Division of Pharmacology, Utrecht Institute for Pharmaceutical Sciences, Faculty of Science, University of Utrecht, Utrecht, The Netherlands.
Department of Data Science, Julius Center for Health Sciences and Primary Care, University Medical Center Utrecht, Utrecht, The Netherlands.
BMC Bioinformatics. 2024 Jan 15;25(1):26. doi: 10.1186/s12859-024-05639-3.
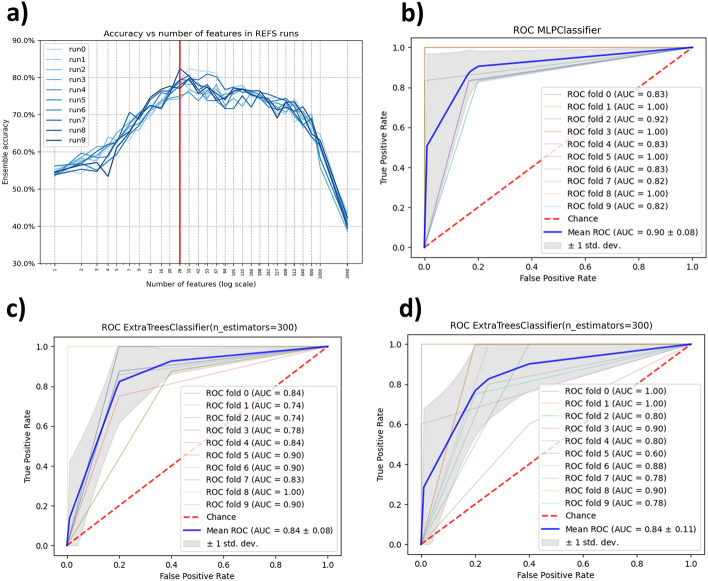
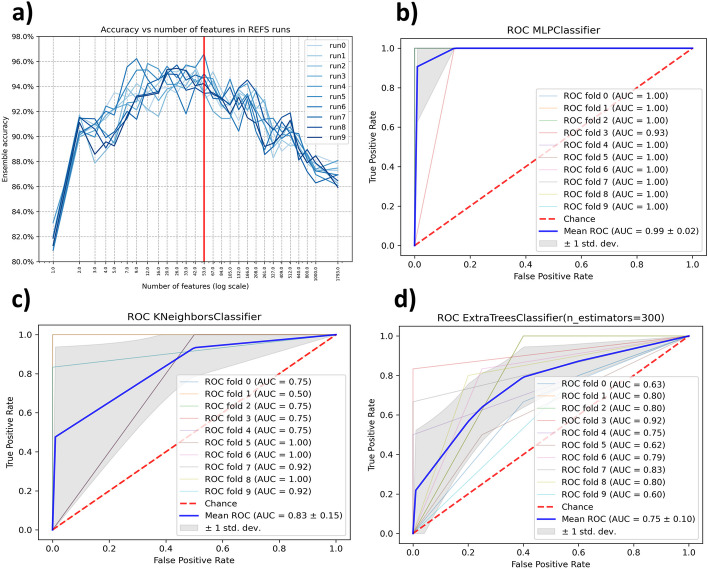
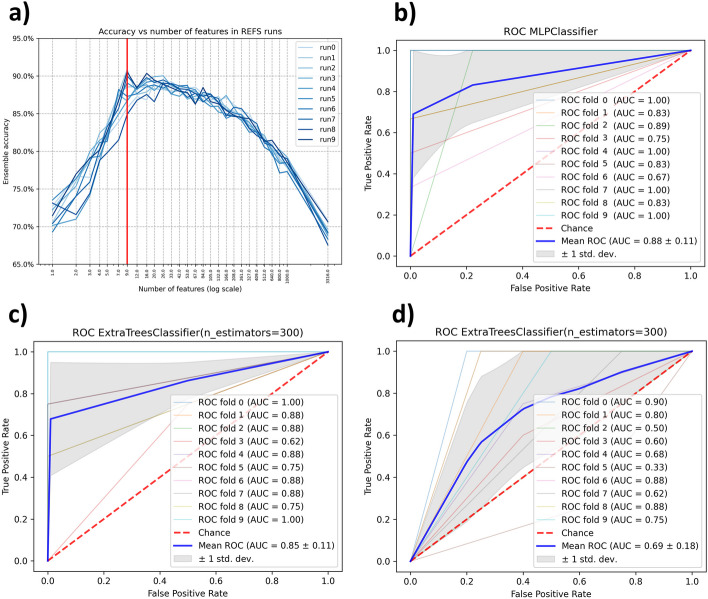
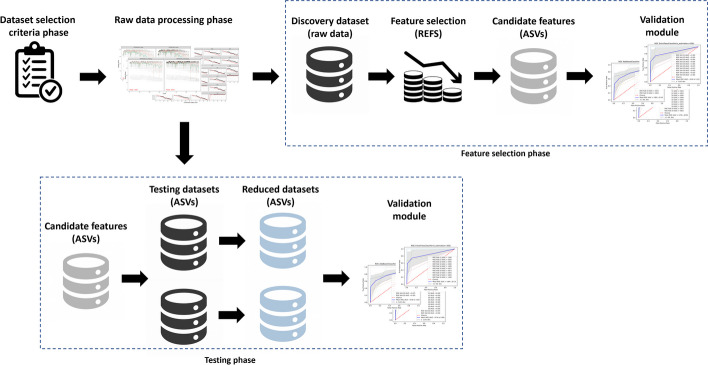
In recent years, human microbiome studies have received increasing attention as this field is considered a potential source for clinical applications. With the advancements in omics technologies and AI, research focused on the discovery for potential biomarkers in the human microbiome using machine learning tools has produced positive outcomes. Despite the promising results, several issues can still be found in these studies such as datasets with small number of samples, inconsistent results, lack of uniform processing and methodologies, and other additional factors lead to lack of reproducibility in biomedical research. In this work, we propose a methodology that combines the DADA2 pipeline for 16s rRNA sequences processing and the Recursive Ensemble Feature Selection (REFS) in multiple datasets to increase reproducibility and obtain robust and reliable results in biomedical research.
Three experiments were performed analyzing microbiome data from patients/cases in Inflammatory Bowel Disease (IBD), Autism Spectrum Disorder (ASD), and Type 2 Diabetes (T2D). In each experiment, we found a biomarker signature in one dataset and applied to 2 other as further validation. The effectiveness of the proposed methodology was compared with other feature selection methods such as K-Best with F-score and random selection as a base line. The Area Under the Curve (AUC) was employed as a measure of diagnostic accuracy and used as a metric for comparing the results of the proposed methodology with other feature selection methods. Additionally, we use the Matthews Correlation Coefficient (MCC) as a metric to evaluate the performance of the methodology as well as for comparison with other feature selection methods.
We developed a methodology for reproducible biomarker discovery for 16s rRNA microbiome sequence analysis, addressing the issues related with data dimensionality, inconsistent results and validation across independent datasets. The findings from the three experiments, across 9 different datasets, show that the proposed methodology achieved higher accuracy compared to other feature selection methods. This methodology is a first approach to increase reproducibility, to provide robust and reliable results.
近年来,人类微生物组研究受到越来越多的关注,因为该领域被认为是临床应用的潜在来源。随着组学技术和人工智能的进步,使用机器学习工具在人类微生物组中发现潜在生物标志物的研究取得了积极的成果。尽管结果很有前景,但在这些研究中仍然存在一些问题,例如样本数量少的数据集、不一致的结果、缺乏统一的处理和方法以及其他额外的因素导致生物医学研究的可重复性差。在这项工作中,我们提出了一种方法,该方法结合了 16s rRNA 序列处理的 DADA2 管道和多个数据集的递归集成特征选择(REFS),以提高可重复性并在生物医学研究中获得稳健可靠的结果。
进行了三个实验,分析了炎症性肠病(IBD)、自闭症谱系障碍(ASD)和 2 型糖尿病(T2D)患者/病例的微生物组数据。在每个实验中,我们在一个数据集中找到了一个生物标志物特征,并将其应用于另外两个数据集中进行进一步验证。所提出方法的有效性与其他特征选择方法(例如基于 F 分数的 K-Best 和随机选择作为基线)进行了比较。曲线下面积(AUC)被用作诊断准确性的度量标准,并用作比较所提出方法与其他特征选择方法的结果的指标。此外,我们使用马修斯相关系数(MCC)作为度量标准来评估该方法的性能以及与其他特征选择方法的比较。
我们开发了一种用于 16s rRNA 微生物组序列分析的可重复生物标志物发现的方法,解决了与数据维度、不一致结果和跨独立数据集验证相关的问题。三个实验的结果,跨越 9 个不同的数据集,表明所提出的方法与其他特征选择方法相比,达到了更高的准确性。该方法是提高可重复性、提供稳健可靠结果的一种初步尝试。