College of Computer Science, Sichuan University, Chengdu, China.
MobLab Inc., Pasadena, CA, USA.
BMC Med Inform Decis Mak. 2022 Apr 5;21(Suppl 9):377. doi: 10.1186/s12911-022-01829-2.
Natural language processing (NLP) tasks in the health domain often deal with limited amount of labeled data due to high annotation costs and naturally rare observations. To compensate for the lack of training data, health NLP researchers often have to leverage knowledge and resources external to a task at hand. Recently, pretrained large-scale language models such as the Bidirectional Encoder Representations from Transformers (BERT) have been proven to be a powerful way of learning rich linguistic knowledge from massive unlabeled text and transferring that knowledge to downstream tasks. However, previous downstream tasks often used training data at such a large scale that is unlikely to obtain in the health domain. In this work, we aim to study whether BERT can still benefit downstream tasks when training data are relatively small in the context of health NLP.
We conducted a learning curve analysis to study the behavior of BERT and baseline models as training data size increases. We observed the classification performance of these models on two disease diagnosis data sets, where some diseases are naturally rare and have very limited observations (fewer than 2 out of 10,000). The baselines included commonly used text classification models such as sparse and dense bag-of-words models, long short-term memory networks, and their variants that leveraged external knowledge. To obtain learning curves, we incremented the amount of training examples per disease from small to large, and measured the classification performance in macro-averaged [Formula: see text] score.
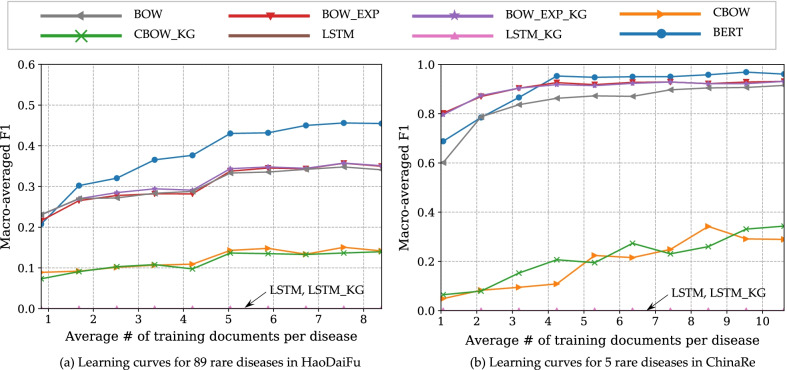
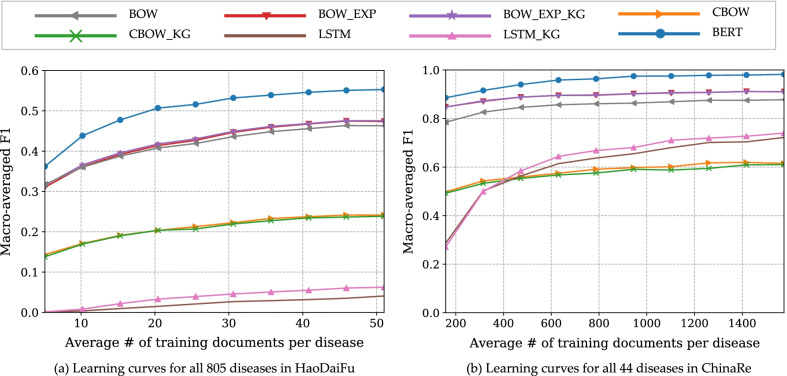
On the task of classifying all diseases, the learning curves of BERT were consistently above all baselines, significantly outperforming them across the spectrum of training data sizes. But under extreme situations where only one or two training documents per disease were available, BERT was outperformed by linear classifiers with carefully engineered bag-of-words features.
As long as the amount of training documents is not extremely few, fine-tuning a pretrained BERT model is a highly effective approach to health NLP tasks like disease classification. However, in extreme cases where each class has only one or two training documents and no more will be available, simple linear models using bag-of-words features shall be considered.
由于标注成本高和自然稀有观察,健康领域的自然语言处理(NLP)任务通常处理的是有限数量的标记数据。为了弥补训练数据的不足,健康 NLP 研究人员经常不得不利用任务之外的知识和资源。最近,像 Transformer 中的双向编码器表示(BERT)这样的预训练的大规模语言模型已被证明是一种从大量未标记文本中学习丰富语言知识并将该知识转移到下游任务的强大方法。然而,以前的下游任务通常使用的训练数据规模如此之大,以至于在健康领域不太可能获得。在这项工作中,我们旨在研究在健康 NLP 中训练数据相对较小时,BERT 是否仍然可以受益于下游任务。
我们进行了学习曲线分析,以研究 BERT 和基线模型随训练数据大小增加的行为。我们观察了这些模型在两个疾病诊断数据集上的分类性能,其中一些疾病自然罕见,观察到的病例非常有限(少于 10000 例中的 2 例)。基线包括常用的文本分类模型,如稀疏和密集词袋模型、长短时记忆网络及其利用外部知识的变体。为了获得学习曲线,我们按从小到大的顺序增加每个疾病的训练示例数量,并以宏平均 [Formula: see text] 分数衡量分类性能。
在所有疾病的分类任务中,BERT 的学习曲线始终高于所有基线,在整个训练数据规模范围内都显著优于它们。但是,在每种疾病只有一两个训练文档的极端情况下,BERT 的性能逊于经过精心设计的词袋特征的线性分类器。
只要训练文档的数量不是非常少,微调预训练的 BERT 模型是疾病分类等健康 NLP 任务的一种非常有效的方法。然而,在每种疾病只有一两个训练文档且没有更多文档的极端情况下,应考虑使用基于词袋特征的简单线性模型。