Department of Psychology, Rutgers University, Smith Hall, Room 301, 101 Warren Street, Newark, NJ, 07102, USA.
Georgetown University Medical Center, Washington, DC, USA.
Brain Struct Funct. 2024 Jun;229(5):1243-1263. doi: 10.1007/s00429-024-02800-9. Epub 2024 May 2.
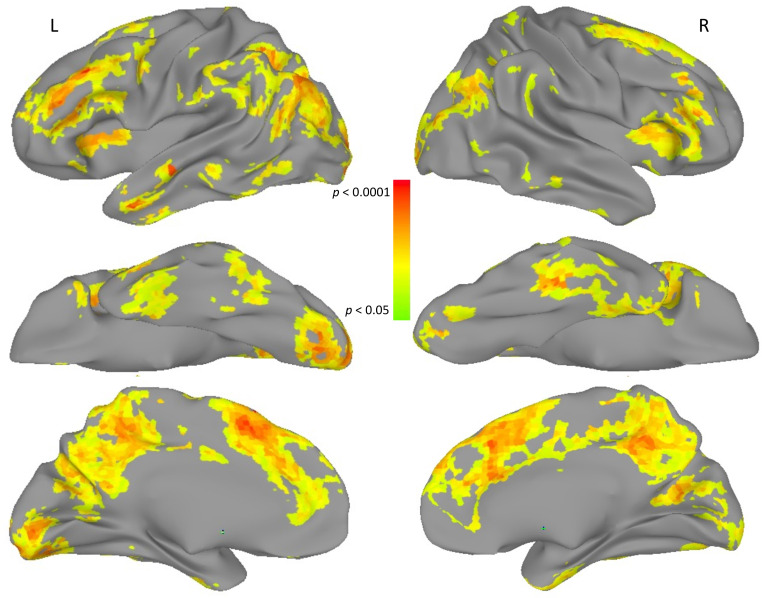
To determine how language is implemented in the brain, it is important to know which brain areas are primarily engaged in language processing and which are not. Existing protocols for localizing language are typically univariate, treating each small unit of brain volume as independent. One prominent example that focuses on the overall language network in functional magnetic resonance imaging (fMRI) uses a contrast between neural responses to sentences and sets of pseudowords (pronounceable nonwords). This contrast reliably activates peri-sylvian language areas but is less sensitive to extra-sylvian areas that are also known to support aspects of language such as word meanings (semantics). In this study, we assess areas where a multivariate, pattern-based approach shows high reproducibility across multiple measurements and participants, identifying these areas as multivariate regions of interest (mROI). We then perform a representational similarity analysis (RSA) of an fMRI dataset where participants made familiarity judgments on written words. We also compare those results to univariate regions of interest (uROI) taken from previous sentences > pseudowords contrasts. RSA with word stimuli defined in terms of their semantic distance showed greater correspondence with neural patterns in mROI than uROI. This was confirmed in two independent datasets, one involving single-word recognition, and the other focused on the meaning of noun-noun phrases by contrasting meaningful phrases > pseudowords. In all cases, areas of spatial overlap between mROI and uROI showed the greatest neural association. This suggests that ROIs defined in terms of multivariate reproducibility can help localize components of language such as semantics. The multivariate approach can also be extended to focus on other aspects of language such as phonology, and can be used along with the univariate approach for inclusively mapping language cortex.
为了确定语言在大脑中是如何实现的,了解哪些大脑区域主要参与语言处理,而哪些区域不参与语言处理非常重要。现有的定位语言的协议通常是单变量的,将每个小的脑体积单位视为独立的。一个突出的例子是在功能磁共振成像(fMRI)中关注整体语言网络的协议,它使用句子和一组伪词(可发音的非单词)的神经反应之间的对比。这种对比可靠地激活了围侧语言区,但对额外的侧区的敏感性较低,额外的侧区也被认为支持语言的某些方面,如词义(语义)。在这项研究中,我们评估了基于模式的多变量方法在多个测量和参与者中具有高度可重复性的区域,将这些区域确定为多变量感兴趣区域(mROI)。然后,我们对 fMRI 数据集执行了代表性相似性分析(RSA),其中参与者对书面单词进行了熟悉度判断。我们还将这些结果与以前的句子>伪词对比中提取的单变量感兴趣区域(uROI)进行了比较。使用单词刺激定义的语义距离进行 RSA 显示,与 mROI 中的神经模式的一致性大于 uROI。这在两个独立的数据集得到了证实,一个涉及单字识别,另一个通过对比有意义的短语>伪词来关注名词-名词短语的意义。在所有情况下,mROI 和 uROI 之间的空间重叠区域显示出最大的神经关联。这表明,基于多变量可重复性定义的 ROI 可以帮助定位语义等语言成分。多变量方法还可以扩展到关注语言的其他方面,如音韵学,并可以与单变量方法一起用于包容性地映射语言皮层。