Department of Statistics, LMU Munich, Munich, Germany.
Munich Center for Machine Learning, Munich, Germany.
Commun Biol. 2023 Sep 11;6(1):928. doi: 10.1038/s42003-023-05310-2.
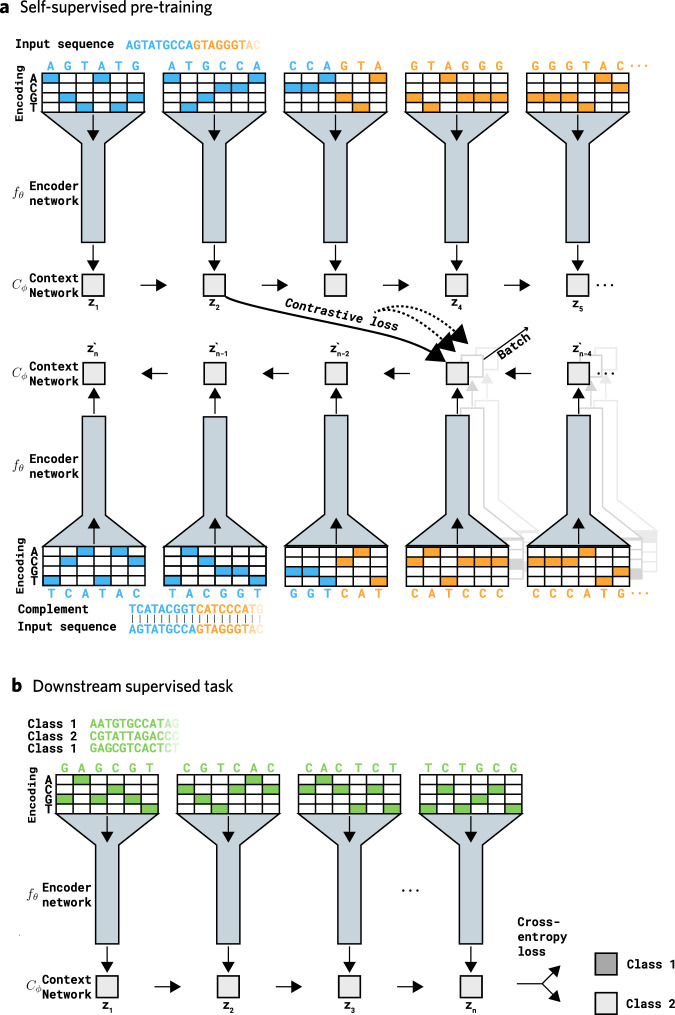
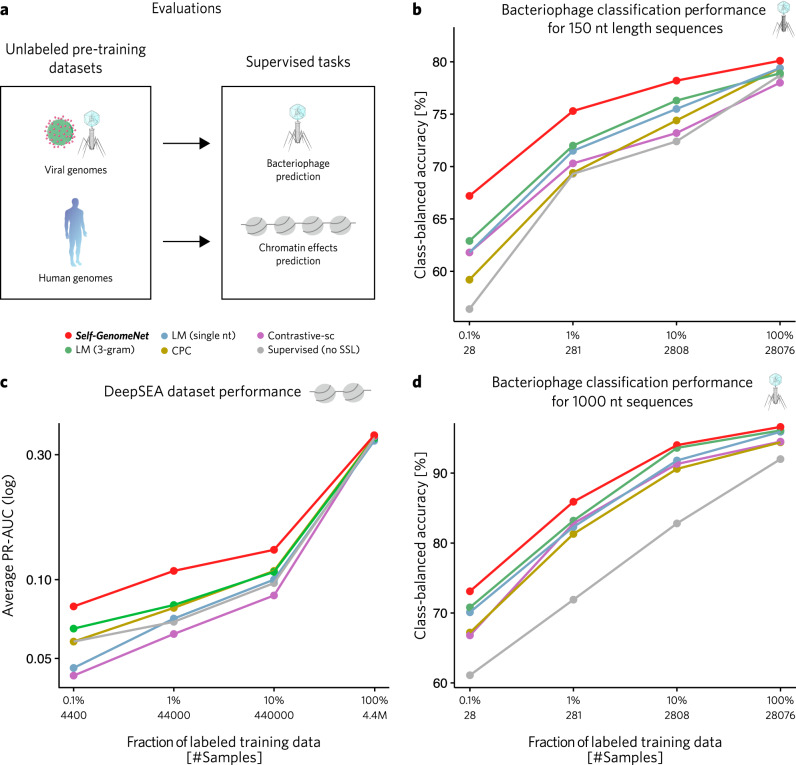
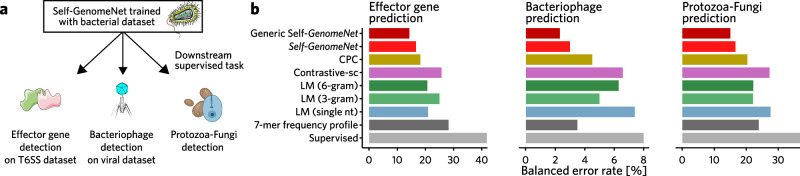
Deep learning in bioinformatics is often limited to problems where extensive amounts of labeled data are available for supervised classification. By exploiting unlabeled data, self-supervised learning techniques can improve the performance of machine learning models in the presence of limited labeled data. Although many self-supervised learning methods have been suggested before, they have failed to exploit the unique characteristics of genomic data. Therefore, we introduce Self-GenomeNet, a self-supervised learning technique that is custom-tailored for genomic data. Self-GenomeNet leverages reverse-complement sequences and effectively learns short- and long-term dependencies by predicting targets of different lengths. Self-GenomeNet performs better than other self-supervised methods in data-scarce genomic tasks and outperforms standard supervised training with ~10 times fewer labeled training data. Furthermore, the learned representations generalize well to new datasets and tasks. These findings suggest that Self-GenomeNet is well suited for large-scale, unlabeled genomic datasets and could substantially improve the performance of genomic models.
生物信息学中的深度学习通常局限于那些有大量标记数据可用于监督分类的问题。通过利用未标记的数据,自监督学习技术可以在标记数据有限的情况下提高机器学习模型的性能。尽管之前已经提出了许多自监督学习方法,但它们未能利用基因组数据的独特特征。因此,我们引入了 Self-GenomeNet,这是一种专门针对基因组数据的自监督学习技术。Self-GenomeNet 利用反向互补序列,并通过预测不同长度的目标来有效地学习短程和长程依赖关系。在数据稀缺的基因组任务中,Self-GenomeNet 的表现优于其他自监督方法,并且使用大约 10 倍少的标记训练数据就能胜过标准监督训练。此外,学习到的表示可以很好地泛化到新的数据集和任务。这些发现表明,Self-GenomeNet 非常适合大规模的、未标记的基因组数据集,并可以显著提高基因组模型的性能。