R&D department, Insilico Medicine Hong Kong, 999077 Pak Shek Kok, Hong Kong.
Bioinformatics. 2021 Nov 5;37(21):3856-3864. doi: 10.1093/bioinformatics/btab474.
Clinical trials are the essential stage of every drug development program for the treatment to become available to patients. Despite the importance of well-structured clinical trial databases and their tremendous value for drug discovery and development such instances are very rare. Presently large-scale information on clinical trials is stored in clinical trial registers which are relatively structured, but the mappings to external databases of drugs and diseases are increasingly lacking. The precise production of such links would enable us to interrogate richer harmonized datasets for invaluable insights.
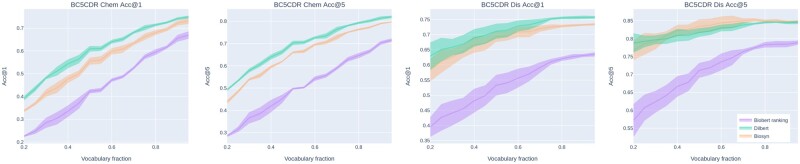
We present a neural approach for medical concept normalization of diseases and drugs. Our two-stage approach is based on Bidirectional Encoder Representations from Transformers (BERT). In the training stage, we optimize the relative similarity of mentions and concept names from a terminology via triplet loss. In the inference stage, we obtain the closest concept name representation in a common embedding space to a given mention representation. We performed a set of experiments on a dataset of abstracts and a real-world dataset of trial records with interventions and conditions mapped to drug and disease terminologies. The latter includes mentions associated with one or more concepts (in-KB) or zero (out-of-KB, nil prediction). Experiments show that our approach significantly outperforms baseline and state-of-the-art architectures. Moreover, we demonstrate that our approach is effective in knowledge transfer from the scientific literature to clinical trial data.
We make code and data freely available at https://github.com/insilicomedicine/DILBERT.
临床试验是每个治疗药物开发计划的重要阶段,使治疗方法能够为患者所用。尽管有结构良好的临床试验数据库非常重要,而且对药物发现和开发具有巨大价值,但这种情况非常罕见。目前,大规模的临床试验信息存储在临床试验登记处,这些登记处相对结构化,但与药物和疾病的外部数据库的映射越来越缺乏。这些链接的精确生成将使我们能够查询更丰富的协调数据集,以获得宝贵的见解。
我们提出了一种用于疾病和药物的医学概念规范化的神经方法。我们的两阶段方法基于来自 Transformer 的双向编码器表示(BERT)。在训练阶段,我们通过三元组损失优化了术语中提及和概念名称的相对相似性。在推断阶段,我们在一个常见的嵌入空间中获得给定提及表示的最接近的概念名称表示。我们在一个摘要数据集和一个包含干预措施和条件的真实试验记录数据集上进行了一系列实验,这些数据集映射到药物和疾病术语。后者包括与一个或多个概念相关的提及(在 KB 中)或零(在 KB 之外,无预测)。实验表明,我们的方法明显优于基线和最先进的架构。此外,我们证明了我们的方法在从科学文献到临床试验数据的知识转移方面是有效的。
我们在 https://github.com/insilicomedicine/DILBERT 上免费提供代码和数据。