Hwang Jeongin, Choi Kyeong-Ok, Jeong Sungmin, Lee Suyong
Department of Food Science and Biotechnology, Seoul, 05006, South Korea.
Department of Food Science and Technology, Chungnam National University, Daejeon, 34134, South Korea.
Curr Res Food Sci. 2024 Apr 20;8:100742. doi: 10.1016/j.crfs.2024.100742. eCollection 2024.
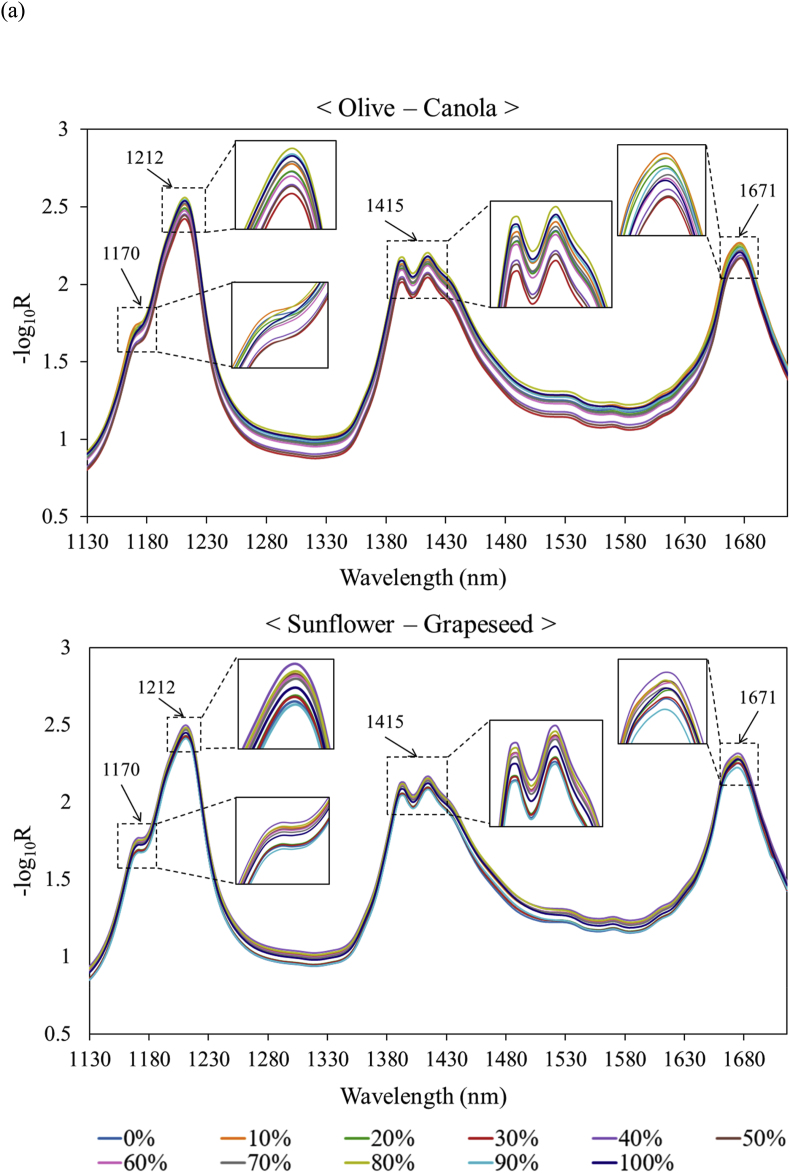
Hyperspectral imaging analysis combined with machine learning was applied to identify eight edible vegetable oils, and its classification performance was compared with the chemical method based on fatty acid compositions. Furthermore, the degree of adulteration in vegetable oils was quantitatively investigated using machine learning-enabled hyperspectral approaches. The hyperspectral absorbance spectra of palm oil with a high degree of saturation were distinctly different from those of the other liquid oils. The flaxseed and olive oils exhibited the dominant hyperspectral intensities at 1170/1671 and 1212/1415 nm, respectively. Linear discriminant analysis demonstrated that two linear discriminants could explain a significant portion of the total variability, accounting for 96.0% (fatty acid compositions) and 98.9% (hyperspectral images). When the hyperspectral results were used as datasets for three machine learning models (decision tree, random forest, and k-nearest neighbor), several instances to incorrectly classify grapeseed and sunflower oils were detected, while olive, palm, and flaxseed oils were successfully identified. The machine learning models showed a great classification performance that exceeded 98.9% from the hyperspectral images of the vegetable oils, which was comparable to the fatty acid composition-based chemical method in identifying edible vegetable oils. In addition, the random forest model was the most effective in ascertaining adulteration levels in binary oil blends (R > 0.992 and RMSE < 2.75).
将高光谱成像分析与机器学习相结合,用于识别八种食用植物油,并将其分类性能与基于脂肪酸组成的化学方法进行比较。此外,还使用基于机器学习的高光谱方法对植物油的掺假程度进行了定量研究。饱和度高的棕榈油的高光谱吸收光谱与其他液体油的光谱明显不同。亚麻籽和橄榄油分别在1170/1671和1212/1415纳米处呈现出占主导地位的高光谱强度。线性判别分析表明,两个线性判别式可以解释总变异性的很大一部分,分别占96.0%(脂肪酸组成)和98.9%(高光谱图像)。当将高光谱结果用作三种机器学习模型(决策树、随机森林和k近邻)的数据集时,检测到几例对葡萄籽油和葵花籽油分类错误的情况,而橄榄油、棕榈油和亚麻籽油则被成功识别。机器学习模型显示出了出色的分类性能,从植物油的高光谱图像中分类准确率超过98.9%,这与基于脂肪酸组成的化学方法在识别食用植物油方面相当。此外,随机森林模型在确定二元混合油的掺假水平方面最为有效(R>0.992且RMSE<2.75)。