Hu Mengzhou, Alkhairy Sahar, Lee Ingoo, Pillich Rudolf T, Bachelder Robin, Ideker Trey, Pratt Dexter
Department of Medicine, University of California San Diego, La Jolla, California, USA.
Department of Computer Science and Engineering, University of California San Diego, La Jolla, California, USA.
Res Sq. 2023 Sep 18:rs.3.rs-3270331. doi: 10.21203/rs.3.rs-3270331/v1.
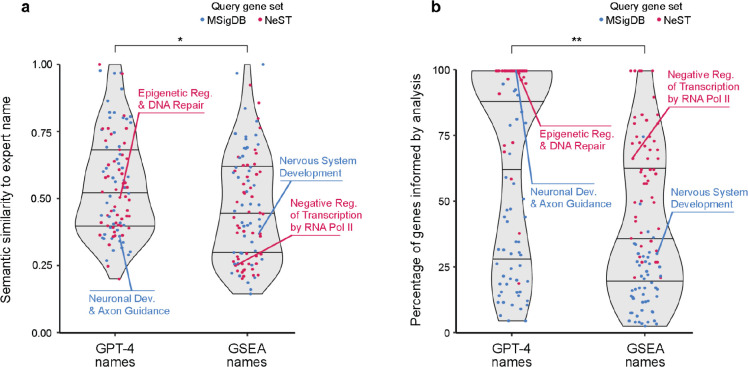
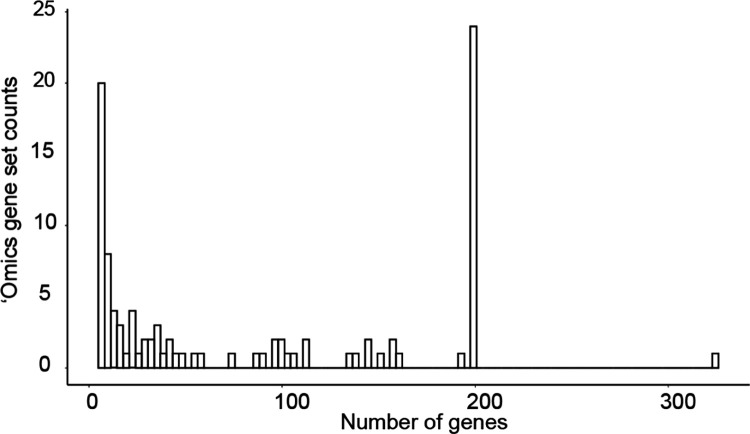
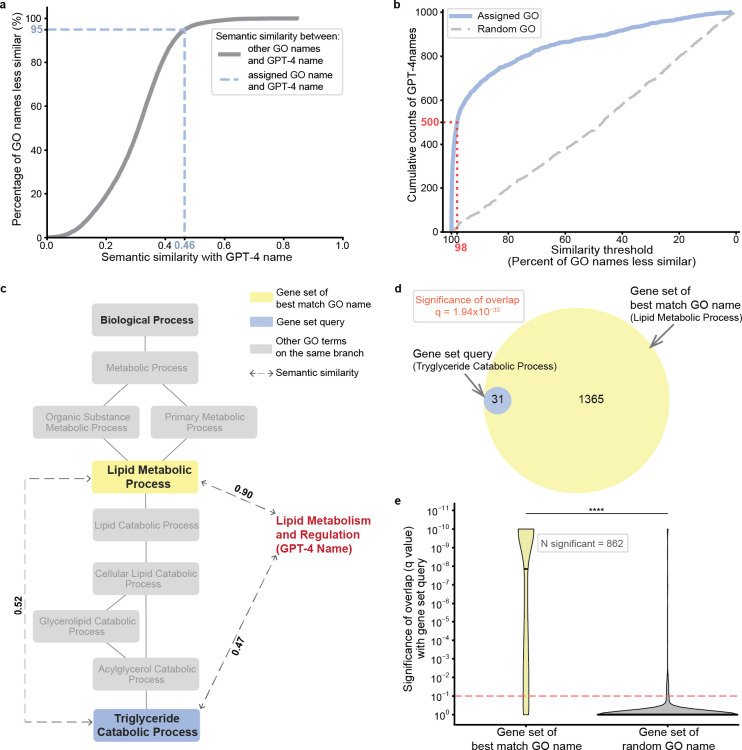
Gene set analysis is a mainstay of functional genomics, but it relies on manually curated databases of gene functions that are incomplete and unaware of biological context. Here we evaluate the ability of OpenAI's GPT-4, a Large Language Model (LLM), to develop hypotheses about common gene functions from its embedded biomedical knowledge. We created a GPT-4 pipeline to label gene sets with names that summarize their consensus functions, substantiated by analysis text and citations. Benchmarking against named gene sets in the Gene Ontology, GPT-4 generated very similar names in 50% of cases, while in most remaining cases it recovered the name of a more general concept. In gene sets discovered in 'omics data, GPT-4 names were more informative than gene set enrichment, with supporting statements and citations that largely verified in human review. The ability to rapidly synthesize common gene functions positions LLMs as valuable functional genomics assistants.
基因集分析是功能基因组学的支柱,但它依赖于人工策划的基因功能数据库,这些数据库并不完整,且未考虑生物学背景。在这里,我们评估了大型语言模型(LLM)OpenAI的GPT-4从其嵌入的生物医学知识中得出常见基因功能假设的能力。我们创建了一个GPT-4管道,用概括其共识功能的名称标记基因集,并通过分析文本和引用进行证实。与基因本体论中的命名基因集进行基准测试,GPT-4在50%的情况下生成了非常相似的名称,而在大多数其余情况下,它恢复了一个更通用概念的名称。在“组学”数据中发现的基因集中,GPT-4给出的名称比基因集富集分析更具信息性,其支持性陈述和引用在人工审核中大多得到了验证。快速合成常见基因功能的能力使大型语言模型成为有价值的功能基因组学助手。