Scherbakov Dmitry, Hubig Nina, Jansari Vinita, Bakumenko Alexander, Lenert Leslie A
Biomedical Informatics Center, Department of Public Health Sciences, Medical University of South Carolina (MUSC), Charleston, SC 29403, United States.
Interdisciplinary Transformation University, OG 2 A-4040 Linz, Austria.
J Am Med Inform Assoc. 2025 Jun 1;32(6):1071-1086. doi: 10.1093/jamia/ocaf063.
This study aims to summarize the usage of large language models (LLMs) in the process of creating a scientific review by looking at the methodological papers that describe the use of LLMs in review automation and the review papers that mention they were made with the support of LLMs.
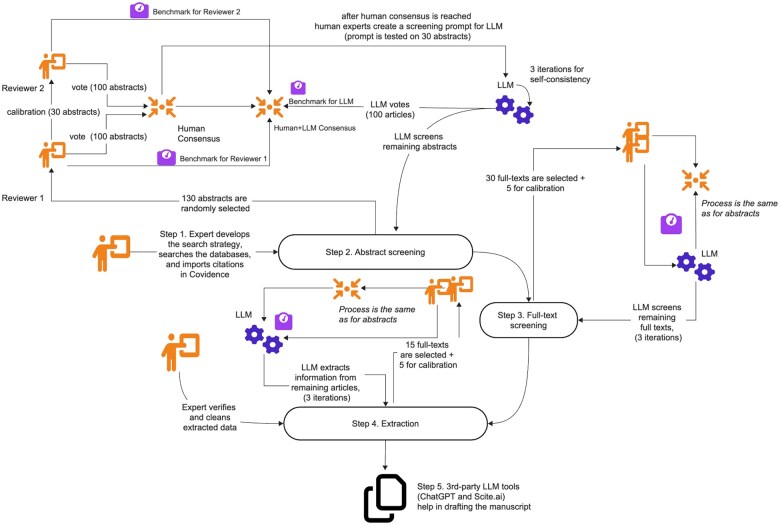
The search was conducted in June 2024 in PubMed, Scopus, Dimensions, and Google Scholar by human reviewers. Screening and extraction process took place in Covidence with the help of LLM add-on based on the OpenAI GPT-4o model. ChatGPT and Scite.ai were used in cleaning the data, generating the code for figures, and drafting the manuscript.
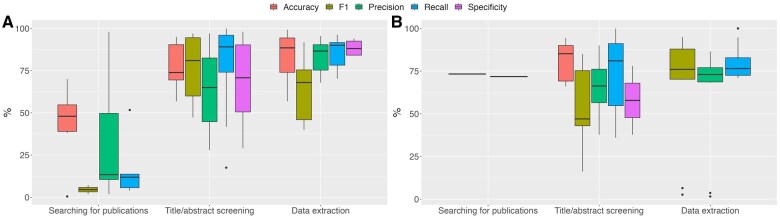
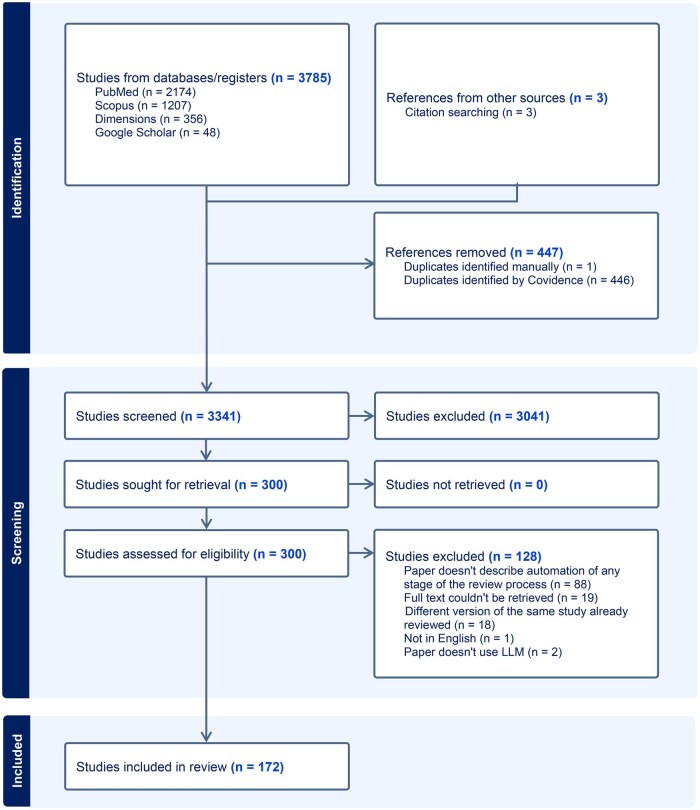
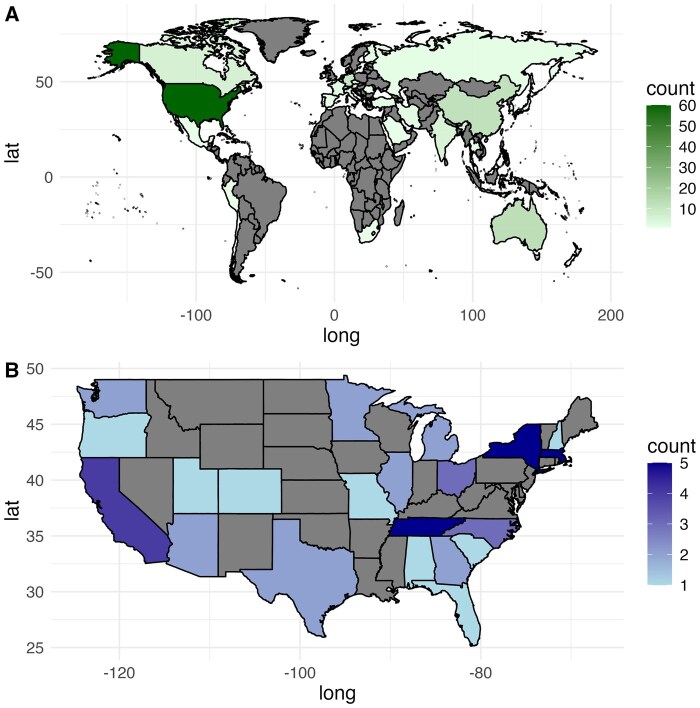
Of the 3788 articles retrieved, 172 studies were deemed eligible for the final review. ChatGPT and GPT-based LLM emerged as the most dominant architecture for review automation (n = 126, 73.2%). A significant number of review automation projects were found, but only a limited number of papers (n = 26, 15.1%) were actual reviews that acknowledged LLM usage. Most citations focused on the automation of a particular stage of review, such as Searching for publications (n = 60, 34.9%) and Data extraction (n = 54, 31.4%). When comparing the pooled performance of GPT-based and BERT-based models, the former was better in data extraction with a mean precision of 83.0% (SD = 10.4) and a recall of 86.0% (SD = 9.8).
Our LLM-assisted systematic review revealed a significant number of research projects related to review automation using LLMs. Despite limitations, such as lower accuracy of extraction for numeric data, we anticipate that LLMs will soon change the way scientific reviews are conducted.
本研究旨在通过查看描述大语言模型(LLMs)在综述自动化中使用情况的方法学论文以及提及在LLMs支持下完成的综述论文,总结大语言模型在创建科学综述过程中的使用情况。
2024年6月,由人工评审员在PubMed、Scopus、Dimensions和谷歌学术中进行检索。筛选和提取过程借助基于OpenAI GPT - 4o模型的LLM插件在Covidence中进行。使用ChatGPT和Scite.ai进行数据清理、生成图表代码以及起草稿件。
在检索到的3788篇文章中,172项研究被认为符合最终综述的条件。ChatGPT和基于GPT的大语言模型成为综述自动化中最主要的架构(n = 126,73.2%)。发现了大量的综述自动化项目,但只有有限数量的论文(n = 26,15.1%)是实际承认使用了大语言模型的综述。大多数引用集中在综述特定阶段的自动化,如搜索出版物(n = 60,34.9%)和数据提取(n = 54,31.4%)。在比较基于GPT和基于BERT的模型的综合性能时,前者在数据提取方面表现更好,平均精度为83.0%(标准差 = 10.4),召回率为86.0%(标准差 = 9.8)。
我们的大语言模型辅助系统综述揭示了大量与使用大语言模型进行综述自动化相关的研究项目。尽管存在局限性,如数值数据提取的准确性较低,但我们预计大语言模型将很快改变科学综述的进行方式。