Johnson Douglas, Goodman Rachel, Patrinely J, Stone Cosby, Zimmerman Eli, Donald Rebecca, Chang Sam, Berkowitz Sean, Finn Avni, Jahangir Eiman, Scoville Elizabeth, Reese Tyler, Friedman Debra, Bastarache Julie, van der Heijden Yuri, Wright Jordan, Carter Nicholas, Alexander Matthew, Choe Jennifer, Chastain Cody, Zic John, Horst Sara, Turker Isik, Agarwal Rajiv, Osmundson Evan, Idrees Kamran, Kieman Colleen, Padmanabhan Chandrasekhar, Bailey Christina, Schlegel Cameron, Chambless Lola, Gibson Mike, Osterman Travis, Wheless Lee
Vanderbilt University Medical Center.
Vanderbilt University School of Medicine.
Res Sq. 2023 Feb 28:rs.3.rs-2566942. doi: 10.21203/rs.3.rs-2566942/v1.
Natural language processing models such as ChatGPT can generate text-based content and are poised to become a major information source in medicine and beyond. The accuracy and completeness of ChatGPT for medical queries is not known.
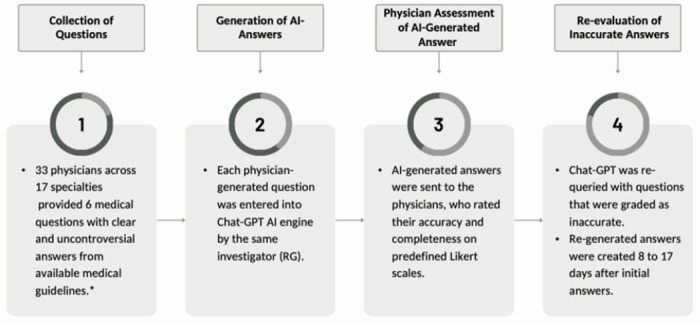
Thirty-three physicians across 17 specialties generated 284 medical questions that they subjectively classified as easy, medium, or hard with either binary (yes/no) or descriptive answers. The physicians then graded ChatGPT-generated answers to these questions for accuracy (6-point Likert scale; range 1 - completely incorrect to 6 - completely correct) and completeness (3-point Likert scale; range 1 - incomplete to 3 - complete plus additional context). Scores were summarized with descriptive statistics and compared using Mann-Whitney U or Kruskal-Wallis testing.
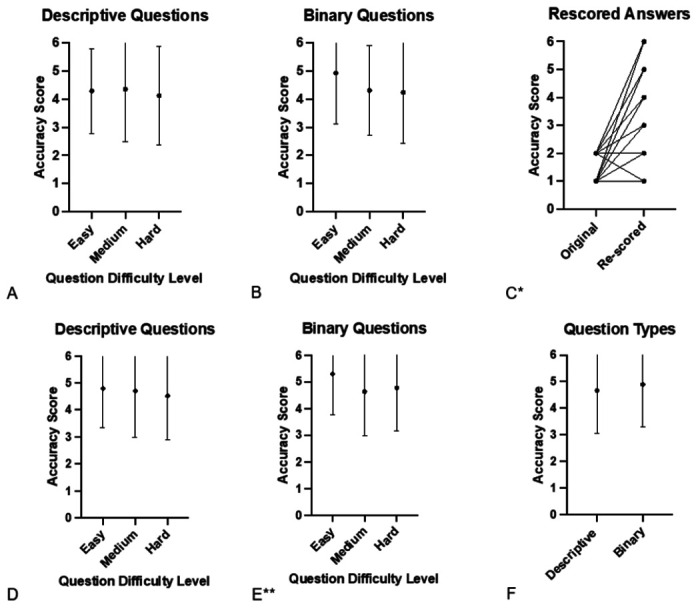
Across all questions (n=284), median accuracy score was 5.5 (between almost completely and completely correct) with mean score of 4.8 (between mostly and almost completely correct). Median completeness score was 3 (complete and comprehensive) with mean score of 2.5. For questions rated easy, medium, and hard, median accuracy scores were 6, 5.5, and 5 (mean 5.0, 4.7, and 4.6; p=0.05). Accuracy scores for binary and descriptive questions were similar (median 6 vs. 5; mean 4.9 vs. 4.7; p=0.07). Of 36 questions with scores of 1-2, 34 were re-queried/re-graded 8-17 days later with substantial improvement (median 2 vs. 4; p<0.01).
ChatGPT generated largely accurate information to diverse medical queries as judged by academic physician specialists although with important limitations. Further research and model development are needed to correct inaccuracies and for validation.
诸如ChatGPT之类的自然语言处理模型可以生成基于文本的内容,并有望成为医学及其他领域的主要信息来源。ChatGPT针对医学问题的准确性和完整性尚不清楚。
来自17个专业的33名医生提出了284个医学问题,他们主观地将这些问题分类为简单、中等或困难,并给出二元(是/否)或描述性答案。然后,医生们对ChatGPT针对这些问题生成的答案进行准确性(6点李克特量表;范围从1 - 完全错误到6 - 完全正确)和完整性(3点李克特量表;范围从1 - 不完整到3 - 完整并附带额外背景信息)评分。分数通过描述性统计进行汇总,并使用曼-惠特尼U检验或克鲁斯卡尔-沃利斯检验进行比较。
在所有问题(n = 284)中,准确性中位数得分为5.5(介于几乎完全正确和完全正确之间),平均得分为4.8(介于大部分正确和几乎完全正确之间)。完整性中位数得分为3(完整且全面),平均得分为2.5。对于评为简单、中等和困难的问题,准确性中位数得分分别为6、5.5和5(平均分别为5.0、4.7和4.6;p = 0.05)。二元问题和描述性问题的准确性得分相似(中位数分别为6对5;平均分别为4.9对4.7;p = 0.07)。在36个得分为1 - 2的问题中,34个在8 - 17天后重新提问/重新评分,有显著改善(中位数分别为2对4;p < 0.01)。
尽管存在重要局限性,但学术医生专家判断ChatGPT针对各种医学问题生成的信息在很大程度上是准确的。需要进一步的研究和模型开发来纠正不准确之处并进行验证。