Armah-Sekum Robert Ebo, Szedmak Sandor, Rousu Juho
Department of Computer Science, Aalto University, Konemiehentie 2, 02150, Espoo, Finland.
BMC Bioinformatics. 2024 May 2;25(1):174. doi: 10.1186/s12859-024-05789-4.
In last two decades, the use of high-throughput sequencing technologies has accelerated the pace of discovery of proteins. However, due to the time and resource limitations of rigorous experimental functional characterization, the functions of a vast majority of them remain unknown. As a result, computational methods offering accurate, fast and large-scale assignment of functions to new and previously unannotated proteins are sought after. Leveraging the underlying associations between the multiplicity of features that describe proteins could reveal functional insights into the diverse roles of proteins and improve performance on the automatic function prediction task.
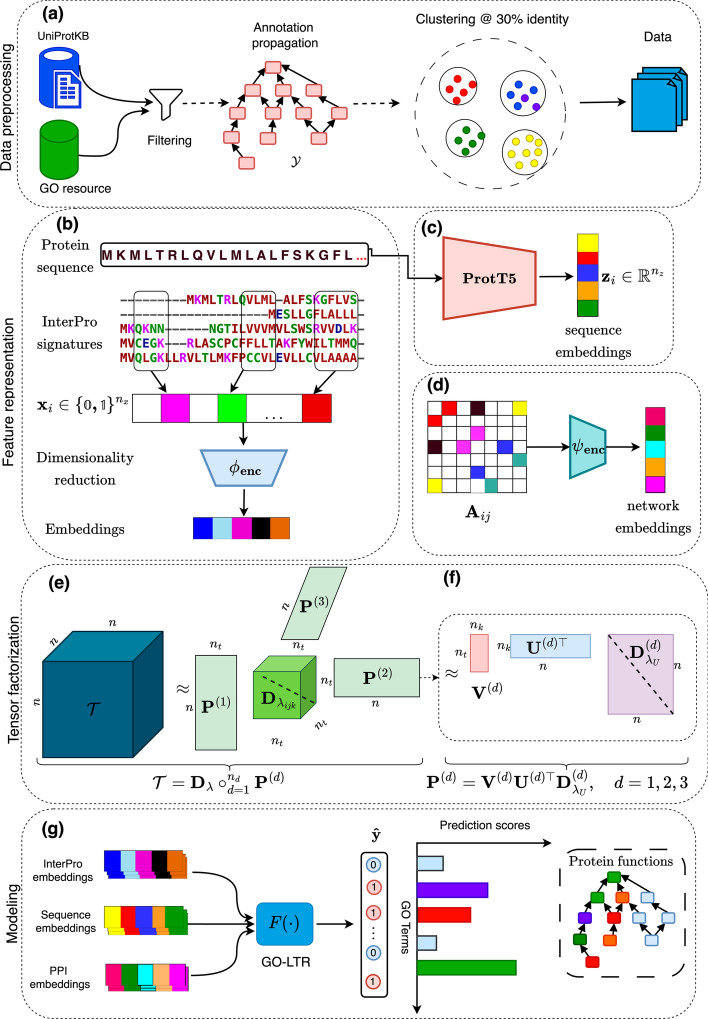
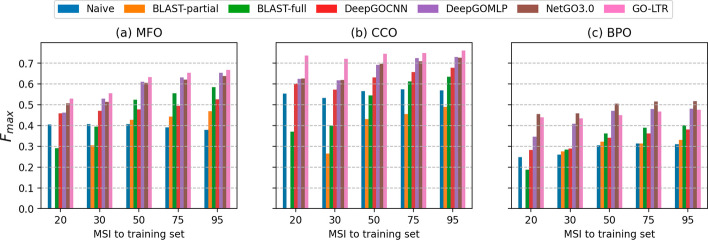
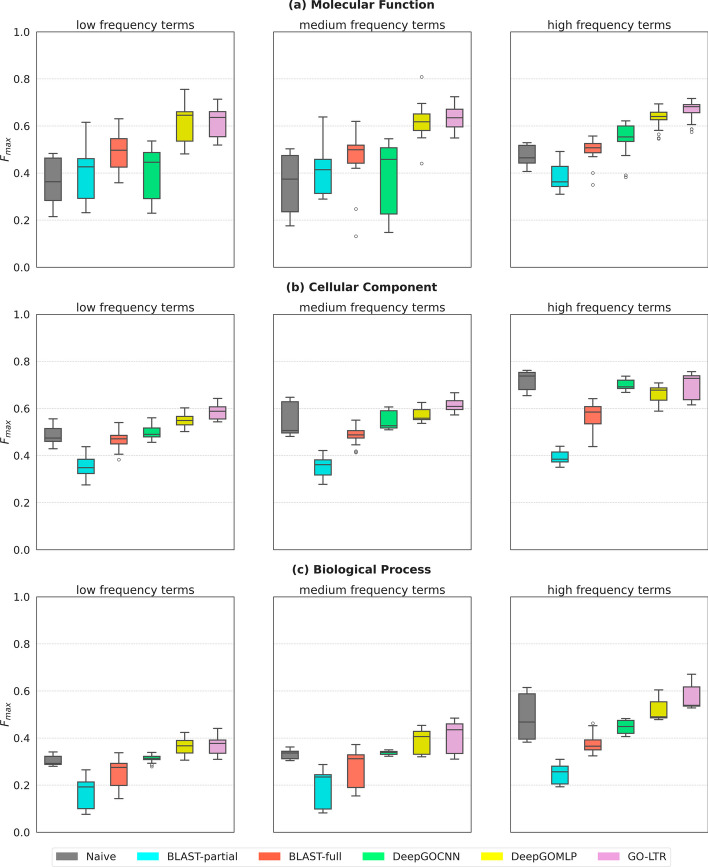
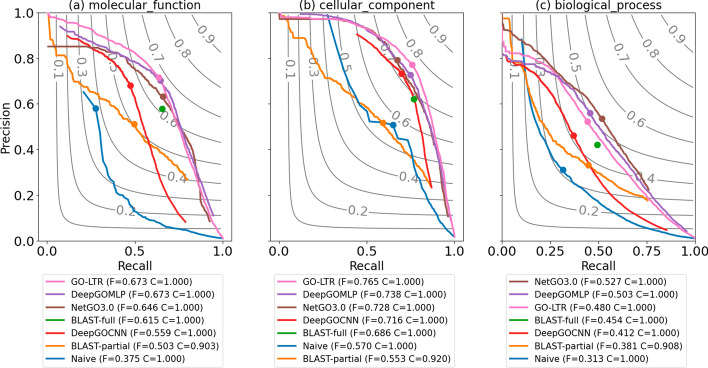
We present GO-LTR, a multi-view multi-label prediction model that relies on a high-order tensor approximation of model weights combined with non-linear activation functions. The model is capable of learning high-order relationships between multiple input views representing the proteins and predicting high-dimensional multi-label output consisting of protein functional categories. We demonstrate the competitiveness of our method on various performance measures. Experiments show that GO-LTR learns polynomial combinations between different protein features, resulting in improved performance. Additional investigations establish GO-LTR's practical potential in assigning functions to proteins under diverse challenging scenarios: very low sequence similarity to previously observed sequences, rarely observed and highly specific terms in the gene ontology.
The code and data used for training GO-LTR is available at https://github.com/aalto-ics-kepaco/GO-LTR-prediction .
在过去二十年中,高通量测序技术的应用加快了蛋白质发现的步伐。然而,由于严格的实验功能表征在时间和资源上的限制,绝大多数蛋白质的功能仍然未知。因此,人们寻求能够为新的和以前未注释的蛋白质提供准确、快速且大规模功能分配的计算方法。利用描述蛋白质的多种特征之间的潜在关联,可以揭示蛋白质不同作用的功能见解,并提高自动功能预测任务的性能。
我们提出了GO-LTR,这是一种多视图多标签预测模型,它依赖于模型权重的高阶张量近似与非线性激活函数相结合。该模型能够学习代表蛋白质的多个输入视图之间的高阶关系,并预测由蛋白质功能类别组成的高维多标签输出。我们在各种性能指标上证明了我们方法的竞争力。实验表明,GO-LTR学习不同蛋白质特征之间的多项式组合,从而提高了性能。进一步的研究确立了GO-LTR在各种具有挑战性的场景下为蛋白质分配功能的实际潜力:与先前观察到的序列具有非常低的序列相似性、在基因本体中很少观察到且高度特异的术语。
用于训练GO-LTR的代码和数据可在https://github.com/aalto-ics-kepaco/GO-LTR-prediction获取。