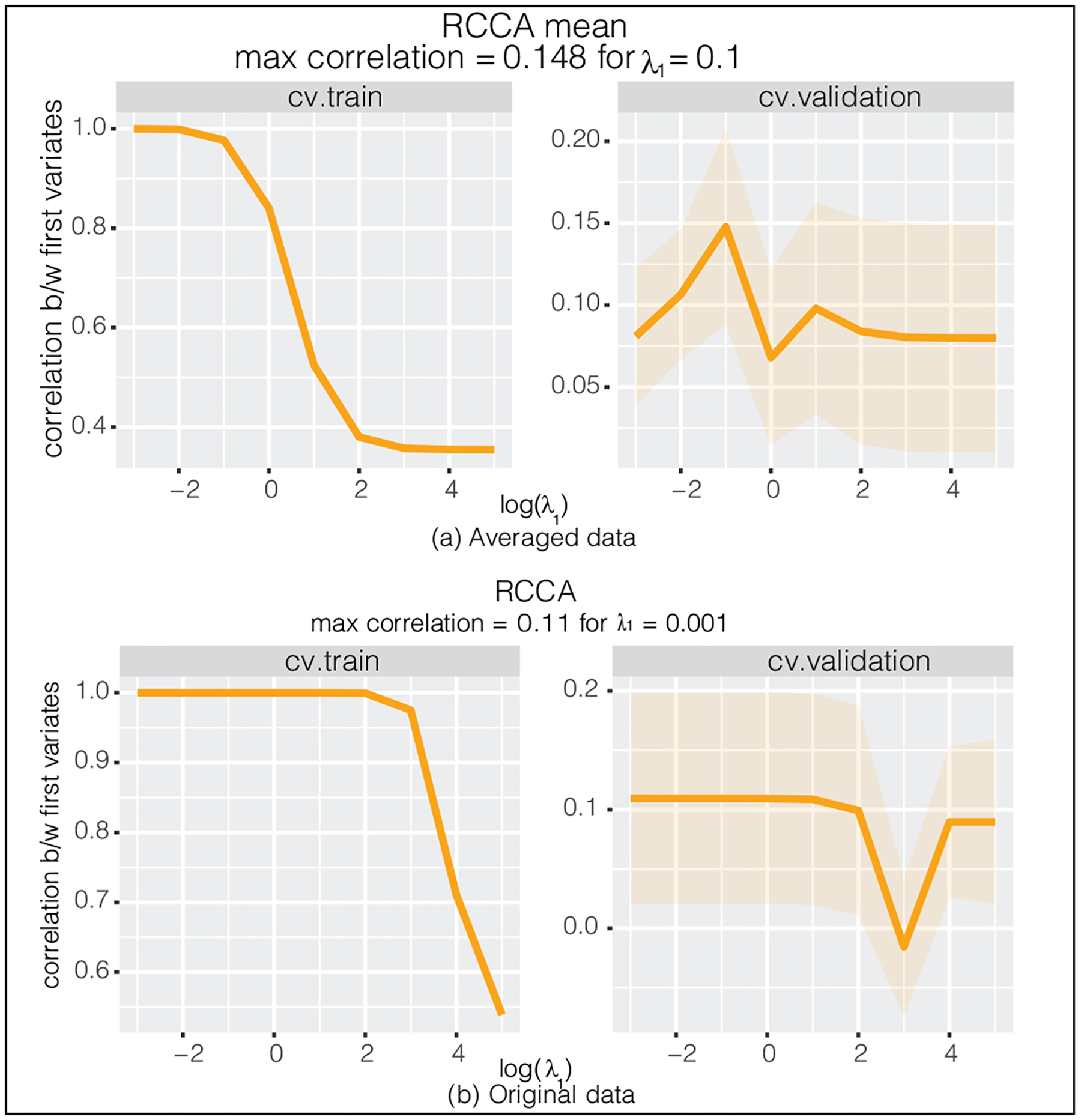
Canonical correlation analysis (CCA) is a technique for measuring the association between two multivariate data matrices. A regularized modification of canonical correlation analysis (RCCA) which imposes an penalty on the CCA coefficients is widely used in applications with high-dimensional data. One limitation of such regularization is that it ignores any data structure, treating all the features equally, which can be ill-suited for some applications. In this article we introduce several approaches to regularizing CCA that take the underlying data structure into account. In particular, the proposed group regularized canonical correlation analysis (GRCCA) is useful when the variables are correlated in groups. We illustrate some computational strategies to avoid excessive computations with regularized CCA in high dimensions. We demonstrate the application of these methods in our motivating application from neuroscience, as well as in a small simulation example.
典型相关分析(CCA)是一种用于测量两个多元数据矩阵之间关联的技术。对CCA系数施加惩罚的典型相关分析的正则化修改(RCCA)在高维数据应用中被广泛使用。这种正则化的一个局限性在于它忽略了任何数据结构,平等对待所有特征,这可能不适用于某些应用。在本文中,我们介绍了几种考虑基础数据结构的CCA正则化方法。特别是,当变量按组相关时,提出的组正则化典型相关分析(GRCCA)很有用。我们说明了一些计算策略,以避免在高维中使用正则化CCA进行过多计算。我们展示了这些方法在我们来自神经科学的激励性应用以及一个小型模拟示例中的应用。