Lu Heng-Yang, Fan Chenyou, Song Xiaoning, Fang Wei
Jiangsu Provincial Engineering Laboratory of Pattern Recognition and Computational Intelligence, School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi, China.
State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing, China.
PeerJ Comput Sci. 2021 Aug 20;7:e688. doi: 10.7717/peerj-cs.688. eCollection 2021.
Rumor detection is a popular research topic in natural language processing and data mining. Since the outbreak of COVID-19, related rumors have been widely posted and spread on online social media, which have seriously affected people's daily lives, national economy, social stability, etc. It is both theoretically and practically essential to detect and refute COVID-19 rumors fast and effectively. As COVID-19 was an emergent event that was outbreaking drastically, the related rumor instances were very scarce and distinct at its early stage. This makes the detection task a typical few-shot learning problem. However, traditional rumor detection techniques focused on detecting existed events with enough training instances, so that they fail to detect emergent events such as COVID-19. Therefore, developing a new few-shot rumor detection framework has become critical and emergent to prevent outbreaking rumors at early stages.
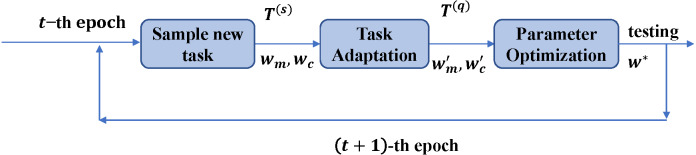
This article focuses on few-shot rumor detection, especially for detecting COVID-19 rumors from Sina Weibo with only a minimal number of labeled instances. We contribute a Sina Weibo COVID-19 rumor dataset for few-shot rumor detection and propose a few-shot learning-based multi-modality fusion model for few-shot rumor detection. A full microblog consists of the source post and corresponding comments, which are considered as two modalities and fused with the meta-learning methods.
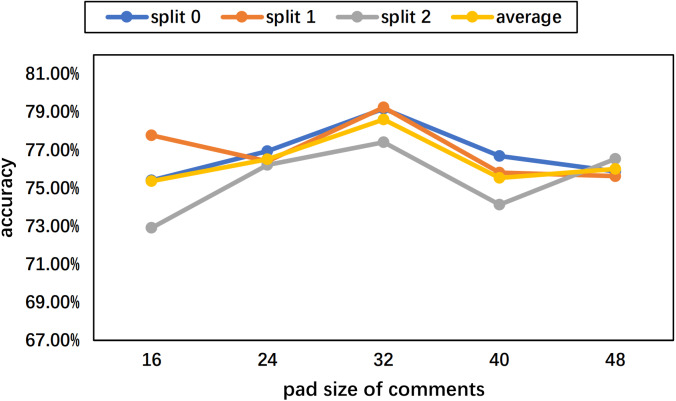
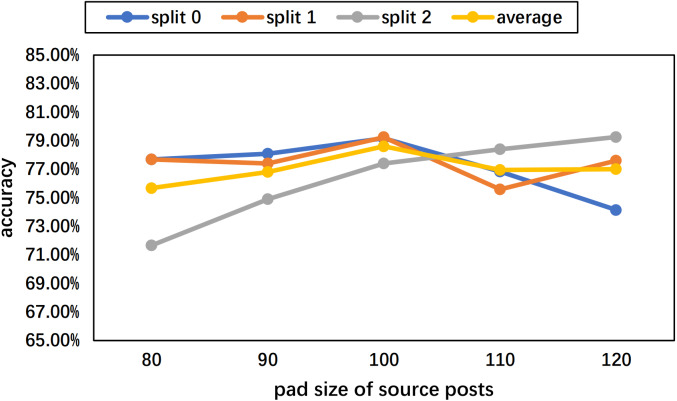
Experiments of few-shot rumor detection on the collected Weibo dataset and the PHEME public dataset have shown significant improvement and generality of the proposed model.
谣言检测是自然语言处理和数据挖掘领域一个热门的研究课题。自新冠疫情爆发以来,相关谣言在在线社交媒体上广泛发布和传播,严重影响了人们的日常生活、国民经济、社会稳定等。快速有效地检测和驳斥新冠疫情谣言在理论和实践上都至关重要。由于新冠疫情是一个急剧爆发的突发事件,其早期相关的谣言实例非常稀缺且独特。这使得检测任务成为一个典型的少样本学习问题。然而,传统的谣言检测技术专注于检测有足够训练实例的已发生事件,因此无法检测像新冠疫情这样的突发事件。因此,开发一种新的少样本谣言检测框架对于在早期阶段防止谣言爆发变得至关重要且紧迫。
本文聚焦于少样本谣言检测,特别是从新浪微博中仅用极少量标注实例来检测新冠疫情谣言。我们贡献了一个用于少样本谣言检测的新浪微博新冠疫情谣言数据集,并提出了一种基于少样本学习的多模态融合模型用于少样本谣言检测。一条完整的微博由源帖子和相应评论组成,它们被视为两种模态,并与元学习方法进行融合。
在收集的微博数据集和PHEME公共数据集上进行的少样本谣言检测实验表明,所提出的模型有显著的改进和通用性。