Interaction Technology Laboratory, Department of Software, Sejong University, Seoul 05006, Korea.
Sensors (Basel). 2020 Sep 12;20(18):5212. doi: 10.3390/s20185212.
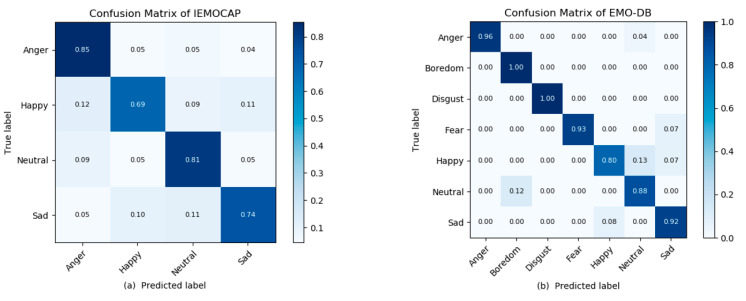
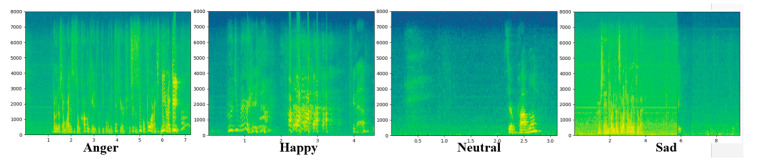
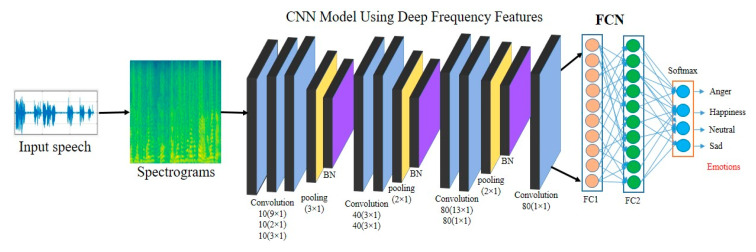
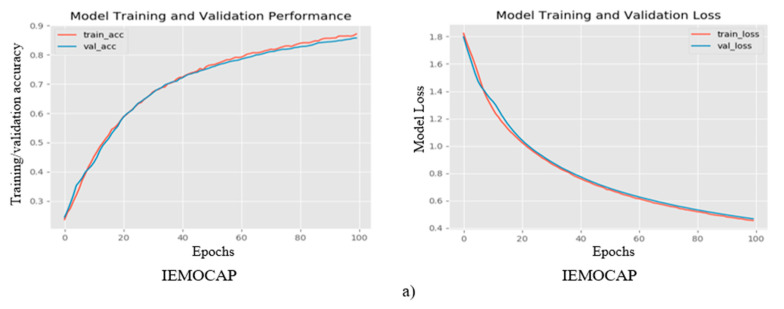
Artificial intelligence (AI) and machine learning (ML) are employed to make systems smarter. Today, the speech emotion recognition (SER) system evaluates the emotional state of the speaker by investigating his/her speech signal. Emotion recognition is a challenging task for a machine. In addition, making it smarter so that the emotions are efficiently recognized by AI is equally challenging. The speech signal is quite hard to examine using signal processing methods because it consists of different frequencies and features that vary according to emotions, such as anger, fear, sadness, happiness, boredom, disgust, and surprise. Even though different algorithms are being developed for the SER, the success rates are very low according to the languages, the emotions, and the databases. In this paper, we propose a new lightweight effective SER model that has a low computational complexity and a high recognition accuracy. The suggested method uses the convolutional neural network (CNN) approach to learn the deep frequency features by using a plain rectangular filter with a modified pooling strategy that have more discriminative power for the SER. The proposed CNN model was trained on the extracted frequency features from the speech data and was then tested to predict the emotions. The proposed SER model was evaluated over two benchmarks, which included the interactive emotional dyadic motion capture (IEMOCAP) and the berlin emotional speech database (EMO-DB) speech datasets, and it obtained 77.01% and 92.02% recognition results. The experimental results demonstrated that the proposed CNN-based SER system can achieve a better recognition performance than the state-of-the-art SER systems.
人工智能(AI)和机器学习(ML)被用于使系统更加智能化。如今,语音情感识别(SER)系统通过研究说话者的语音信号来评估其情绪状态。情感识别对于机器来说是一项具有挑战性的任务。此外,要使系统变得更加智能,以便 AI 能够有效地识别情感,这同样具有挑战性。由于语音信号包含不同的频率和特征,这些特征根据情感(如愤怒、恐惧、悲伤、快乐、无聊、厌恶和惊讶)而变化,因此使用信号处理方法很难对其进行检查。尽管针对 SER 开发了不同的算法,但根据语言、情感和数据库,成功率非常低。在本文中,我们提出了一种新的轻量级有效 SER 模型,该模型具有较低的计算复杂度和较高的识别精度。所提出的方法使用卷积神经网络(CNN)方法通过使用具有修改后的池化策略的普通矩形滤波器来学习深度频率特征,该策略对 SER 具有更强的区分能力。所提出的 CNN 模型在从语音数据中提取的频率特征上进行了训练,然后进行了测试以预测情绪。在所提出的 SER 模型的评估中,使用了两个基准数据集,即交互情感对偶运动捕捉(IEMOCAP)和柏林情感语音数据库(EMO-DB)语音数据集,分别获得了 77.01%和 92.02%的识别结果。实验结果表明,所提出的基于 CNN 的 SER 系统可以实现比现有 SER 系统更好的识别性能。