Riaz Shazia, Ali Saqib, Wang Guojun, Latif Muhammad Ahsan, Iqbal Muhammad Zafar
School of Computing, Macquarie University, Sydney, Australia.
Department of Computer Science, University of Agriculture, Faisalabad, Punjab, Pakistan.
PeerJ Comput Sci. 2023 Oct 5;9:e1616. doi: 10.7717/peerj-cs.1616. eCollection 2023.
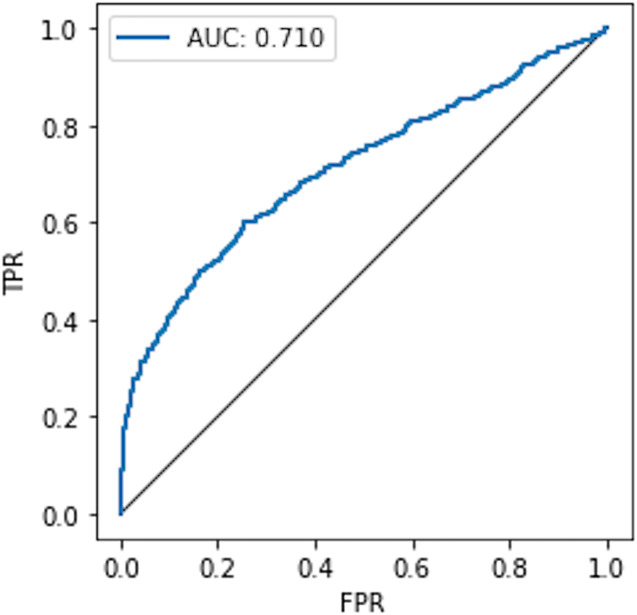
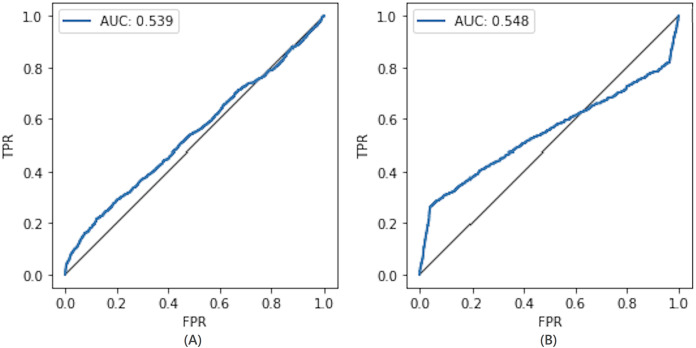
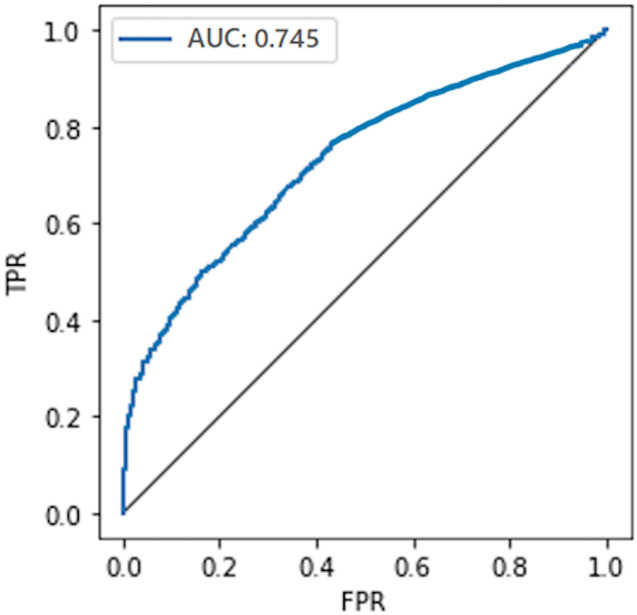
The extraordinary success of deep learning is made possible due to the availability of crowd-sourced large-scale training datasets. Mostly, these datasets contain personal and confidential information, thus, have great potential of being misused, raising privacy concerns. Consequently, privacy-preserving deep learning has become a primary research interest nowadays. One of the prominent approaches adopted to prevent the leakage of sensitive information about the training data is by implementing differential privacy during training for their differentially private training, which aims to preserve the privacy of deep learning models. Though these models are claimed to be a safeguard against privacy attacks targeting sensitive information, however, least amount of work is found in the literature to practically evaluate their capability by performing a sophisticated attack model on them. Recently, DP-BCD is proposed as an alternative to state-of-the-art DP-SGD, to preserve the privacy of deep-learning models, having low privacy cost and fast convergence speed with highly accurate prediction results. To check its practical capability, in this article, we analytically evaluate the impact of a sophisticated privacy attack called the membership inference attack against it in both black box as well as white box settings. More precisely, we inspect how much information can be inferred from a differentially private deep model's training data. We evaluate our experiments on benchmark datasets using AUC, attacker advantage, precision, recall, and F1-score performance metrics. The experimental results exhibit that DP-BCD keeps its promise to preserve privacy against strong adversaries while providing acceptable model utility compared to state-of-the-art techniques.
深度学习取得非凡成功,得益于众包大规模训练数据集的可用性。大多数情况下,这些数据集包含个人和机密信息,因此极有可能被滥用,引发了隐私担忧。因此,隐私保护深度学习已成为当下主要的研究热点。为防止训练数据的敏感信息泄露而采用的一种突出方法,是在训练期间实施差分隐私进行差分隐私训练,其目的是保护深度学习模型的隐私。尽管这些模型据称能防范针对敏感信息的隐私攻击,然而,在文献中发现几乎没有工作通过对它们执行复杂的攻击模型来实际评估其能力。最近,提出了DP-BCD作为现有技术DP-SGD的替代方案,以保护深度学习模型的隐私,具有低隐私成本和快速收敛速度以及高度准确的预测结果。为检验其实际能力,在本文中,我们在黑盒和白盒设置下,通过分析评估一种名为成员推理攻击的复杂隐私攻击对它的影响。更确切地说,我们研究能从差分隐私深度模型的训练数据中推断出多少信息。我们使用AUC、攻击者优势、精确率、召回率和F1分数性能指标在基准数据集上评估我们的实验。实验结果表明,与现有技术相比,DP-BCD在保护隐私免受强大对手攻击方面兑现了承诺,同时提供了可接受的模型效用。