Department of Biomedical Informatics, School of Medicine, Emory University, Atlanta, GA, United States of America.
Department of Biomedical Informatics, Vanderbilt University Medical Center, Vanderbilt University, Nashville, TN, United States of America.
J Biomed Inform. 2023 Aug;144:104458. doi: 10.1016/j.jbi.2023.104458. Epub 2023 Jul 23.
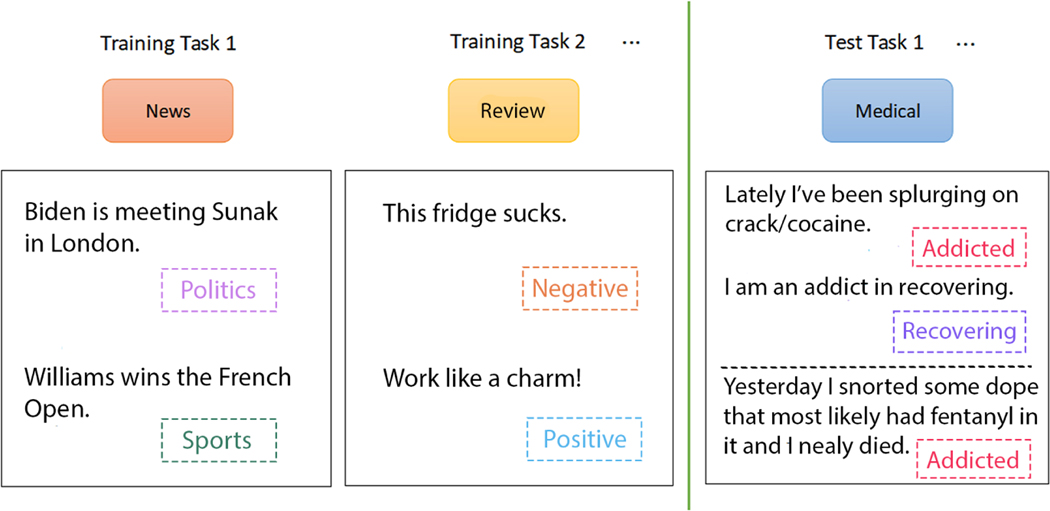
Few-shot learning (FSL) is a class of machine learning methods that require small numbers of labeled instances for training. With many medical topics having limited annotated text-based data in practical settings, FSL-based natural language processing (NLP) holds substantial promise. We aimed to conduct a review to explore the current state of FSL methods for medical NLP.
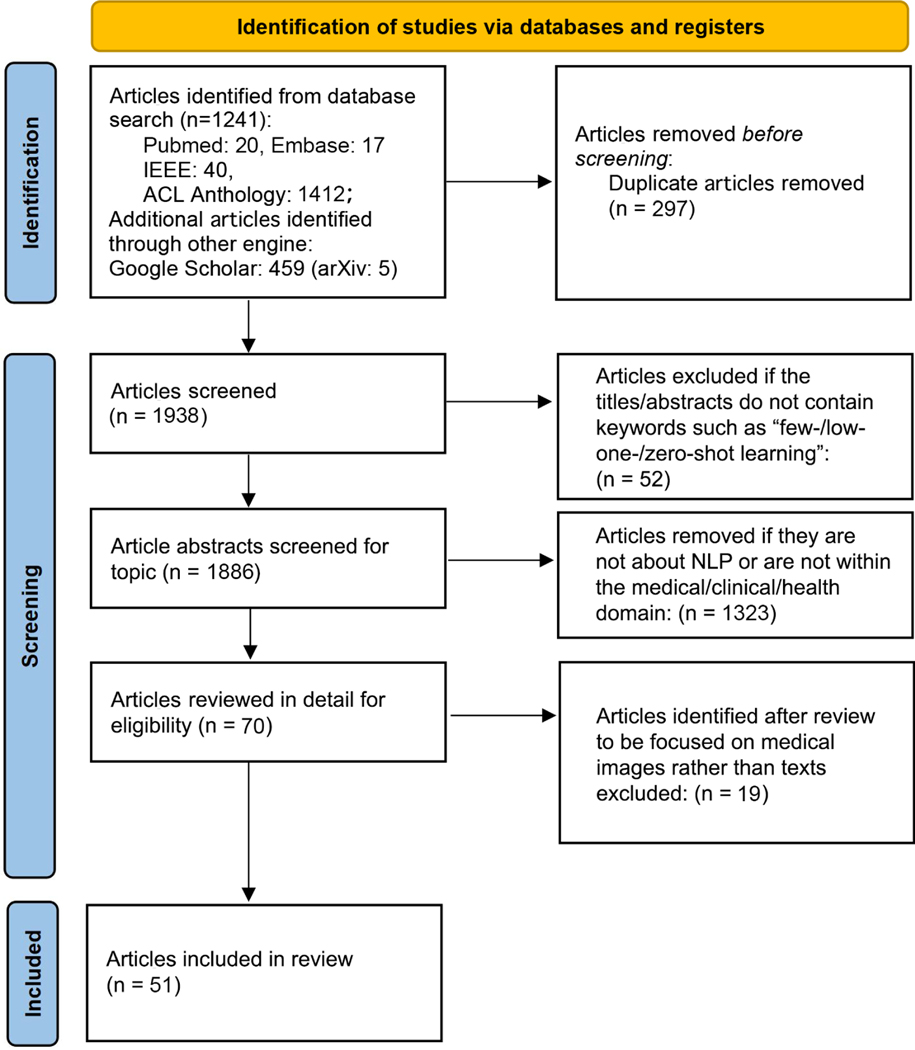
We searched for articles published between January 2016 and October 2022 using PubMed/Medline, Embase, ACL Anthology, and IEEE Xplore Digital Library. We also searched the preprint servers (e.g., arXiv, medRxiv, and bioRxiv) via Google Scholar to identify the latest relevant methods. We included all articles that involved FSL and any form of medical text. We abstracted articles based on the data source, target task, training set size, primary method(s)/approach(es), and evaluation metric(s).
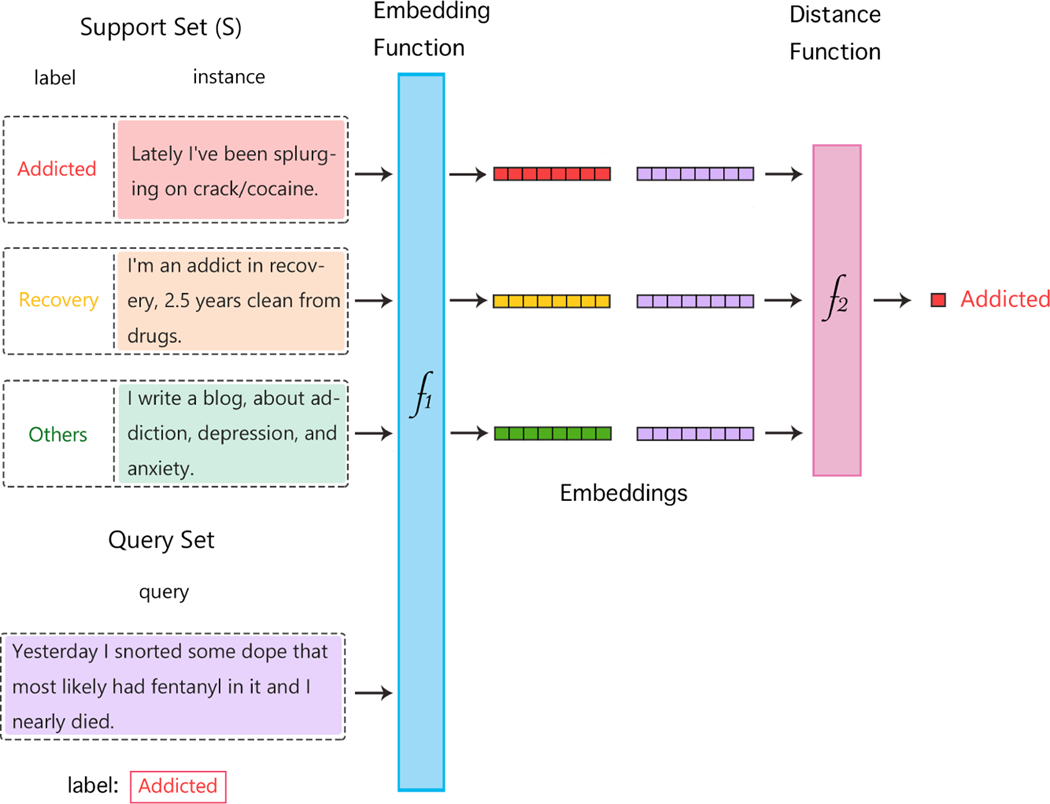
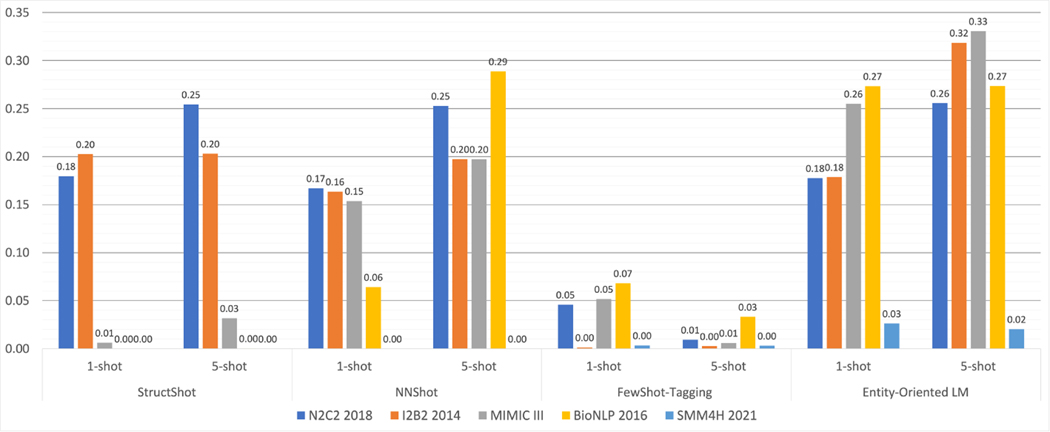
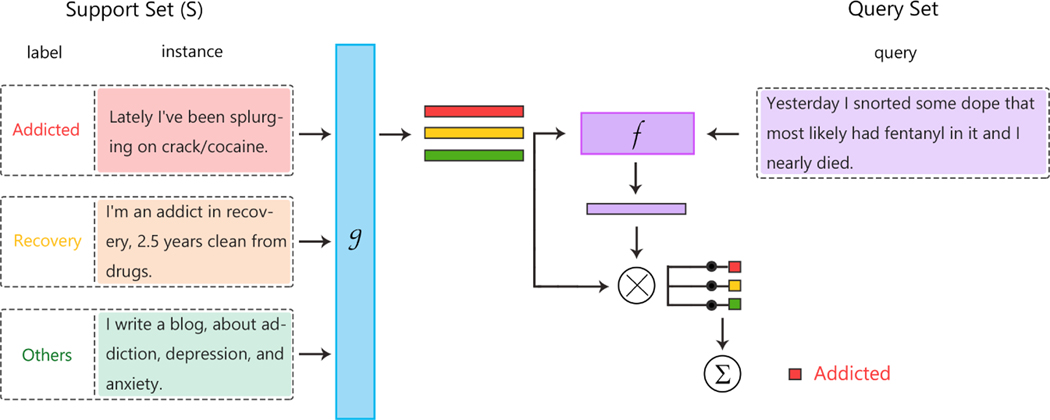
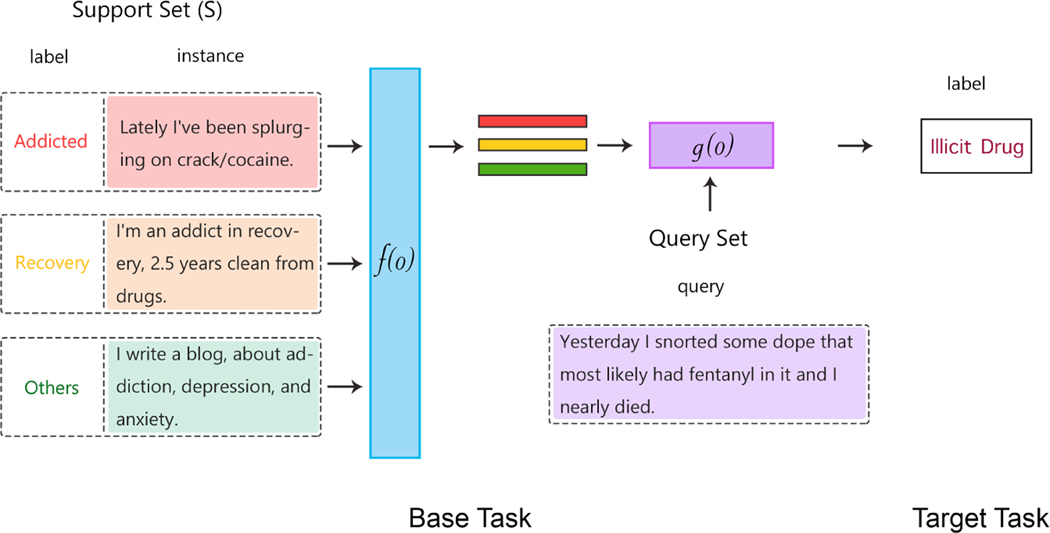
Fifty-one articles met our inclusion criteria-all published after 2018, and most since 2020 (42/51; 82%). Concept extraction/named entity recognition was the most frequently addressed task (21/51; 41%), followed by text classification (16/51; 31%). Thirty-two (61%) articles reconstructed existing datasets to fit few-shot scenarios, and MIMIC-III was the most frequently used dataset (10/51; 20%). 77% of the articles attempted to incorporate prior knowledge to augment the small datasets available for training. Common methods included FSL with attention mechanisms (20/51; 39%), prototypical networks (11/51; 22%), meta-learning (7/51; 14%), and prompt-based learning methods, the latter being particularly popular since 2021. Benchmarking experiments demonstrated relative underperformance of FSL methods on biomedical NLP tasks.
Despite the potential for FSL in biomedical NLP, progress has been limited. This may be attributed to the rarity of specialized data, lack of standardized evaluation criteria, and the underperformance of FSL methods on biomedical topics. The creation of publicly-available specialized datasets for biomedical FSL may aid method development by facilitating comparative analyses.
小样本学习(FSL)是一类机器学习方法,仅需少量有标签的实例进行训练。在实际情况下,许多医学主题的基于文本的注释数据有限,因此基于 FSL 的自然语言处理(NLP)具有很大的潜力。我们旨在进行一项综述,以探索医学 NLP 中 FSL 方法的现状。
我们使用 PubMed/Medline、Embase、ACL 文集和 IEEE Xplore 数字图书馆,搜索了 2016 年 1 月至 2022 年 10 月期间发表的文章。我们还通过 Google Scholar 搜索预印本服务器(例如 arXiv、medRxiv 和 bioRxiv),以确定最新的相关方法。我们纳入了所有涉及 FSL 和任何形式的医学文本的文章。我们根据数据源、目标任务、训练集大小、主要方法/方法和评估指标来摘要文章。
符合纳入标准的文章有 51 篇-均发表于 2018 年以后,其中大多数(42/51;82%)发表于 2020 年以后。概念提取/命名实体识别是最常被研究的任务(21/51;41%),其次是文本分类(16/51;31%)。32 篇(61%)文章重建了现有的数据集以适应小样本场景,其中 MIMIC-III 是最常被使用的数据集(10/51;20%)。77%的文章试图利用先验知识来扩充用于训练的小数据集。常见的方法包括具有注意力机制的 FSL(20/51;39%)、原型网络(11/51;22%)、元学习(7/51;14%)和基于提示的学习方法,后者自 2021 年以来特别流行。基准实验表明,FSL 方法在生物医学 NLP 任务中的表现相对较差。
尽管 FSL 在生物医学 NLP 中有潜力,但进展有限。这可能归因于特殊数据的稀有性、缺乏标准化的评估标准以及 FSL 方法在生物医学主题上的表现不佳。为生物医学 FSL 创建公共可用的特殊数据集可能有助于方法开发,促进比较分析。