Department of Computer Science, College of Computing and Information Technology, Arab Academy of Science, Technology & Maritime Transport, Alexandria, Egypt.
Mechatronics Engineering Department, Faculty of Engineering, Horus University Egypt, New Damietta, Egypt.
PLoS One. 2024 Apr 3;19(4):e0300641. doi: 10.1371/journal.pone.0300641. eCollection 2024.
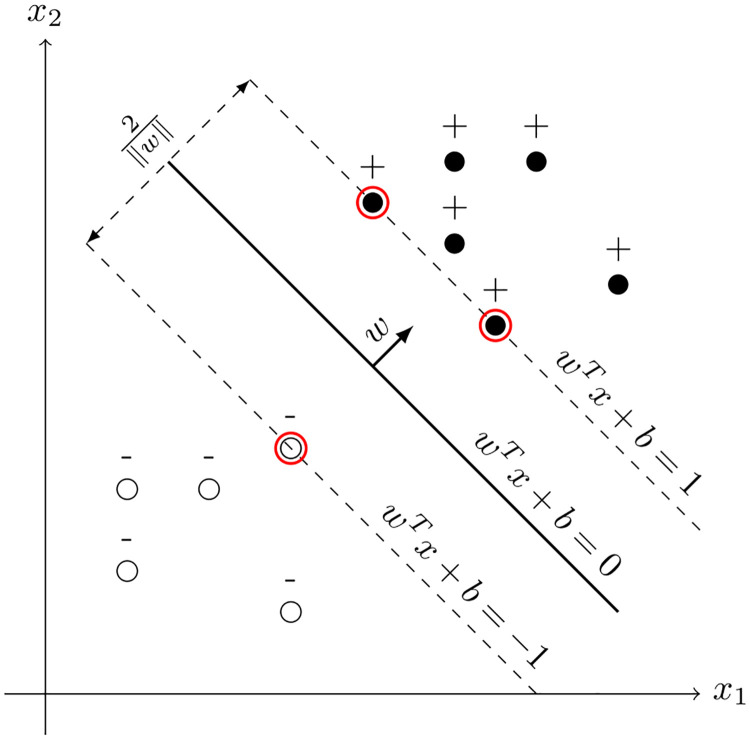
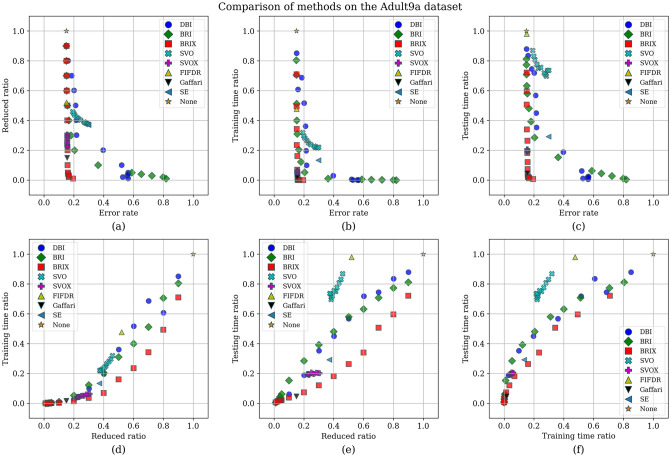
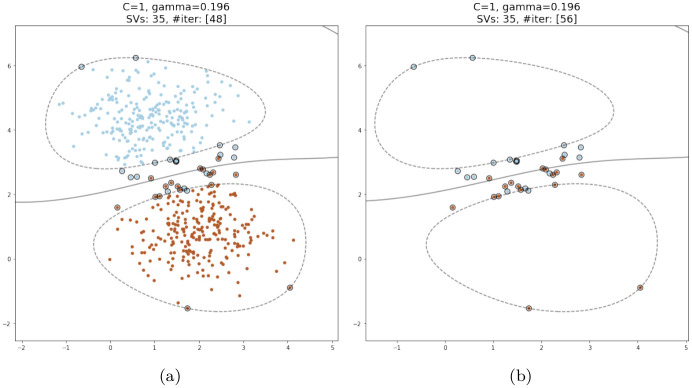
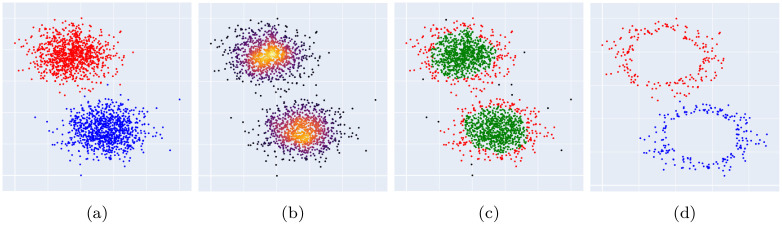
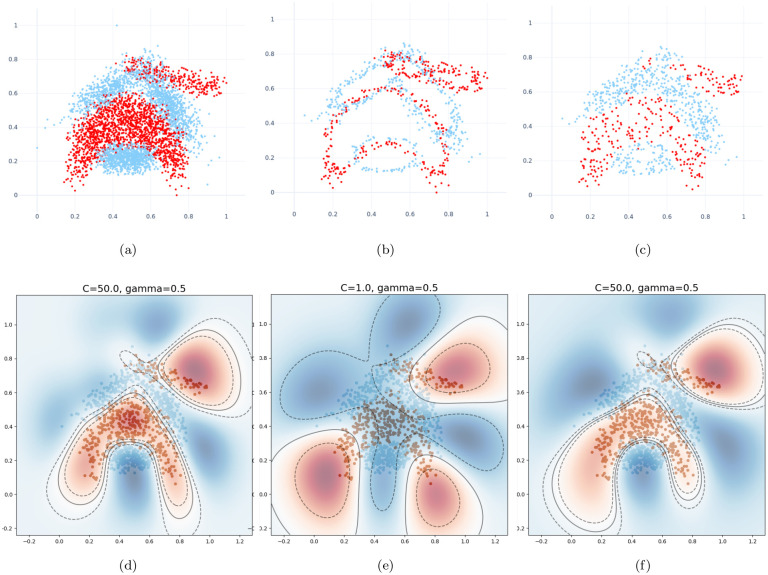
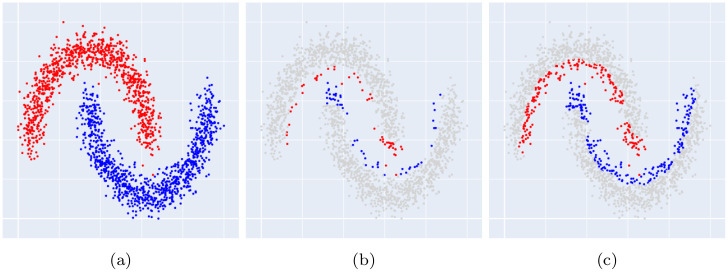
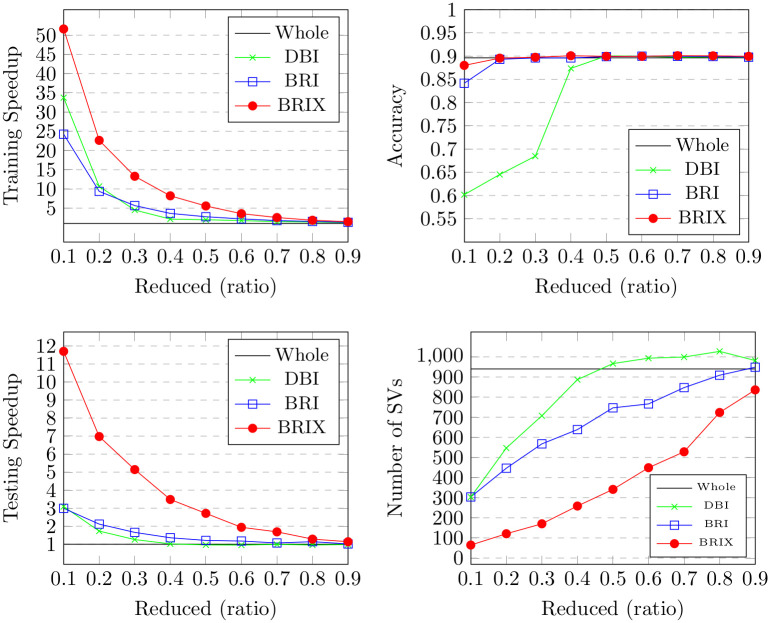
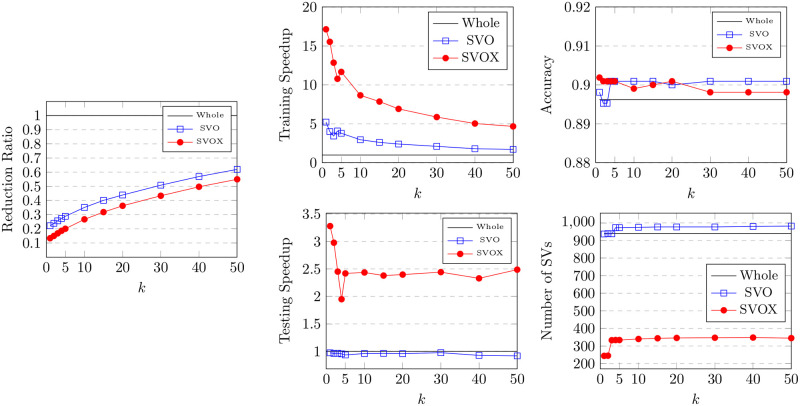
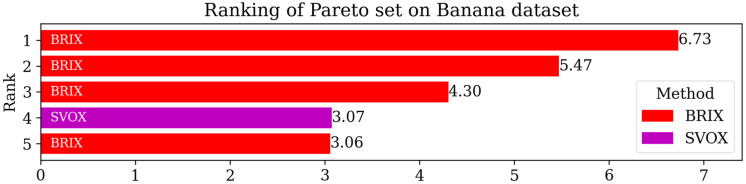
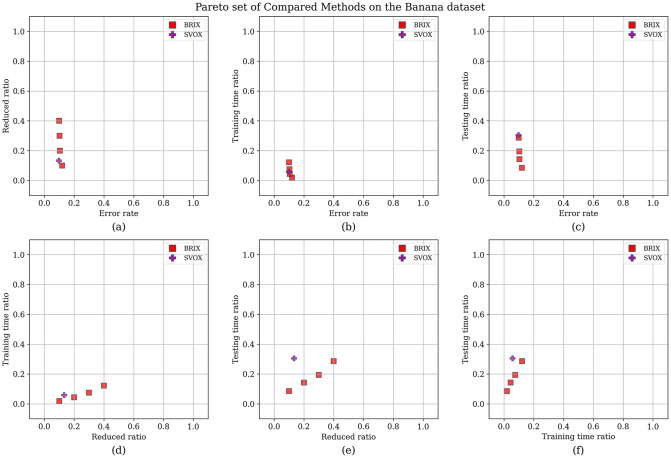
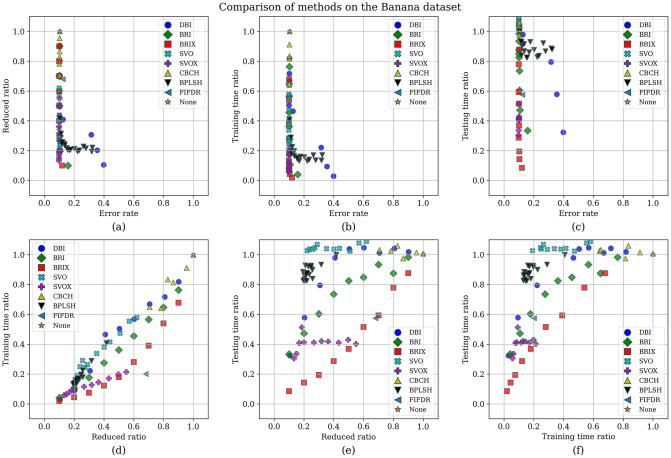
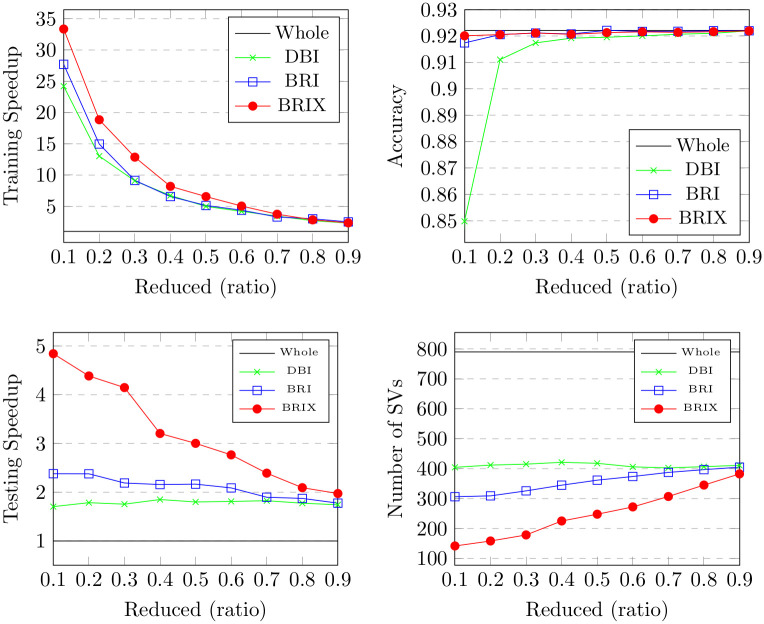
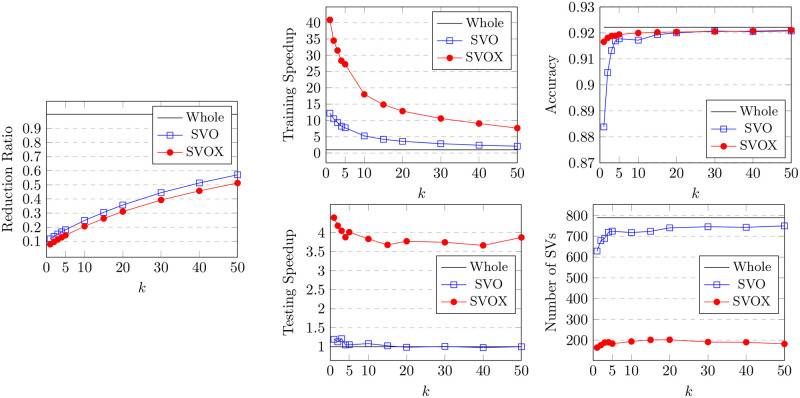
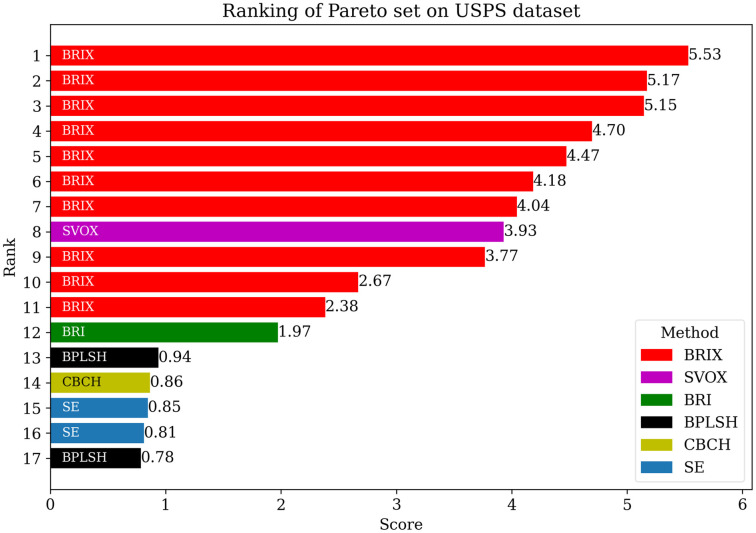
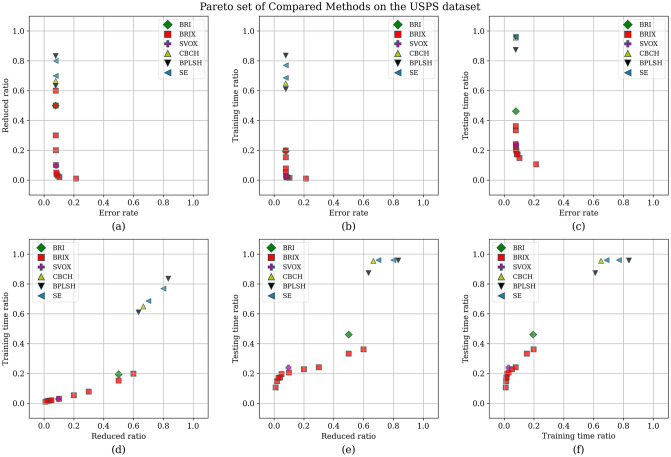
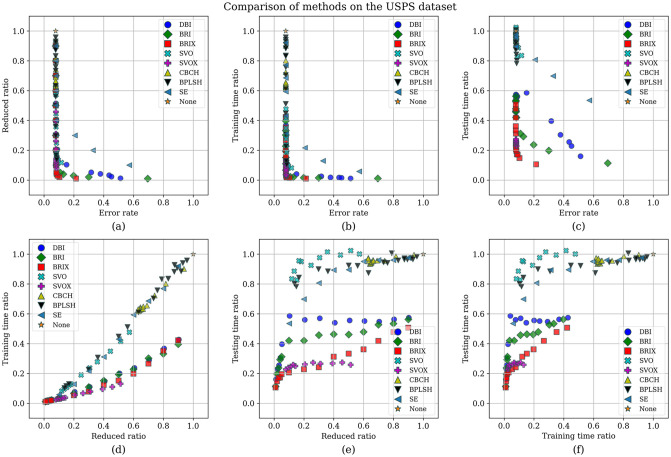
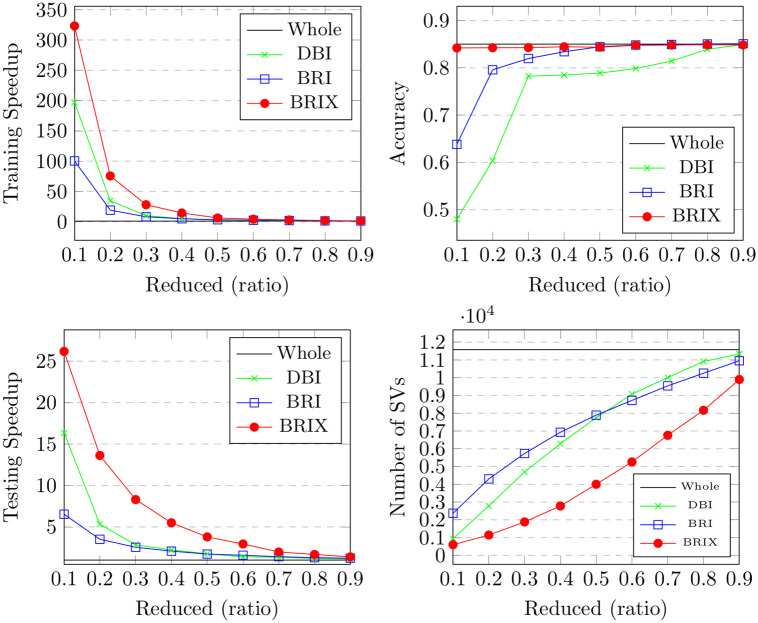
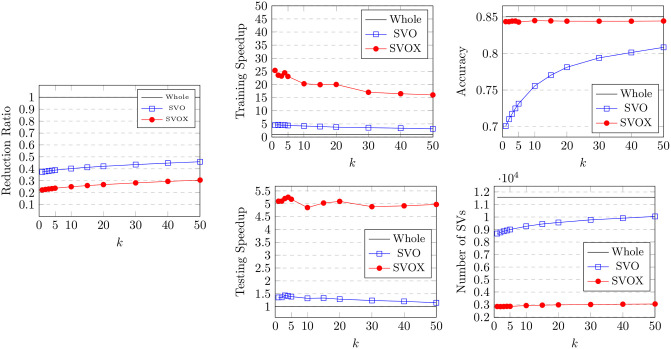
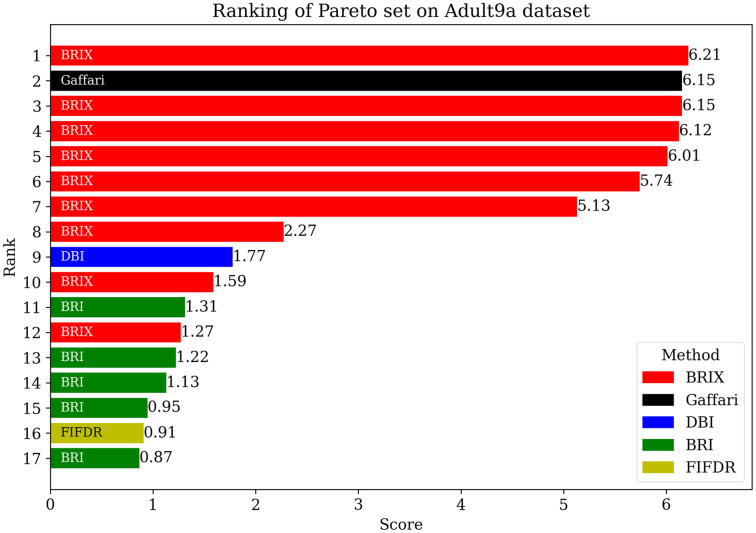
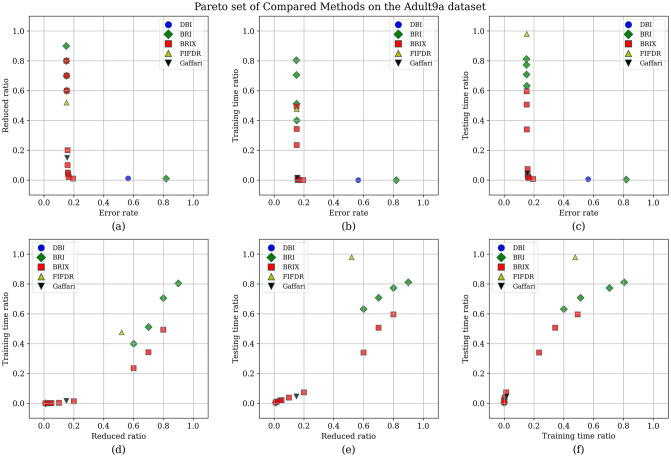
Numerous classification and regression problems have extensively used Support Vector Machines (SVMs). However, the SVM approach is less practical for large datasets because of its processing cost. This is primarily due to the requirement of optimizing a quadratic programming problem to determine the decision boundary during training. As a result, methods for selecting data instances that have a better likelihood of being chosen as support vectors by the SVM algorithm have been developed to help minimize the bulk of training data. This paper presents a density-based method, called Density-based Border Identification (DBI), in addition to four different variations of the method, for the lessening of the SVM training data through the extraction of a layer of border instances. For higher-dimensional datasets, the extraction is performed on lower-dimensional embeddings obtained by Uniform Manifold Approximation and Projection (UMAP), and the resulting subset can be repetitively used for SVM training in higher dimensions. Experimental findings on different datasets, such as Banana, USPS, and Adult9a, have shown that the best-performing variations of the proposed method effectively reduced the size of the training data and achieved acceptable training and prediction speedups while maintaining an adequate classification accuracy compared to training on the original dataset. These results, as well as comparisons to a selection of related state-of-the-art methods from the literature, such as Border Point extraction based on Locality-Sensitive Hashing (BPLSH), Clustering-Based Convex Hull (CBCH), and Shell Extraction (SE), suggest that our proposed methods are effective and potentially useful.
许多分类和回归问题都广泛使用了支持向量机(SVM)。然而,由于其处理成本,SVM 方法对于大型数据集来说不太实用。这主要是因为在训练过程中需要优化二次规划问题来确定决策边界。因此,已经开发了选择数据实例的方法,这些实例更有可能被 SVM 算法选为支持向量,以帮助最小化训练数据的大部分。本文提出了一种基于密度的方法,称为基于密度的边界识别(DBI),以及该方法的四种不同变体,用于通过提取边界实例层来减少 SVM 训练数据。对于高维数据集,提取是在通过均匀流形逼近和投影(UMAP)获得的低维嵌入上进行的,并且可以在更高维度上重复使用提取的子集进行 SVM 训练。在不同数据集(如 Banana、USPS 和 Adult9a)上的实验结果表明,所提出方法的性能最佳变体有效地减小了训练数据的大小,并实现了可接受的训练和预测加速,同时与在原始数据集上进行训练相比保持了足够的分类准确性。这些结果以及与文献中选择的一些相关最先进方法的比较,例如基于局部敏感哈希的边界点提取(BPLSH)、基于聚类的凸壳(CBCH)和外壳提取(SE),表明我们提出的方法是有效且可能有用的。