Department of Mechanical and Electrical Engineering, Xiamen University, Xiamen 361005, China.
Department of Automation, Xiamen University, Xiamen 361005, China.
Sensors (Basel). 2023 Jul 7;23(13):6238. doi: 10.3390/s23136238.
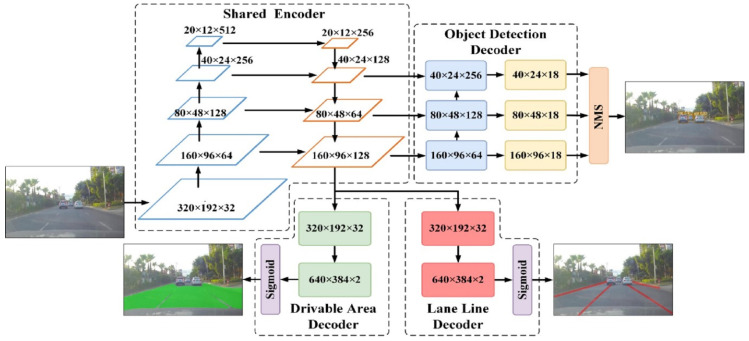
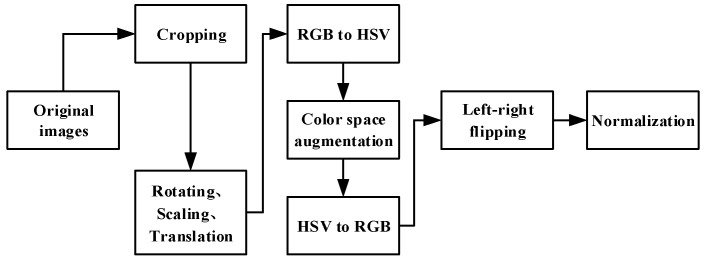
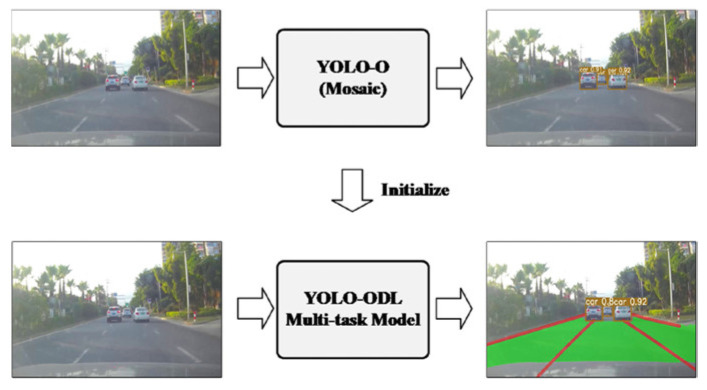
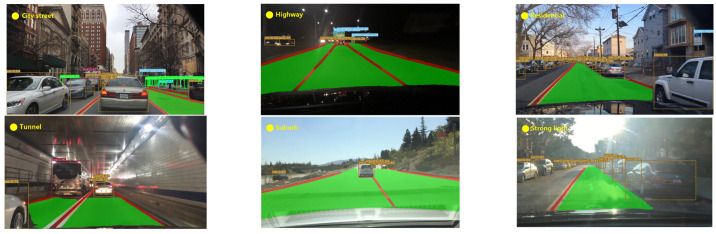
Road scene understanding is crucial to the safe driving of autonomous vehicles. Comprehensive road scene understanding requires a visual perception system to deal with a large number of tasks at the same time, which needs a perception model with a small size, fast speed, and high accuracy. As multi-task learning has evident advantages in performance and computational resources, in this paper, a multi-task model YOLO-Object, Drivable Area, and Lane Line Detection (YOLO-ODL) based on hard parameter sharing is proposed to realize joint and efficient detection of traffic objects, drivable areas, and lane lines. In order to balance tasks of YOLO-ODL, a weight balancing strategy is introduced so that the weight parameters of the model can be automatically adjusted during training, and a Mosaic migration optimization scheme is adopted to improve the evaluation indicators of the model. Our YOLO-ODL model performs well on the challenging BDD100K dataset, achieving the state of the art in terms of accuracy and computational efficiency.
道路场景理解对自动驾驶汽车的安全行驶至关重要。全面的道路场景理解需要一个视觉感知系统来同时处理大量任务,这需要一个具有小尺寸、快速和高精度的感知模型。由于多任务学习在性能和计算资源方面具有明显的优势,因此本文提出了一种基于硬参数共享的多任务模型 YOLO-Object、Drivable Area 和 Lane Line Detection(YOLO-ODL),以实现交通对象、可行驶区域和车道线的联合高效检测。为了平衡 YOLO-ODL 的任务,引入了一种权重平衡策略,以便在训练过程中自动调整模型的权重参数,并采用 Mosaic 迁移优化方案来提高模型的评估指标。我们的 YOLO-ODL 模型在具有挑战性的 BDD100K 数据集上表现出色,在准确性和计算效率方面达到了最新水平。