School of Statistics and Data Science, Beijing Wuzi University, Beijing 101149, China.
Faculty of Information Technology, Beijing University of Technology, Beijing 100124, China.
Sensors (Basel). 2023 Jul 6;23(13):6190. doi: 10.3390/s23136190.
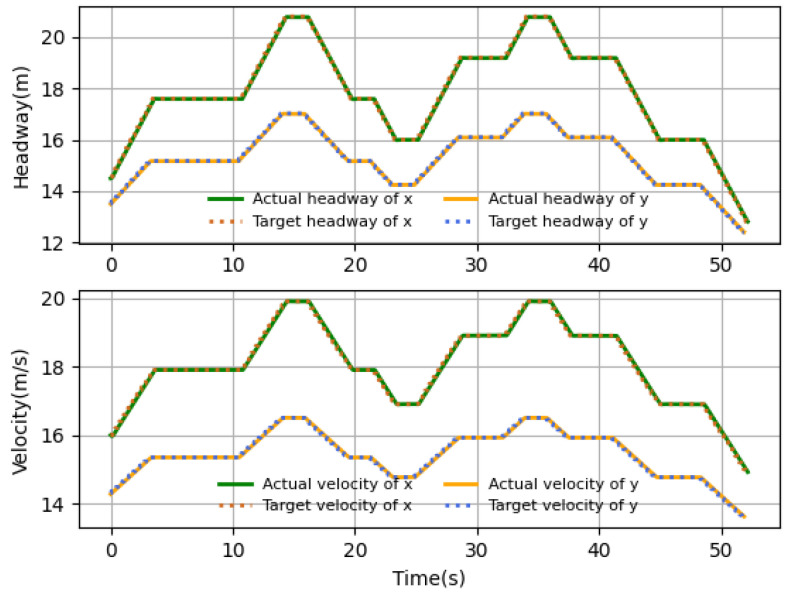
Multiple unmanned aerial vehicles (UAVs) have a greater potential to be widely used in UAV-assisted IoT applications. UAV formation, as an effective way to improve surveillance and security, has been extensively of concern. The leader-follower approach is efficient for UAV formation, as the whole formation system needs to find only the leader's trajectory. This paper studies the leader-follower surveillance system. Owing to different scenarios and assignments, the leading velocity is dynamic. The inevitable communication time delays resulting from information sending, communicating and receiving process bring challenges in the design of real-time UAV formation control. In this paper, the design of UAV formation tracking based on deep reinforcement learning (DRL) is investigated for high mobility scenarios in the presence of communication delay. To be more specific, the optimization UAV formation problem is firstly formulated to be a state error minimization problem by using the quadratic cost function when the communication delay is considered. Then, the delay-informed Markov decision process (DIMDP) is developed by including the previous actions in order to compensate the performance degradation induced by the time delay. Subsequently, an extended-delay informed deep deterministic policy gradient (DIDDPG) algorithm is proposed. Finally, some issues, such as computational complexity analysis and the effect of the time delay are discussed, and then the proposed intelligent algorithm is further extended to the arbitrary communication delay case. Numerical experiments demonstrate that the proposed DIDDPG algorithm can significantly alleviate the performance degradation caused by time delays.
多架无人机(UAV)在无人机辅助物联网应用中具有更大的应用潜力。无人机编队作为提高监控和安全性的有效手段,受到了广泛关注。领导者-跟随者方法是无人机编队的有效方法,因为整个编队系统只需要找到领导者的轨迹。本文研究了领导者-跟随者监控系统。由于不同的场景和任务分配,领导速度是动态的。信息发送、通信和接收过程中不可避免的通信时间延迟给实时无人机编队控制的设计带来了挑战。在本文中,研究了在存在通信延迟的情况下,基于深度强化学习(DRL)的无人机编队跟踪设计,用于高机动性场景。更具体地说,通过使用二次代价函数,将通信延迟考虑在内,首先将优化的无人机编队问题公式化为状态误差最小化问题。然后,通过包括以前的动作来开发包含延迟的马尔可夫决策过程(DIMDP),以补偿由延迟引起的性能下降。随后,提出了一种扩展延迟信息深度确定性策略梯度(DIDDPG)算法。最后,讨论了一些问题,如计算复杂度分析和延迟的影响,然后进一步将所提出的智能算法扩展到任意通信延迟情况。数值实验表明,所提出的 DIDDPG 算法可以显著减轻由延迟引起的性能下降。