Schetinger V, Di Bartolomeo S, El-Assady M, McNutt A, Miller M, Passos J P A, Adams J L
TU Wien.
Northeastern University.
Comput Graph Forum. 2023 Jun;42(3):423-435. doi: 10.1111/cgf.14841. Epub 2023 Jun 27.
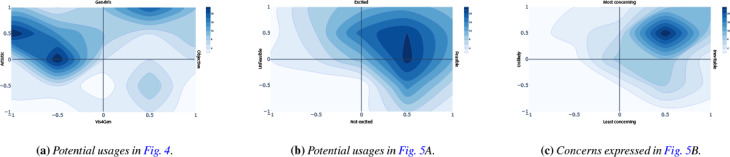
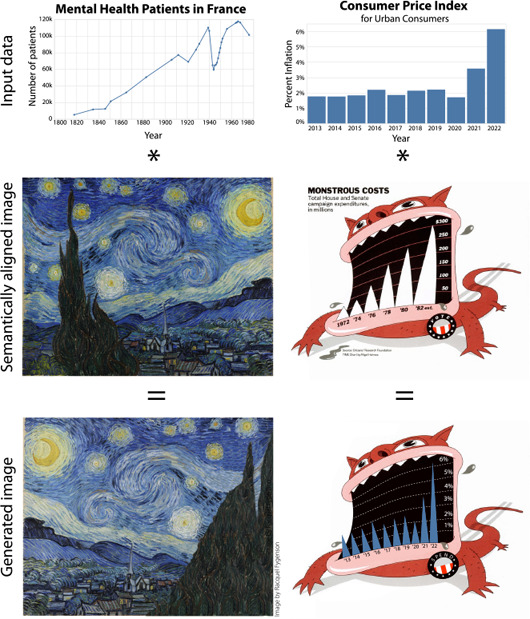
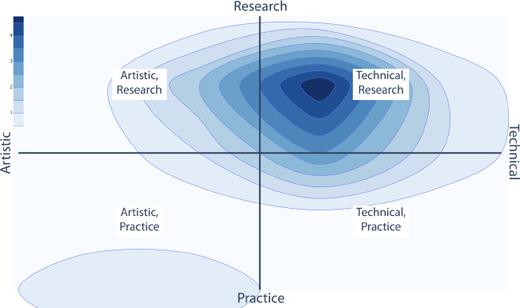
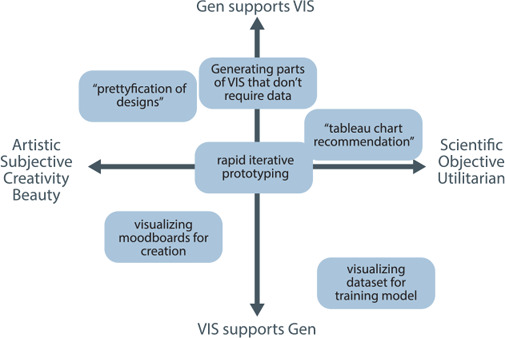
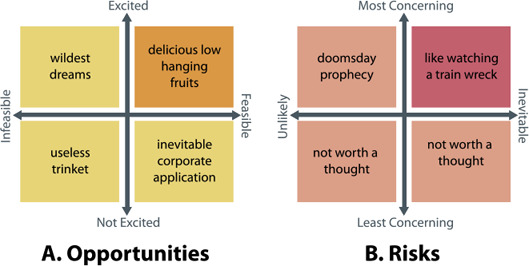
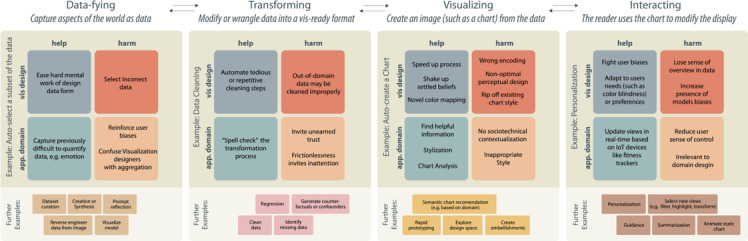
Generative text-to-image models (as exemplified by DALL-E, MidJourney, and Stable Diffusion) have recently made enormous technological leaps, demonstrating impressive results in many graphical domains-from logo design to digital painting to photographic composition. However, the quality of these results has led to existential crises in some fields of art, leading to questions about the role of human agency in the production of meaning in a graphical context. Such issues are central to visualization, and while these generative models have yet to be widely applied in visualization, it seems only a matter of time until their integration is manifest. Seeking to circumvent similar ponderous dilemmas, we attempt to understand the roles that generative models might play across visualization. We do so by constructing a framework that characterizes what these technologies offer at various stages of the visualization workflow, augmented and analyzed through semi-structured interviews with 21 experts from related domains. Through this work, we map the space of opportunities and risks that might arise in this intersection, identifying doomsday prophecies and delicious low-hanging fruits that are ripe for research.
生成式文本到图像模型(以DALL-E、MidJourney和Stable Diffusion为例)最近取得了巨大的技术飞跃,在许多图形领域都展示了令人印象深刻的成果——从标志设计到数字绘画再到摄影构图。然而,这些成果的质量在一些艺术领域引发了生存危机,引发了关于在图形背景下人类能动性在意义生成中所起作用的问题。此类问题是可视化的核心,虽然这些生成式模型尚未在可视化中得到广泛应用,但它们的整合似乎只是时间问题。为了规避类似的棘手困境,我们试图了解生成式模型在可视化中可能发挥的作用。我们通过构建一个框架来做到这一点,该框架描述了这些技术在可视化工作流程的各个阶段所提供的内容,并通过对来自相关领域的21位专家进行半结构化访谈进行补充和分析。通过这项工作,我们描绘了这个交叉领域可能出现的机遇和风险空间,识别出末日预言和适合研究的诱人的易事。