Medina Jorge, White Andrew D
Department of Chemical Engineering, University of Rochester, Rochester, NY, USA.
J Cheminform. 2023 Oct 12;15(1):95. doi: 10.1186/s13321-023-00765-1.
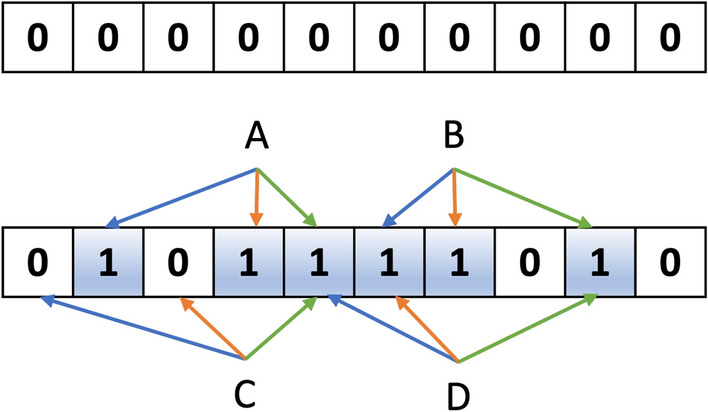
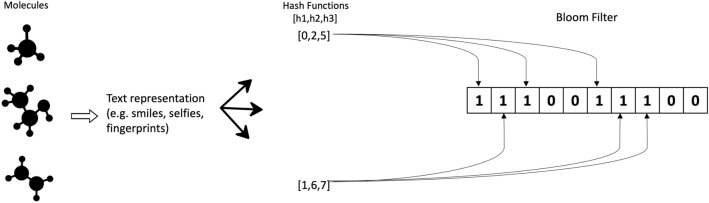
Ultra-large chemical libraries are reaching 10s to 100s of billions of molecules. A challenge for these libraries is to efficiently check if a proposed molecule is present. Here we propose and study Bloom filters for testing if a molecule is present in a set using either string or fingerprint representations. Bloom filters are small enough to hold billions of molecules in just a few GB of memory and check membership in sub milliseconds. We found string representations can have a false positive rate below 1% and require significantly less storage than using fingerprints. Canonical SMILES with Bloom filters with the simple FNV (Fowler-Noll-Voll) hashing function provide fast and accurate membership tests with small memory requirements. We provide a general implementation and specific filters for detecting if a molecule is purchasable, patented, or a natural product according to existing databases at https://github.com/whitead/molbloom .
超大型化学文库的规模已达 tens 到 1000 亿个分子。这些文库面临的一个挑战是要高效地检查某个提议的分子是否存在。在此,我们提出并研究布隆过滤器,用于使用字符串或指纹表示法来测试某个分子是否存在于一个集合中。布隆过滤器足够小,仅需几GB内存就能容纳数十亿个分子,并能在亚毫秒级时间内检查成员资格。我们发现,字符串表示法的误报率可低于1%,且与使用指纹相比,所需存储空间显著更少。带有简单FNV(Fowler-Noll-Voll)哈希函数的布隆过滤器的规范SMILES能以小内存需求提供快速且准确的成员资格测试。我们在https://github.com/whitead/molbloom上提供了一个通用实现以及用于根据现有数据库检测某个分子是否可购买、是否有专利或是否为天然产物的特定过滤器。