Emergency Medicine Residency, Denver Health, Denver, CO.
Department of Pediatric Hematology/Oncology, Roger Maris Cancer Center, Sanford Health, Fargo, ND.
JCO Clin Cancer Inform. 2023 Jul;7:e2300009. doi: 10.1200/CCI.23.00009.
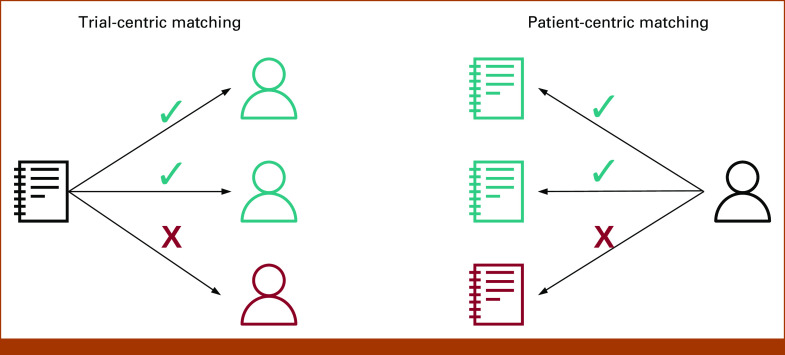
Matching patients to clinical trials is cumbersome and costly. Attempts have been made to automate the matching process; however, most have used a trial-centric approach, which focuses on a single trial. In this study, we developed a patient-centric matching tool that matches patient-specific demographic and clinical information with free-text clinical trial inclusion and exclusion criteria extracted using natural language processing to return a list of relevant clinical trials ordered by the patient's likelihood of eligibility.
Records from pediatric leukemia clinical trials were downloaded from ClinicalTrials.gov. Regular expressions were used to discretize and extract individual trial criteria. A multilabel support vector machine (SVM) was trained to classify sentence embeddings of criteria into relevant clinical categories. Labeled criteria were parsed using regular expressions to extract numbers, comparators, and relationships. In the validation phase, a patient-trial match score was generated for each trial and returned in the form of a ranked list for each patient.
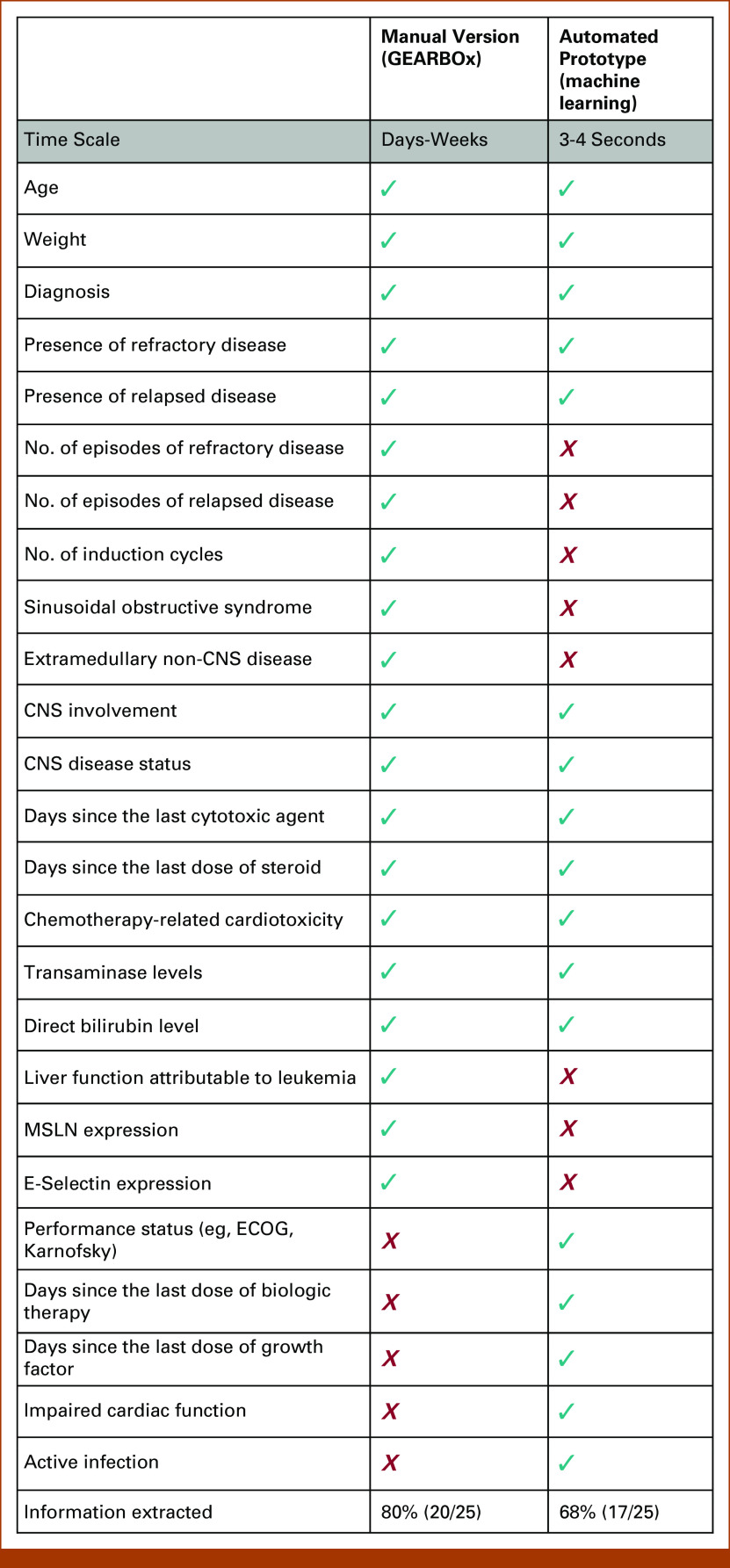
In total, 5,251 discretized criteria were extracted from 216 protocols. The most frequent criterion was previous chemotherapy/biologics (17%). The multilabel SVM demonstrated a pooled accuracy of 75%. The text processing pipeline was able to automatically extract 68% of eligibility criteria rules, as compared with 80% in a manual version of the tool. Automated matching was accomplished in approximately 4 seconds, as compared with several hours using manual derivation.
To our knowledge, this project represents the first open-source attempt to generate a patient-centric clinical trial matching tool. The tool demonstrated acceptable performance when compared with a manual version, and it has potential to save time and money when matching patients to trials.
将患者与临床试验匹配既繁琐又昂贵。人们已经尝试过使匹配过程自动化;然而,大多数尝试都采用了以试验为中心的方法,该方法侧重于单个试验。在这项研究中,我们开发了一种以患者为中心的匹配工具,该工具将患者特定的人口统计学和临床信息与使用自然语言处理提取的包含和排除标准的自由文本临床试验进行匹配,以返回按患者资格可能性排序的相关临床试验列表。
从 ClinicalTrials.gov 下载了儿科白血病临床试验记录。使用正则表达式将各个试验标准离散化并提取出来。训练了一个多标签支持向量机(SVM)来将标准的句子嵌入分类为相关的临床类别。使用正则表达式解析标记标准,以提取数字、比较器和关系。在验证阶段,为每个试验生成一个患者-试验匹配分数,并以每个患者的排名列表形式返回。
从 216 个方案中提取了 5251 个离散标准。最常见的标准是既往化疗/生物制剂(17%)。多标签 SVM 的准确率为 75%。与工具的手动版本相比,文本处理管道能够自动提取 68%的资格标准规则,而手动版本为 80%。与手动推导相比,自动化匹配大约需要 4 秒,而手动推导则需要数小时。
据我们所知,该项目代表了首次尝试开发以患者为中心的临床试验匹配工具的开源项目。与手动版本相比,该工具的性能可接受,并且在将患者与试验匹配时有可能节省时间和金钱。