Hatia Arjeta, Doldo Tiziana, Parrini Stefano, Chisci Elettra, Cipriani Linda, Montagna Livia, Lagana Giuseppina, Guenza Guia, Agosta Edoardo, Vinjolli Franceska, Hoxha Meladiona, D'Amelio Claudio, Favaretto Nicolò, Chisci Glauco
Orthodontics Postgraduate School, Department of Medical Biotechnologies, University of Siena, 53100 Siena, Italy.
Oral Surgery Postgraduate School, Department of Medical Biotechnologies, University of Siena, 53100 Siena, Italy.
J Clin Med. 2024 Jan 27;13(3):735. doi: 10.3390/jcm13030735.
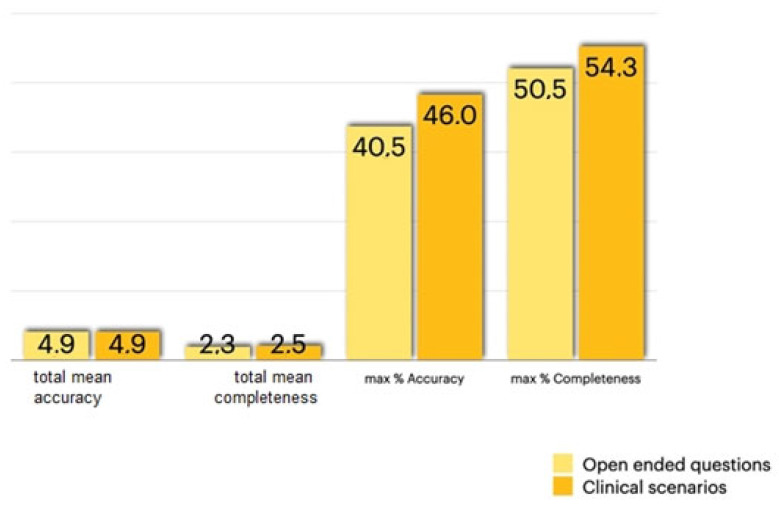
: this study aims to investigate the accuracy and completeness of ChatGPT in answering questions and solving clinical scenarios of interceptive orthodontics. : ten specialized orthodontists from ten Italian postgraduate orthodontics schools developed 21 clinical open-ended questions encompassing all of the subspecialities of interceptive orthodontics and 7 comprehensive clinical cases. Questions and scenarios were inputted into ChatGPT4, and the resulting answers were evaluated by the researchers using predefined accuracy (range 1-6) and completeness (range 1-3) Likert scales. : For the open-ended questions, the overall median score was 4.9/6 for the accuracy and 2.4/3 for completeness. In addition, the reviewers rated the accuracy of open-ended answers as entirely correct (score 6 on Likert scale) in 40.5% of cases and completeness as entirely correct (score 3 n Likert scale) in 50.5% of cases. As for the clinical cases, the overall median score was 4.9/6 for accuracy and 2.5/3 for completeness. Overall, the reviewers rated the accuracy of clinical case answers as entirely correct in 46% of cases and the completeness of clinical case answers as entirely correct in 54.3% of cases. : The results showed a high level of accuracy and completeness in AI responses and a great ability to solve difficult clinical cases, but the answers were not 100% accurate and complete. ChatGPT is not yet sophisticated enough to replace the intellectual work of human beings.
本研究旨在调查ChatGPT在回答问题及解决阻断性正畸临床场景方面的准确性和完整性。来自十所意大利正畸研究生院校的十位专业正畸医生设计了21个涵盖阻断性正畸所有亚专业的临床开放式问题以及7个综合临床病例。问题和场景被输入到ChatGPT4中,研究人员使用预先定义的准确性(范围为1 - 6)和完整性(范围为1 - 3)李克特量表对所得答案进行评估。对于开放式问题,准确性的总体中位数分数为4.9/6,完整性为2.4/3。此外,评审人员将40.5%的开放式答案的准确性评为完全正确(李克特量表上得分为6),50.5%的答案的完整性评为完全正确(李克特量表上得分为3)。至于临床病例,准确性的总体中位数分数为4.9/6,完整性为2.5/3。总体而言,评审人员将46%的临床病例答案的准确性评为完全正确,54.3%的临床病例答案的完整性评为完全正确。结果显示人工智能的回答具有较高的准确性和完整性,且有很强的解决复杂临床病例的能力,但答案并非100%准确和完整。ChatGPT还不够成熟,无法取代人类的智力工作。