Nakao Takahiro, Miki Soichiro, Nakamura Yuta, Kikuchi Tomohiro, Nomura Yukihiro, Hanaoka Shouhei, Yoshikawa Takeharu, Abe Osamu
Department of Computational Diagnostic Radiology and Preventive Medicine, The University of Tokyo Hospital, Bunkyo-ku, Tokyo, Japan.
Department of Radiology, School of Medicine, Jichi Medical University, Shimotsuke, Tochigi, Japan.
JMIR Med Educ. 2024 Mar 12;10:e54393. doi: 10.2196/54393.
Previous research applying large language models (LLMs) to medicine was focused on text-based information. Recently, multimodal variants of LLMs acquired the capability of recognizing images.
We aim to evaluate the image recognition capability of generative pretrained transformer (GPT)-4V, a recent multimodal LLM developed by OpenAI, in the medical field by testing how visual information affects its performance to answer questions in the 117th Japanese National Medical Licensing Examination.
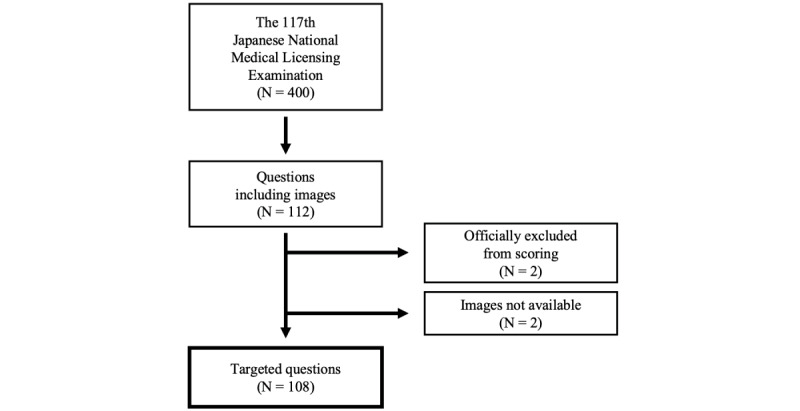
We focused on 108 questions that had 1 or more images as part of a question and presented GPT-4V with the same questions under two conditions: (1) with both the question text and associated images and (2) with the question text only. We then compared the difference in accuracy between the 2 conditions using the exact McNemar test.
Among the 108 questions with images, GPT-4V's accuracy was 68% (73/108) when presented with images and 72% (78/108) when presented without images (P=.36). For the 2 question categories, clinical and general, the accuracies with and those without images were 71% (70/98) versus 78% (76/98; P=.21) and 30% (3/10) versus 20% (2/10; P≥.99), respectively.
The additional information from the images did not significantly improve the performance of GPT-4V in the Japanese National Medical Licensing Examination.
以往将大语言模型(LLMs)应用于医学领域的研究主要集中在基于文本的信息上。最近,大语言模型的多模态变体获得了图像识别能力。
我们旨在通过测试视觉信息如何影响其在第117届日本国家医师资格考试中回答问题的表现,来评估由OpenAI开发的最新多模态大语言模型生成式预训练变换器(GPT)-4V在医学领域的图像识别能力。
我们聚焦于108道包含1张或更多图像作为问题一部分的题目,并在两种条件下向GPT-4V呈现相同的问题:(1)同时呈现问题文本和相关图像;(2)仅呈现问题文本。然后,我们使用精确的麦克尼马尔检验比较两种条件下准确率的差异。
在108道有图像的题目中,呈现图像时GPT-4V的准确率为68%(73/108),不呈现图像时为72%(78/108)(P = 0.36)。对于临床和综合这两类问题,有图像和无图像时的准确率分别为71%(70/98)对78%(76/98;P = 0.21)以及30%(3/10)对20%(2/10;P≥0.99)。
在日本国家医师资格考试中,图像提供的额外信息并未显著提高GPT-4V的表现。