Teebagy Sean, Colwell Lauren, Wood Emma, Yaghy Antonio, Faustina Misha
Department of Ophthalmology and Visual Sciences, UMass Chan Medical School, Worcester, Massachusetts.
J Acad Ophthalmol (2017). 2023 Sep 11;15(2):e184-e187. doi: 10.1055/s-0043-1774399. eCollection 2023 Jul.
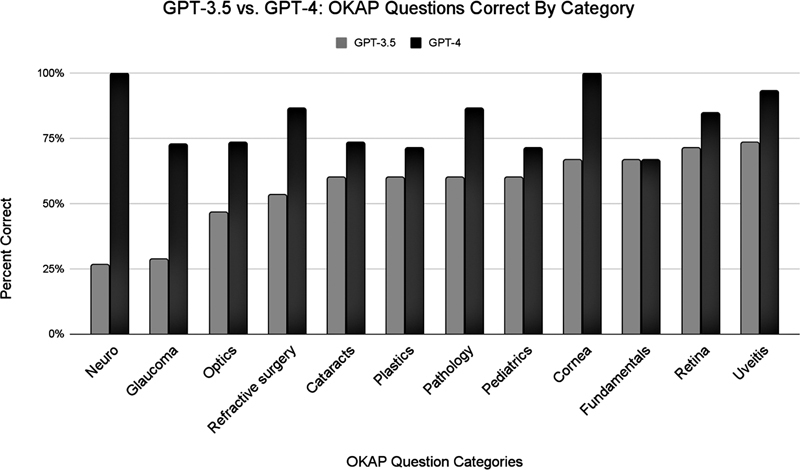
This study aims to evaluate the performance of ChatGPT-4, an advanced artificial intelligence (AI) language model, on the Ophthalmology Knowledge Assessment Program (OKAP) examination compared to its predecessor, ChatGPT-3.5. Both models were tested on 180 OKAP practice questions covering various ophthalmology subject categories. ChatGPT-4 significantly outperformed ChatGPT-3.5 (81% vs. 57%; <0.001), indicating improvements in medical knowledge assessment. The superior performance of ChatGPT-4 suggests potential applicability in ophthalmologic education and clinical decision support systems. Future research should focus on refining AI models, ensuring a balanced representation of fundamental and specialized knowledge, and determining the optimal method of integrating AI into medical education and practice.
本研究旨在评估先进的人工智能(AI)语言模型ChatGPT-4在眼科知识评估计划(OKAP)考试中的表现,并与它的前身ChatGPT-3.5进行比较。两个模型都在涵盖各种眼科主题类别的180道OKAP练习题上进行了测试。ChatGPT-4的表现显著优于ChatGPT-3.5(81%对57%;<0.001),表明在医学知识评估方面有所改进。ChatGPT-4的卓越表现表明其在眼科教育和临床决策支持系统中具有潜在的适用性。未来的研究应专注于改进人工智能模型,确保基础知识和专业知识的平衡呈现,并确定将人工智能整合到医学教育和实践中的最佳方法。