Zheng Jianyu, Liu Ying
Department of Chinese Language and Literature, Tsinghua University, Haidian Distinct, Beijing, China.
PeerJ Comput Sci. 2023 Jul 26;9:e1478. doi: 10.7717/peerj-cs.1478. eCollection 2023.
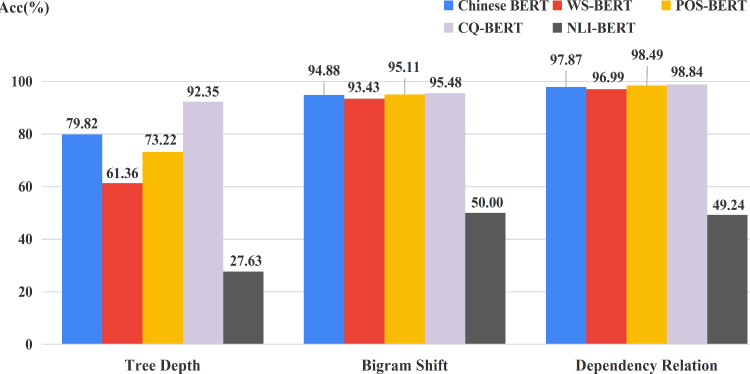
Pre-trained language models such as Bidirectional Encoder Representations from Transformers (BERT) have been applied to a wide range of natural language processing (NLP) tasks and obtained significantly positive results. A growing body of research has investigated the reason why BERT is so efficient and what language knowledge BERT is able to learn. However, most of these works focused almost exclusively on English. Few studies have explored the language information, particularly syntactic information, that BERT has learned in Chinese, which is written as sequences of characters. In this study, we adopted some probing methods for identifying syntactic knowledge stored in the attention heads and hidden states of Chinese BERT. The results suggest that some individual heads and combination of heads do well in encoding corresponding and overall syntactic relations, respectively. The hidden representation of each layer also contained syntactic information to different degrees. We also analyzed the fine-tuned models of Chinese BERT for different tasks, covering all levels. Our results suggest that these fine-turned models reflect changes in conserving language structure. These findings help explain why Chinese BERT can show such large improvements across many language-processing tasks.
预训练语言模型,如来自Transformer的双向编码器表征(BERT),已被应用于广泛的自然语言处理(NLP)任务,并取得了显著的积极成果。越来越多的研究探讨了BERT为何如此高效以及它能够学习何种语言知识。然而,这些研究大多几乎只聚焦于英语。很少有研究探索BERT在中文(以字符序列书写)中学习到的语言信息,尤其是句法信息。在本研究中,我们采用了一些探测方法来识别存储在中文BERT注意力头和隐藏状态中的句法知识。结果表明,一些单个注意力头和注意力头的组合分别在编码相应的和整体的句法关系方面表现良好。每一层的隐藏表征也不同程度地包含句法信息。我们还分析了中文BERT针对不同任务的微调模型,涵盖了各个层面。我们的结果表明,这些微调模型反映了在保留语言结构方面的变化。这些发现有助于解释为什么中文BERT在许多语言处理任务中能有如此大的提升。