FHAIVE, Faculty of Medicine and Health Technology, Tampere University, Tampere 33520, Finland.
Tampere Institute for Advanced Study, Tampere, 33520, Finland.
Bioinformatics. 2023 Jun 1;39(6). doi: 10.1093/bioinformatics/btad405.
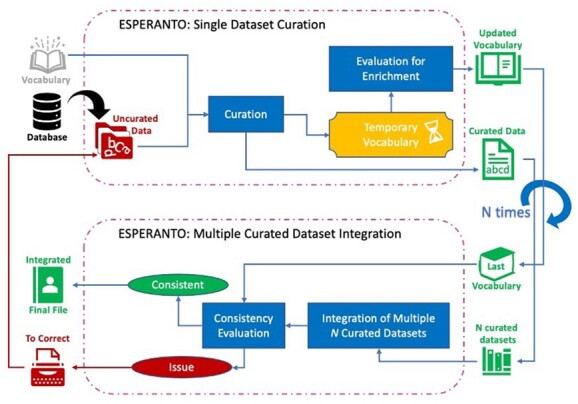
Biological data repositories are an invaluable source of publicly available research evidence. Unfortunately, the lack of convergence of the scientific community on a common metadata annotation strategy has resulted in large amounts of data with low FAIRness (Findable, Accessible, Interoperable and Reusable). The possibility of generating high-quality insights from their integration relies on data curation, which is typically an error-prone process while also being expensive in terms of time and human labour. Here, we present ESPERANTO, an innovative framework that enables a standardized semi-supervised harmonization and integration of toxicogenomics metadata and increases their FAIRness in a Good Laboratory Practice-compliant fashion. The harmonization across metadata is guaranteed with the definition of an ad hoc vocabulary. The tool interface is designed to support the user in metadata harmonization in a user-friendly manner, regardless of the background and the type of expertise.
ESPERANTO and its user manual are freely available for academic purposes at https://github.com/fhaive/esperanto. The input and the results showcased in Supplementary File S1 are available at the same link.
生物数据存储库是公共可用研究证据的宝贵资源。然而,科学界缺乏对通用元数据标注策略的共识,导致大量数据的 FAIR 程度较低(可发现性、可访问性、互操作性和可重用性)。从其整合中生成高质量见解的可能性依赖于数据管理,这通常是一个容易出错的过程,而且在时间和人力方面也很昂贵。在这里,我们提出了 ESPERANTO,这是一个创新的框架,能够以标准化的半监督方式协调和整合毒理学元数据,并以符合良好实验室规范的方式提高其 FAIR 程度。通过定义专门的词汇表来保证元数据的协调一致。该工具的界面旨在以用户友好的方式支持用户进行元数据协调,无论其背景和专业类型如何。
ESPERANTO 及其用户手册可在学术用途上免费在 https://github.com/fhaive/esperanto 获取。在补充文件 S1 中展示的输入和结果可在同一链接获取。