Li Jianfu, Li Yiming, Pan Yuanyi, Guo Jinjing, Sun Zenan, Li Fang, He Yongqun, Tao Cui
The University of Texas Health Science Center at Houston.
University of Michigan Medical School.
Res Sq. 2023 Sep 27:rs.3.rs-3362256. doi: 10.21203/rs.3.rs-3362256/v1.
Vaccines have revolutionized public health by providing protection against infectious diseases. They stimulate the immune system and generate memory cells to defend against targeted diseases. Clinical trials evaluate vaccine performance, including dosage, administration routes, and potential side effects. ClinicalTrials.gov is a valuable repository of clinical trial information, but the vaccine data in them lacks standardization, leading to challenges in automatic concept mapping, vaccine-related knowledge development, evidence-based decision-making, and vaccine surveillance.
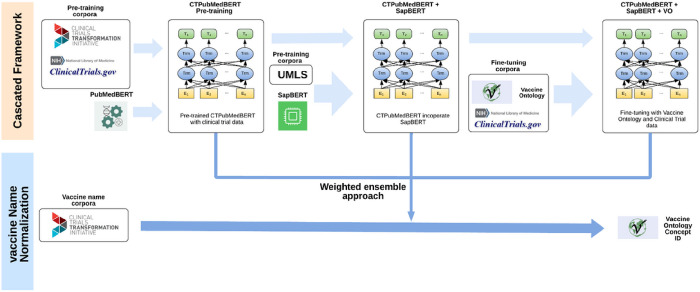
In this study, we developed a cascaded framework that capitalized on multiple domain knowledge sources, including clinical trials, Unified Medical Language System (UMLS), and the Vaccine Ontology (VO), to enhance the performance of domain-specific language models for automated mapping of VO from clinical trials. The Vaccine Ontology (VO) is a community-based ontology that was developed to promote vaccine data standardization, integration, and computer-assisted reasoning. Our methodology involved extracting and annotating data from various sources. We then performed pre-training on the PubMedBERT model, leading to the development of CTPubMedBERT. Subsequently, we enhanced CTPubMedBERT by incorporating SAPBERT, which was pretrained using the UMLS, resulting in CTPubMedBERT + SAPBERT. Further refinement was accomplished through fine-tuning using the Vaccine Ontology corpus and vaccine data from clinical trials, yielding the CTPubMedBERT + SAPBERT + VO model. Finally, we utilized a collection of pre-trained models, along with the weighted rule-based ensemble approach, to normalize the vaccine corpus and improve the accuracy of the process. The ranking process in concept normalization involves prioritizing and ordering potential concepts to identify the most suitable match for a given context. We conducted a ranking of the Top 10 concepts, and our experimental results demonstrate that our proposed cascaded framework consistently outperformed existing effective baselines on vaccine mapping, achieving 71.8% on top 1 candidate's accuracy and 90.0% on top 10 candidate's accuracy.
This study provides a detailed insight into a cascaded framework of fine-tuned domain-specific language models improving mapping of VO from clinical trials. By effectively leveraging domain-specific information and applying weighted rule-based ensembles of different pre-trained BERT models, our framework can significantly enhance the mapping of VO from clinical trials.
疫苗通过提供针对传染病的保护,彻底改变了公共卫生状况。它们刺激免疫系统并产生记忆细胞,以抵御特定疾病。临床试验评估疫苗性能,包括剂量、给药途径和潜在副作用。ClinicalTrials.gov是临床试验信息的宝贵存储库,但其中的疫苗数据缺乏标准化,导致在自动概念映射、疫苗相关知识开发、循证决策和疫苗监测方面存在挑战。
在本研究中,我们开发了一个级联框架,该框架利用了多个领域知识源,包括临床试验、统一医学语言系统(UMLS)和疫苗本体(VO),以提高特定领域语言模型从临床试验中自动映射VO的性能。疫苗本体(VO)是一个基于社区的本体,旨在促进疫苗数据的标准化、整合和计算机辅助推理。我们的方法包括从各种来源提取和注释数据。然后,我们在PubMedBERT模型上进行预训练,开发出CTPubMedBERT。随后,我们通过合并使用UMLS进行预训练的SAPBERT来增强CTPubMedBERT,得到CTPubMedBERT + SAPBERT。通过使用疫苗本体语料库和来自临床试验的疫苗数据进行微调,进一步优化,得到CTPubMedBERT + SAPBERT + VO模型。最后,我们利用一组预训练模型以及基于加权规则的集成方法,对疫苗语料库进行标准化并提高该过程的准确性。概念标准化中的排序过程涉及对潜在概念进行优先级排序和排序,以确定给定上下文中最合适的匹配。我们对前10个概念进行了排序,实验结果表明,我们提出的级联框架在疫苗映射方面始终优于现有的有效基线,在顶级1候选准确率上达到71.8%,在顶级10候选准确率上达到90.0%。
本研究详细介绍了一个微调特定领域语言模型的级联框架,该框架改进了从临床试验中映射VO的过程。通过有效利用特定领域信息并应用不同预训练BERT模型的基于加权规则的集成,我们的框架可以显著增强从临床试验中映射VO的能力。